


Machine studying analysis has superior towards fashions that may autonomously design and uncover information buildings tailor-made to particular computational duties, similar to nearest neighbor (NN) search. This shift in methodology permits fashions to be taught not solely the construction of knowledge but additionally learn how to optimize question responses, minimizing storage wants and computation time. Machine studying now strikes past conventional information processing, tackling structural optimization in information to create adaptable frameworks that exploit distribution patterns and information traits. Such adaptability is effective throughout fields the place environment friendly information retrieval is essential, particularly in domains the place velocity and storage are constrained.
Designing environment friendly information buildings stays a major problem. Current buildings, like binary search bushes and k-d bushes, are usually designed with worst-case situations in thoughts. Whereas this ensures dependable efficiency, it additionally means they don’t leverage potential patterns within the information for extra environment friendly querying. Consequently, many conventional information buildings can not capitalize on traits distinctive to every dataset, leading to suboptimal efficiency for queries that might in any other case profit from customized, adaptive buildings. In consequence, there may be rising curiosity in information buildings that may adapt to particular information distributions, providing sooner question occasions and lowered reminiscence utilization tailor-made to specific purposes.
Strategies developed to enhance information construction effectivity have primarily targeted on learning-augmented algorithms, the place conventional information buildings are modified with machine studying predictions to hurry up queries. Nevertheless, even these strategies are restricted by their reliance on predefined buildings which will should be optimally suited to the dataset. For instance, whereas learning-augmented bushes and locality-sensitive hashing enhance search effectivity by combining algorithmic rules with predictive fashions, they’re constrained by human-defined buildings. These fashions nonetheless rely on preliminary information buildings, limiting their capacity to adapt to distinctive information distributions autonomously.
The researchers from Universite de Montreal Mila, HEC Montreal Mila, Microsoft Analysis, College of Southern California, and Stanford College proposed an modern framework that leverages machine studying to find information buildings suited to particular duties autonomously. This framework consists of two core elements:
- A knowledge-processing community that arranges uncooked information into optimized buildings
- A question-execution community that effectively navigates the structured information for retrieval
Each networks endure joint end-to-end coaching, permitting them to adapt to various information distributions. By eliminating the necessity for predefined buildings, the framework autonomously designs optimized configurations that outperform conventional strategies throughout totally different information and question sorts, together with NN search and frequency estimation in streaming information.
The methodology includes an 8-layer transformer mannequin, the place the data-processing community ranks parts inside a dataset, organizing them into environment friendly configurations. This rating is refined via a differentiable sorting perform, which orders the information based mostly on their ranks. In the meantime, the query-execution community, comprising a number of impartial fashions, learns an optimum search technique for retrieving particular information factors based mostly on historic question patterns. This joint coaching customizes the information construction and enhances question accuracy. For example, the mannequin demonstrates excessive precision in appropriately ordering 99.5% of 1D NN search information regardless of needing to be explicitly programmed. This stage of precision exemplifies how data-driven buildings, as soon as designed, can improve each storage effectivity and retrieval velocity.
The framework excelled throughout a number of take a look at situations in evaluations. In 1D NN search, the mannequin displayed accuracy ranges greater than conventional binary search strategies. For instance, the mannequin outperformed binary search by strategically initiating queries nearer to the goal location when examined on information with a uniform distribution over (-1, 1) with 100 parts and restricted to seven lookups. In high-dimensional contexts, similar to 30-dimensional hyperspheres, the mannequin used projections that carefully resembled locality-sensitive hashing, reaching outcomes corresponding to specialised algorithms. Notably, in a difficult setup the place question accuracy should be accomplished inside a restricted house, the mannequin utilized further house successfully, buying and selling reminiscence for question precision. The mannequin’s accuracy elevated when given seven further vectors for storage, demonstrating its adaptability to various spatial constraints.
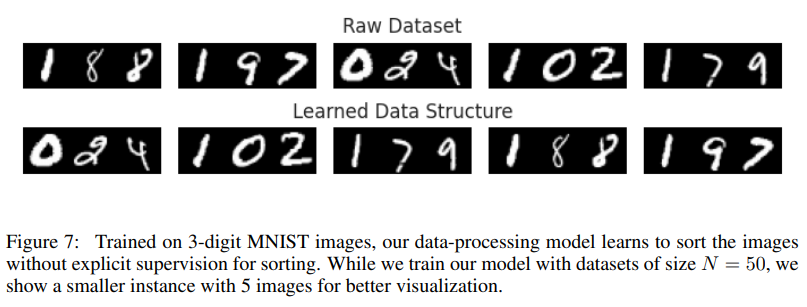
The analysis presents a number of key takeaways that illustrate the framework’s capabilities and improvements:
- Autonomous Construction Discovery: The mannequin independently learns the best information construction configurations, eradicating the necessity for predefined, human-designed buildings.
- Excessive Precision in Easy and Complicated Knowledge Settings: Achieved 99.5% accuracy in ordered rating for 1D NN search and efficiently navigated uniform and high-dimensional information with minimal supervision.
- Environment friendly Use of Further Area for Enhanced Accuracy: The framework demonstrated a transparent efficiency enhance as further reminiscence was allotted, exhibiting adaptability in constrained environments.
- Broad Applicability Past NN Search: The framework’s flexibility was additional highlighted in frequency estimation duties, the place it exceeded the efficiency of CountMin sketch fashions in information with Zipfian distributions, indicating potential for different high-demand purposes.

In conclusion, this analysis illustrates a promising step towards the way forward for machine learning-driven information construction discovery. By harnessing adaptive end-to-end coaching, this framework effectively addresses the storage and question challenges that conventional information buildings face, particularly when working inside real-world information constraints. This strategy enhances the velocity and accuracy of knowledge retrieval and opens avenues for autonomous discovery in information processing, marking a major development in machine studying’s utility to structural optimization.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.


