


Latest developments in generative language modeling have propelled pure language processing, making it doable to create contextually wealthy and coherent textual content throughout numerous functions. Autoregressive (AR) fashions generate textual content in a left-to-right sequence and are broadly used for duties like coding and sophisticated reasoning. Nonetheless, these fashions face limitations as a result of their sequential nature, which makes them susceptible to error accumulation with every step. The reliance on a strict order for producing tokens can prohibit flexibility in sequence era. To sort out these drawbacks, researchers have began exploring various strategies, notably those who enable parallel era, enabling textual content to be created extra simply and effectively.
A important problem in language modeling is the progressive error accumulation inherent in autoregressive approaches. As every generated token instantly will depend on the previous ones, minor preliminary errors can result in important deviations, impacting the standard of the generated textual content and decreasing effectivity. Addressing these points is essential, as error buildup decreases accuracy and limits AR fashions’ usability for real-time functions that demand high-speed and dependable output. Subsequently, researchers are investigating parallel textual content era to retain excessive efficiency whereas mitigating errors. Though parallel era fashions have proven promise, they usually have to match the detailed contextual understanding achieved by conventional AR fashions.
Presently, discrete diffusion fashions stand out as an rising answer for parallel textual content era. These fashions generate complete sequences concurrently, providing important pace advantages. Discrete diffusion fashions begin from a completely masked sequence and progressively uncover tokens in a non-sequential method, permitting for bidirectional textual content era. Regardless of this functionality, present diffusion-based approaches face limitations as a result of their reliance on impartial token predictions, which overlook the dependencies between tokens. This independence usually ends in decreased accuracy and the necessity for a number of sampling steps, resulting in inefficiencies. Whereas different fashions try to bridge the hole between high quality and pace, most need assistance to succeed in the accuracy and fluency offered by autoregressive setups.
Researchers from Stanford College and NVIDIA launched the Vitality-based Diffusion Language Mannequin (EDLM). EDLM represents an revolutionary method that mixes energy-based modeling with discrete diffusion to sort out the inherent challenges of parallel textual content era. By integrating an power perform at every stage of the diffusion course of, EDLM seeks to right inter-token dependencies, thus enhancing the sequence’s high quality and sustaining the benefits of parallel era. The power perform permits the mannequin to be taught dependencies inside the sequence by leveraging both a pretrained autoregressive mannequin or a bidirectional transformer fine-tuned by means of noise contrastive estimation. EDLM’s structure, subsequently, merges the effectivity of diffusion with the sequence coherence typical of energy-based strategies, making it a pioneering mannequin within the discipline of language era.
The EDLM framework entails an in-depth methodology centered on introducing an power perform that dynamically captures correlations amongst tokens all through the era course of. This power perform operates as a corrective mechanism inside every diffusion step, successfully addressing the challenges related to token independence in different discrete diffusion fashions. By adopting a residual kind, the power perform allows EDLM to refine predictions iteratively. The energy-based framework operates on pretrained autoregressive fashions, which permits EDLM to bypass the necessity for optimum chance coaching—a usually pricey course of. As a substitute, the mannequin’s power perform operates instantly on the sequence, permitting EDLM to conduct environment friendly parallel sampling by means of significance sampling, additional enhancing the mannequin’s accuracy. This environment friendly sampling methodology reduces decoding errors by optimizing the token dependency mechanism, setting EDLM aside from different diffusion-based strategies.
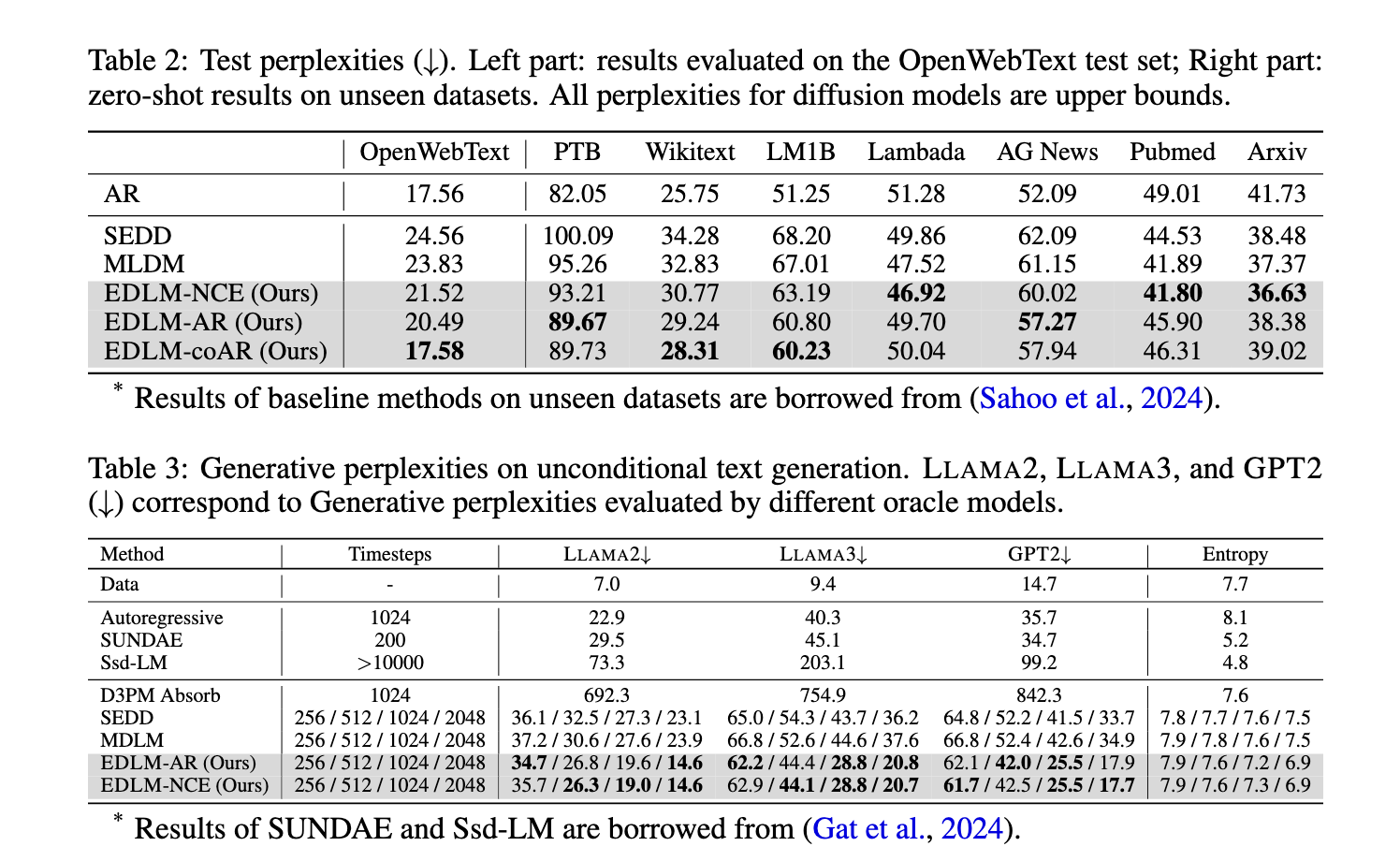
Efficiency evaluations of EDLM reveal substantial enhancements in pace and high quality of textual content era. In trials towards different fashions on language benchmarks, EDLM confirmed an as much as 49% discount in generative perplexity, marking a major advance within the accuracy of textual content era. Additional, EDLM demonstrated a 1.3x speedup in sampling in comparison with standard diffusion fashions, all with out sacrificing efficiency. Benchmark checks additional indicated that EDLM approaches the perplexity ranges usually achieved by autoregressive fashions whereas sustaining the effectivity advantages inherent to parallel era. For example, in a comparability utilizing the Text8 dataset, EDLM achieved the bottom bits-per-character rating amongst examined fashions, highlighting its superior skill to take care of textual content coherence with fewer decoding errors. Moreover, on the OpenWebText dataset, EDLM outperformed different state-of-the-art diffusion fashions, reaching aggressive efficiency even towards sturdy autoregressive fashions.
In conclusion, EDLM’s novel method efficiently addresses longstanding points associated to sequential dependency and error propagation in language era fashions. By successfully combining energy-based corrections with the parallel capabilities of diffusion fashions, EDLM introduces a mannequin that gives each accuracy and enhanced pace. This innovation by researchers from Stanford and NVIDIA demonstrates that energy-based approaches can play a vital position within the evolution of language fashions, offering a promising various to autoregressive strategies for functions requiring excessive efficiency and effectivity. EDLM’s contributions lay the groundwork for extra adaptable, contextually conscious language fashions that may obtain each accuracy and effectivity, underscoring the potential of energy-based frameworks in advancing generative textual content applied sciences.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


