


Transformers have been the inspiration of enormous language fashions (LLMs), and just lately, their software has expanded to look issues in graphs, a foundational area in computational logic, planning, and AI. Graph search is integral to fixing duties requiring systematically exploring nodes and edges to seek out connections or paths. Regardless of transformers’ obvious adaptability, their capacity to effectively carry out graph search stays an open query, particularly when scaling to complicated and enormous datasets.
Graphs provide a method to current complicated knowledge, however they arrive with challenges in contrast to others. In graph search duties, the structured nature of the information and the computational calls for required to discover paths between nodes make it difficult and require environment friendly algorithms. Particularly Massive-scale graphs amplify this complexity, requiring algorithms to navigate exponentially rising search areas. Present transformer architectures show restricted success, usually counting on heuristic approaches that compromise their robustness and generalizability. The problem will increase with graph measurement as transformers should determine patterns or algorithms that work universally throughout datasets. This limitation raises considerations about their scalability and capability to generalize to numerous search situations.
Makes an attempt to handle these limitations have primarily targeted on leveraging chain-of-thought prompting and related strategies, enabling fashions to interrupt down duties into incremental steps. Whereas this strategy is promising for smaller and fewer complicated graphs, it falls brief for bigger graphs with extra intricate connectivity patterns. Additionally, rising mannequin parameters or including extra coaching knowledge doesn’t constantly enhance efficiency. For instance, even with subtle prompting strategies, transformers exhibit errors and inefficiencies when figuring out the proper path in expansive graph constructions. These challenges want a shift in how transformers are skilled and optimized for graph search duties.
In a current examine, researchers from Purdue College, New York College, Google, and Boston College launched a coaching framework to boost transformers’ graph search capabilities. To make sure complete coaching protection, the researchers employed an revolutionary technique utilizing directed acyclic graphs (DAGs) as a testbed and balanced knowledge distributions. By designing datasets that discouraged reliance on heuristics, the workforce aimed to allow transformers to study sturdy algorithms. The coaching concerned systematically producing examples with various ranges of complexity because it allowed the mannequin to progressively construct its understanding of graph connectivity.
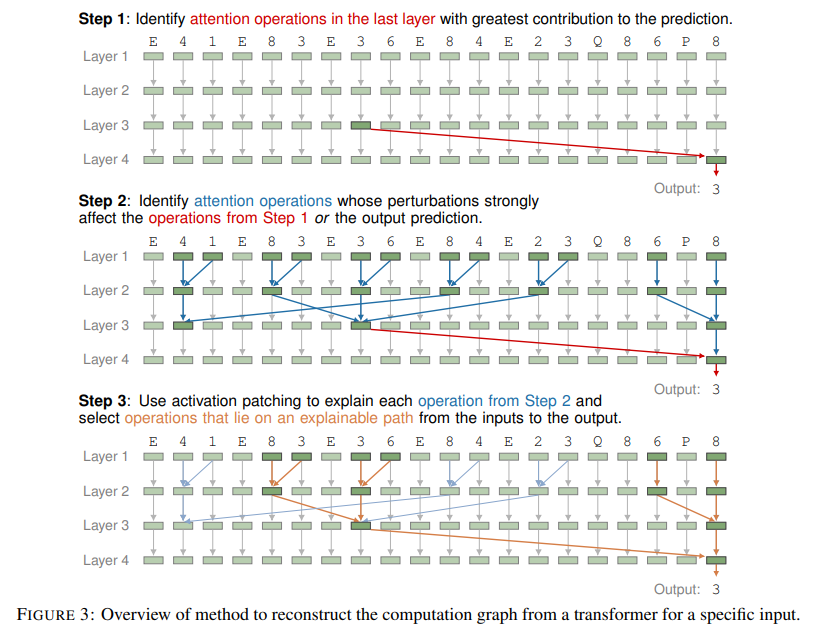
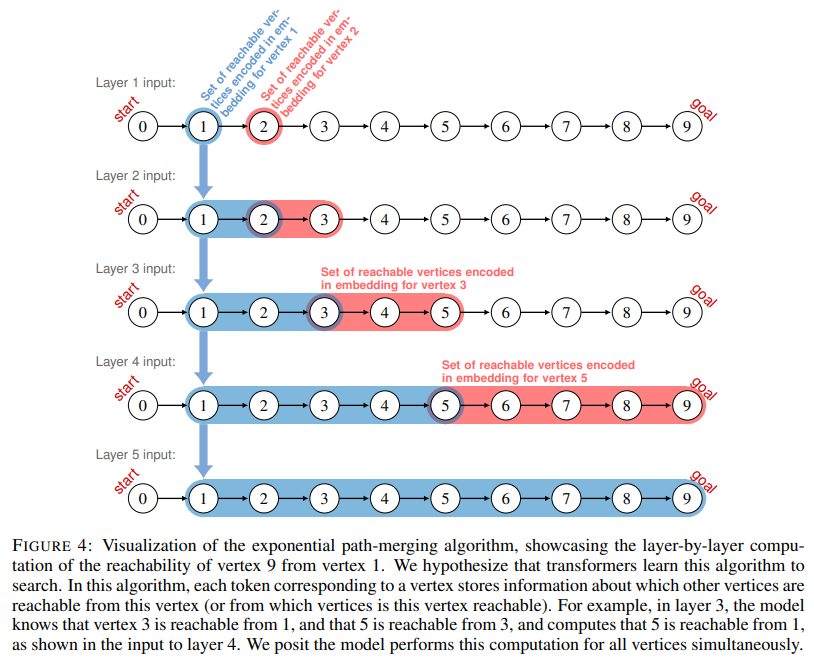
The coaching methodology targeted on a balanced distribution of graphs, guaranteeing uniform illustration of situations with completely different lookaheads (lookahead refers back to the variety of steps a mannequin should search to attach the beginning vertex to the objective vertex in a graph) and the variety of steps required to discover a path between two nodes. The transformers had been skilled to compute units of reachable vertices exponentially, layer by layer, successfully simulating an “exponential path-merging” algorithm. This system allowed the embeddings to encode detailed details about connectivity, enabling the mannequin to discover paths systematically. The researchers analyzed the transformers’ inside operations utilizing mechanistic interpretability strategies to validate this strategy. By reconstructing computation graphs, they demonstrated how consideration layers aggregated and processed info to determine paths in DAGs.
The outcomes of the examine had been a mixture of some positives and negatives. Transformers skilled on the balanced distribution achieved near-perfect accuracy for small graphs, even with lookaheads extending to 12 steps. Nonetheless, efficiency declined considerably as graph sizes elevated. As an illustration, fashions skilled on graphs with lookahead constraints of as much as 12 struggled to generalize to bigger lookaheads past this vary. Accuracy on bigger graphs dropped beneath 50% for lookaheads exceeding 16 steps. With an enter measurement of 128 tokens and a 6-layer structure, transformers couldn’t reliably deal with expansive graphs. The examine additionally highlighted that scaling mannequin measurement didn’t resolve these points. Bigger fashions confirmed no constant enchancment in dealing with complicated search duties, underscoring the inherent limitations of the transformer structure.
The researchers additionally explored alternate strategies, akin to depth-first search (DFS) and selection-inference prompting, to guage whether or not intermediate steps might improve efficiency. Whereas these approaches simplified sure duties, they wanted to basically enhance the transformers’ capacity to deal with bigger graph sizes. The fashions struggled with graphs exceeding 45 vertices, even when skilled on distributions designed to emphasise exploration. Additionally, rising the dimensions of coaching knowledge or the variety of parameters didn’t result in substantial good points, emphasizing that greater than conventional scaling methods are required to beat these challenges.
Among the key takeaways from the analysis embody the next:
- Fashions skilled on balanced distributions that eradicated reliance on shortcuts outperformed these skilled on naive or heuristic-driven datasets. This discovering underscores the significance of rigorously curating coaching knowledge to make sure sturdy studying.
- The researchers recognized the “exponential path-merging” algorithm as a key course of by analyzing transformers’ inside workings. This understanding might information future architectural enhancements and coaching methodologies.
- The fashions exhibited rising problem as graph sizes grew, with accuracy declining considerably for bigger lookaheads and graphs past 31 nodes.
- Growing mannequin parameters or the dimensions of coaching datasets didn’t resolve the restrictions, indicating that architectural adjustments or novel coaching paradigms are essential.
- Alternate architectures, akin to looped transformers, and superior coaching strategies, like curriculum studying, could provide potential options. Integrating mechanistic insights might additionally result in higher algorithmic understanding and scalability.

In conclusion, this analysis comprehensively analyzes transformers’ capabilities and limitations in performing graph search duties. By demonstrating the effectiveness of tailor-made coaching distributions and uncovering the inner algorithms utilized by the fashions, the examine provides helpful insights into transformers’ computational conduct. Nonetheless, the challenges of scaling to bigger graphs and reaching sturdy generalization spotlight the necessity for revolutionary approaches. These findings emphasize the necessity for alternate architectures or superior coaching approaches to boost scalability and robustness in graph-based reasoning duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our publication to get trending AI analysis and dev updates
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

 Actual Chat: Jania Stout")
