




Sind Videospiele der ultimative KI-Benchmark?
Jahrelang stützte sich die Bewertung von KI-Modellen auf Benchmarks wie MMLU, Chatbot Arena und SWE-Bench Verified. Doch mit der Entwicklung der KI stellen selbst Experten wie Andrej Karpathy diese Methoden infrage.
Seine neueste Sorge? KI-Benchmarks verlieren an Zuverlässigkeit – und die Lösung für bessere Evaluierungen könnte in Videospielen liegen.
Schließlich hat KI eine lange Geschichte in Games. DeepMinds AlphaGo veränderte die Welt durch den Sieg gegen Go-Champions. OpenAI dominierte Dota 2 und bewies, dass KI menschliche Spieler in Strategiespielen übertrumpfen kann. 
Jetzt gehen Forscher des Hao KI-Labors der UC San Diego noch weiter. Sie entwickelten einen Open-Source-“Gaming Agent”, der große Sprachmodelle (LLMs) in Echtzeit-Puzzlespielen testet – beginnend mit Super Mario Bros..
Die Ergebnisse? Claude 3.7 spielte volle 90 Sekunden – und zerstörte dabei OpenAIs GPT-4o, das fast sofort scheiterte.
Claude 3.7 übertrifft OpenAI und Google in Super Mario
Das Open-Source-Projekt GamingAgent ermöglicht KI-Modellen, Spielfiguren via natürlicher Sprache zu steuern.
🔹 Claude 3.7 Sonnet überlebte beeindruckende 90 Sekunden.
🔹 GPT-4o scheiterte nach 20 Sekunden – besiegt vom ersten Gegner!
🔹 Googles Gemini 1.5 Pro und Gemini 2.0 versagten kläglich, selbst bei Basics.
GPT-4o: Die KI, die nicht springen kann
Stellt euch einen Spieler vor, der innerhalb von Sekunden stirbt. Das ist GPT-4o in Super Mario.
- 💀 Erster Versuch: Vom ersten Gegner eliminiert wie ein Anfänger.

- 💀 Zweiter Versuch: Kaum Fortschritt, blieb alle zwei Schritte stehen.

- 💀 Dritter Versuch: Bleibt 10 Sekunden in einem Rohr stecken bevor es stirbt.

Für ein KI-Modell mit fortgeschrittener Logik war GPT-4os Leistung erschreckend schlecht.
Googles Gemini: Die “Zwei-Schritte-Sprung”-Strategie
Gemini 1.5 Pro scheiterte ebenfalls am ersten Gegner. Beim zweiten Versuch verbesserte es sich leicht – traf einen ?-Block und sammelte einen Super-Pilz.
Doch es entwickelte eine seltsame Angewohnheit: Sprang alle zwei Schritte – egal ob nötig oder nicht.
- 🚀 9 Sprünge auf kurzer Distanz

- 🚀 Hüpfte über Rohre, Boden und leere Flächen

- 🚀 Kam weiter als GPT-4o, stürzte aber in eine Grube

Gemini 2.0 Flash war etwas besser, sprang flüssiger und erreichte ein höheres Plateau. Scheiterte aber an einer Grube beim vierten Rohr.
Claude 3.7: Das Super Mario-Wunderkind?
Anders als OpenAI und Google spielte Claude 3.7 wie ein echter Gamer.
- ✔ Sprang nur bei Bedarf (für Hindernisse/Lücken)

- ✔ Wich Gegnern durch präzise Sprünge aus

- ✔ Entdeckte einen versteckten Stern-Power-up!
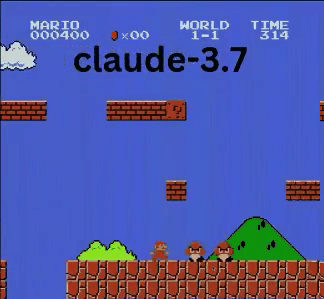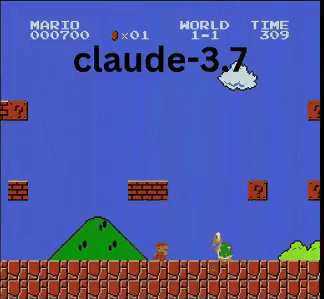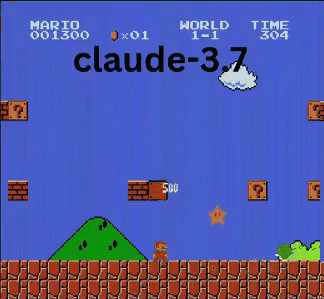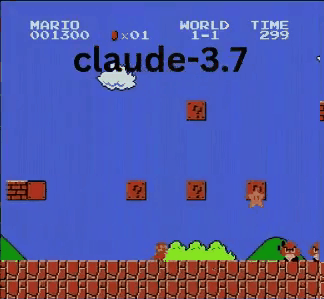
- ✔ Erreichte den weitesten Punkt aller getesteten KIs
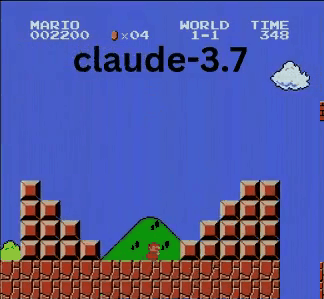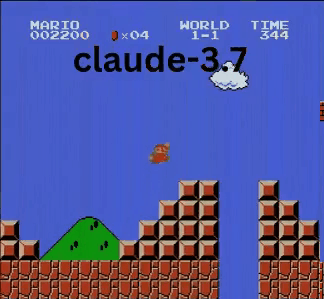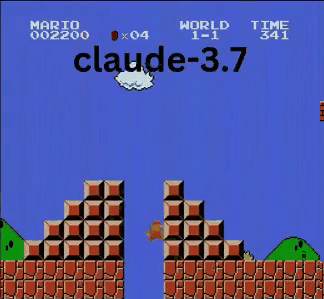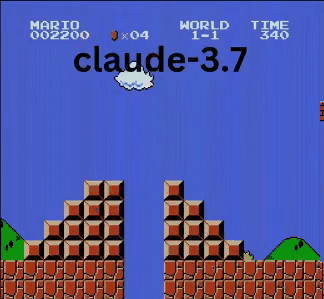
Claude 3.7 übertraf sogar Gemini 2.0 Flash. Während Gemini an einer Grube scheiterte, meisterte Claude diese, sammelte Extra-Münzen und bekämpfte neue Gegner wie Koopa-Troopas.
Kann KI komplexere Spiele meistern?
Mario ist nicht der einzige Test. Die Forscher evaluierten KIs auch in Tetris und 2048 – zwei Strategiespielen.
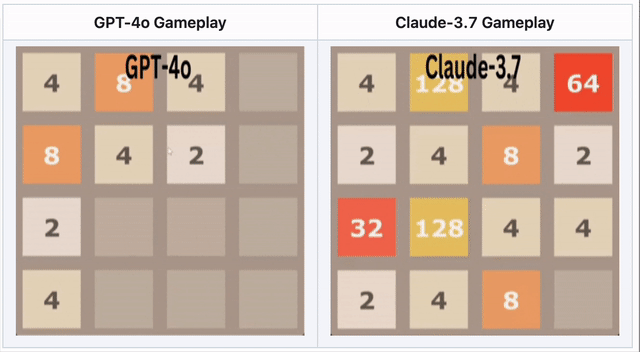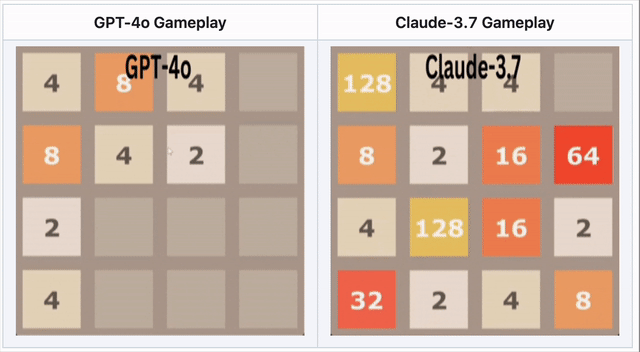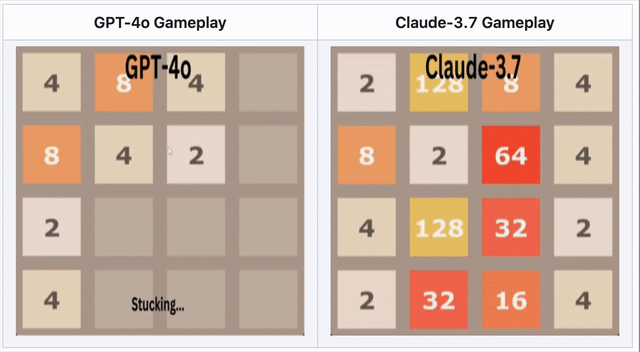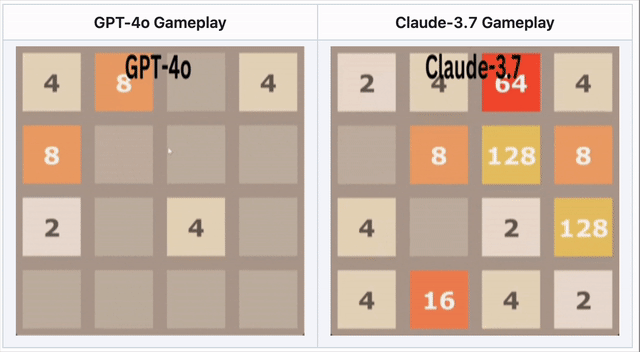
GPT-4o scheitert bei 2048 – Claude 3.7 glänzt
Im Zahlenpuzzle 2048 musste die KI Kacheln verschieben und strategisch mergen.
🔹 GPT-4o scheiterte früh durch Überanalysieren.
🔹 Claude 3.7 überlebte länger mit cleveren Merges.
🔹 Kein Modell gewann – aber Claude war besser.
Claude 3.7s Tetris-Skills beeindrucken Experten
In Tetris zeigte Claude 3.7:
✔ Gute Stacking-Strategien
✔ Effektives Lösen von Reihen
✔ Längeres Überleben als andere KIs
Anthropics Alex Albert lobte:
“Jedes Videospiel sollte ein KI-Benchmark werden!”
Sind Spiele die Zukunft der KI-Evaluierung?
Die Ergebnisse legen nahe: Videospiele könnten der nächste große KI-Benchmark werden. Anders als statische Tests erfordern Games Echtzeit-Entscheidungen, Anpassungsfähigkeit und Motorik.
Da KI-Modelle rasant fortschreiten, reichen traditionelle Benchmarks vielleicht nicht mehr aus. Falls sich Gaming als besserer Maßstab erweist, könnten KIs zukünftig mit Reinforcement Learning an tausenden Spielen trainiert werden.
Fazit: Claude gewinnt diese Runde – doch was kommt?
Claude 3.7s überlegene Spielskills deuten auf stärkere Logik und Anpassungsfähigkeit hin. Doch welche KI wird als erste ein komplettes Spiel wie ein Mensch meistern?
Mit Open-Source-Gaming-Agents erwarten uns bald mehr KI-vs-Game-Schlachten. Wer weiß? Vielleicht schafft eine KI bald Super Mario fehlerfrei – oder besiegt sogar eSport-Profis.
Bis dahin bleibt Claude der ungekrönte KI-Gaming-König – während GPT-4o dringend Trainingsstunden braucht!









