


A big problem within the discipline of synthetic intelligence, significantly in generative modeling, is knowing how diffusion fashions can successfully study and generate high-dimensional information distributions. Regardless of their empirical success, the theoretical mechanisms that allow diffusion fashions to keep away from the curse of dimensionality—the place the variety of required samples will increase exponentially with information dimension—stay poorly understood. Addressing this problem is essential for advancing generative fashions in AI, significantly for purposes in picture technology, the place the flexibility to effectively study from high-dimensional information is paramount.
Present strategies for studying high-dimensional information distributions, significantly via diffusion fashions, contain estimating the rating perform, which is the gradient of the logarithm of the likelihood density perform. These fashions usually function via a two-step course of: first, incrementally including Gaussian noise to the info, after which progressively eradicating this noise by way of a reverse course of to approximate the info distribution. Whereas these strategies have achieved vital empirical success, they battle to clarify why diffusion fashions require fewer samples than theoretically anticipated to precisely study complicated information distributions. Moreover, these fashions typically face points with over-parameterization, resulting in memorization moderately than generalization, which limits their applicability to broader real-world situations.

Researchers from the College of Michigan and the College of California current a novel strategy that fashions the underlying information distribution as a mix of low-rank Gaussians (MoLRG). This technique is motivated by key empirical observations: the low intrinsic dimensionality of picture information, the manifold construction of picture information as a union of manifolds, and the low-rank nature of the denoising autoencoder in diffusion fashions. By parameterizing the denoising autoencoder as a low-rank mannequin, it’s proven that optimizing the coaching lack of diffusion fashions is equal to fixing a subspace clustering drawback. This revolutionary framework addresses the shortcomings of present strategies by offering a theoretical rationalization for the effectivity of diffusion fashions in high-dimensional areas, demonstrating that the variety of required samples scales linearly with the intrinsic dimension of the info. This contribution represents a major development in understanding the generalization capabilities of diffusion fashions.

The information distribution is modeled as a mix of low-rank Gaussians, with information factors generated from a number of Gaussian distributions characterised by zero imply and low-rank covariance matrices. A key technical innovation lies within the parameterization of the denoising autoencoder (DAE), which is expressed as:
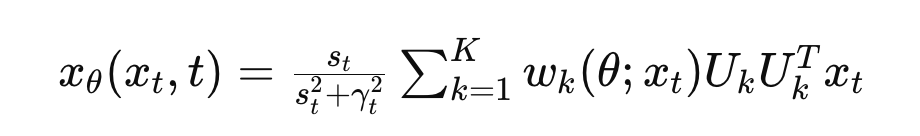
Right here, Uk represents orthonormal foundation matrices for every Gaussian part, and the weights wk(θ;xt) are soft-max features based mostly on the projection of xt onto the subspaces outlined by Uk. This low-rank parameterization successfully captures the intrinsic low-dimensionality of the info, permitting the diffusion mannequin to effectively study the underlying distribution. Empirical validation is supplied via experiments on artificial and actual picture datasets, the place the DAE displays constant low-rank properties, reinforcing the theoretical assumptions.
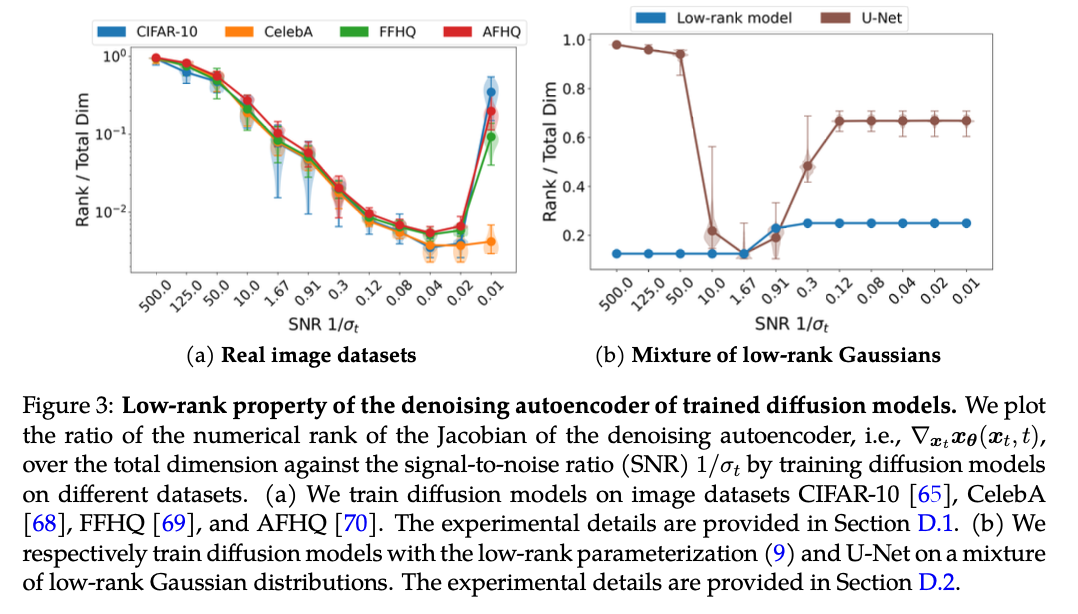
The strategy demonstrates its effectiveness in studying high-dimensional information distributions whereas overcoming the curse of dimensionality. By modeling the info as a mix of low-rank Gaussians, the strategy effectively captures the underlying distribution, requiring numerous samples that scales linearly with the info’s intrinsic dimension. Experimental validation reveals vital enhancements in accuracy and pattern effectivity throughout varied datasets. The mannequin constantly generalizes nicely past the coaching information, attaining a excessive generalization rating, which signifies profitable studying of the true distribution moderately than mere memorization. These outcomes spotlight the robustness and effectivity of the mannequin in coping with complicated, high-dimensional information, marking a priceless contribution to AI analysis.
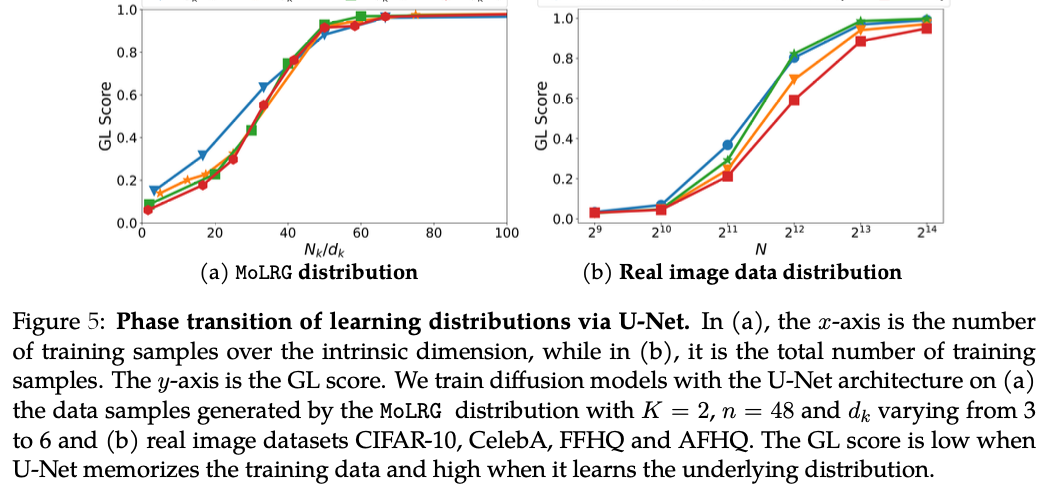
This analysis makes a major contribution to AI by offering a theoretical framework that explains how diffusion fashions can effectively study high-dimensional information distributions. The researchers tackle the core problem of avoiding the curse of dimensionality by modeling the info distribution as a mix of low-rank Gaussians and parameterizing the denoising autoencoder to seize the info’s low-dimensional construction. In depth experiments validate the strategy, demonstrating that it could actually study the underlying distribution with numerous samples that scale linearly with the intrinsic dimension. This work affords a strong rationalization for the empirical success of diffusion fashions and suggests a path ahead for growing extra environment friendly and scalable generative fashions in AI analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be part of our Telegram Channel.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


