


Massive language fashions (LLMs) have turn into a pivotal a part of synthetic intelligence, enabling techniques to know, generate, and reply to human language. These fashions are used throughout numerous domains, together with pure language reasoning, code era, and problem-solving. LLMs are often educated on huge quantities of unstructured information from the web, permitting them to develop broad language understanding. Nevertheless, fine-tuning is required to make them extra task-specific and align them with human intent. Tremendous-tuning entails utilizing instruction datasets that include structured question-response pairs. This course of is important to enhancing the fashions’ capability to carry out precisely in real-world purposes.
The rising availability of instruction datasets presents a key problem for researchers: effectively choosing a subset of information that enhances mannequin coaching with out exhausting computational assets. With datasets reaching a whole bunch of hundreds of samples, it’s troublesome to find out which subset is perfect for coaching. This downside is compounded by the truth that some information factors contribute extra considerably to the training course of than others. Greater than merely counting on information high quality is required. As a substitute, there must be a stability between information high quality and variety. Prioritizing variety within the coaching information ensures that the mannequin can generalize successfully throughout numerous duties, stopping overfitting to particular domains.
Present information choice strategies sometimes deal with native options similar to information high quality. For instance, conventional approaches usually filter out low-quality samples or duplicate cases to keep away from coaching the mannequin on suboptimal information. Nevertheless, this strategy often overlooks the significance of variety. Deciding on solely high-quality information could result in fashions that carry out effectively on particular duties however need assistance with broader generalization. Whereas quality-first sampling has been utilized in earlier research, it lacks a holistic view of the dataset’s total representativeness. Furthermore, manually curated datasets or quality-based filters are time-consuming and will not seize the total complexity of the information.
Researchers from Northeastern College, Stanford College, Google Analysis, and Cohere For AI have launched an progressive iterative refinement technique to beat these challenges. Their strategy emphasizes diversity-centric information choice utilizing k-means clustering. This technique ensures that the chosen subset of information represents the total dataset extra precisely. The researchers suggest an iterative refinement course of impressed by lively studying strategies, which permits the mannequin to resample cases from clusters throughout coaching. This iterative strategy ensures that clusters containing low-quality or outlier information are regularly filtered out, focusing extra on various and consultant information factors. The strategy goals to stability high quality and variety, guaranteeing that the mannequin doesn’t turn into biased towards particular information classes.
The strategy launched k-means-quality (kMQ) sampling and clusters information factors into teams based mostly on similarity. The algorithm then samples information from every cluster to type a subset of coaching information. Every cluster is assigned a sampling weight proportional to its dimension, adjusted throughout coaching based mostly on how effectively the mannequin learns from every cluster. In essence, clusters with high-quality information are prioritized, whereas these with decrease high quality are given much less significance in subsequent iterations. The iterative course of permits the mannequin to refine its studying because it progresses by means of coaching, making changes as wanted. This technique contrasts conventional fastened sampling strategies, which don’t contemplate the mannequin’s studying conduct throughout coaching.
The efficiency of this technique has been rigorously examined throughout a number of duties, together with query answering, reasoning, math, and code era. The analysis group evaluated their mannequin on a number of benchmark datasets, similar to MMLU (educational query answering), GSM8k (grade-school math), and HumanEval (code era). The outcomes have been important: the kMQ sampling technique led to a 7% enchancment in efficiency over random information choice and a 3.8% enchancment over state-of-the-art strategies like Deita and QDIT. On duties similar to HellaSwag, which exams commonsense reasoning, the mannequin achieved an accuracy of 83.3%, whereas in GSM8k, the mannequin improved from 14.5% to 18.4% accuracy utilizing the iterative kMQ course of. This demonstrated the effectiveness of diversity-first sampling in enhancing the mannequin’s generalization throughout numerous duties.
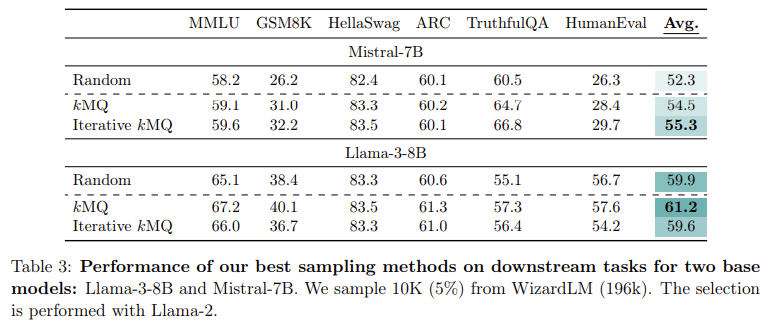
The researchers’ technique outperformed earlier effectivity strategies with these substantial efficiency features. In contrast to extra advanced processes that depend on giant language fashions to attain and filter information factors, kMQ achieves aggressive outcomes with out costly computational assets. Through the use of a easy clustering algorithm and iterative refinement, the method is each scalable and accessible, making it appropriate for a wide range of fashions and datasets. This makes the strategy significantly helpful for researchers working with restricted assets who nonetheless goal to realize excessive efficiency in coaching LLMs.

In conclusion, this analysis solves one of the vital important challenges in coaching giant language fashions: choosing a high-quality, various subset of information that maximizes efficiency throughout duties. By introducing k-means clustering and iterative refinement, the researchers have developed an environment friendly technique that balances variety and high quality in information choice. Their strategy results in efficiency enhancements of as much as 7% and ensures that fashions can generalize throughout a broad spectrum of duties.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


