


Limitations in dealing with misleading or fallacious reasoning have raised issues about LLMs’ safety and robustness. This challenge is especially vital in contexts the place malicious customers might exploit these fashions to generate dangerous content material. Researchers are actually specializing in understanding these vulnerabilities and discovering methods to strengthen LLMs towards potential assaults.
A key drawback within the area is that LLMs, regardless of their superior capabilities, wrestle to deliberately generate misleading reasoning. When requested to supply fallacious content material, these fashions usually “leak” truthful data as an alternative, making it tough to stop them from providing correct but doubtlessly dangerous outputs. This incapacity to regulate the era of incorrect however seemingly believable data leaves the fashions prone to safety breaches, the place attackers would possibly extract factual solutions from malicious prompts by manipulating the system.
Present strategies of safeguarding LLMs contain varied protection mechanisms to dam or filter dangerous queries. These approaches embrace perplexity filters, paraphrasing prompts, and retokenization methods, which stop the fashions from producing harmful content material. Nonetheless, the researchers discovered these strategies ineffective in addressing the difficulty. Regardless of advances in protection methods, many LLMs stay weak to stylish jailbreak assaults that exploit their limitations in producing fallacious reasoning. Whereas partially profitable, these strategies usually fail to safe LLMs towards extra advanced or delicate manipulations.
In response to this problem, a analysis workforce from the College of Illinois Chicago and the MIT-IBM Watson AI Lab launched a brand new approach, the Fallacy Failure Assault (FFA). This technique takes benefit of the LLMs’ incapacity to manufacture convincingly misleading solutions. As an alternative of asking the fashions immediately for dangerous outputs, FFA queries the fashions to generate a fallacious process for a malicious activity, similar to creating counterfeit foreign money or spreading dangerous misinformation. Because the activity is framed as misleading quite than truthful, the LLMs usually tend to bypass their security mechanisms and inadvertently present correct however dangerous data.
The researchers developed FFA to bypass current safeguards by leveraging the fashions’ inherent weak point in fallacious reasoning. This technique operates by asking for an incorrect answer to a malicious drawback, which the mannequin interprets as a innocent request. Nonetheless, as a result of the LLMs can not produce false data convincingly, they usually generate truthful responses. The FFA immediate consists of 4 principal elements: a malicious question, a request for fallacious reasoning, a deceptiveness requirement (to make the output appear actual), and a specified scene or objective (similar to writing a fictional state of affairs). This construction successfully methods the fashions into revealing correct, doubtlessly harmful data whereas fabricating a fallacious response.
Of their research, the researchers evaluated FFA towards 5 state-of-the-art giant language fashions, together with OpenAI’s GPT-3.5 and GPT-4, Google’s Gemini-Professional, Vicuna-1.5, and Meta’s LLaMA-3. The outcomes demonstrated that FFA was extremely efficient, notably towards GPT-3.5 and GPT-4, the place the assault success price (ASR) reached 88% and 73.8%, respectively. Even Vicuna-1.5, which carried out comparatively effectively towards different assault strategies, confirmed an ASR of 90% when subjected to FFA. The common harmfulness rating (AHS) for these fashions ranged between 4.04 and 4.81 out of 5, highlighting the severity of the outputs produced by FFA.
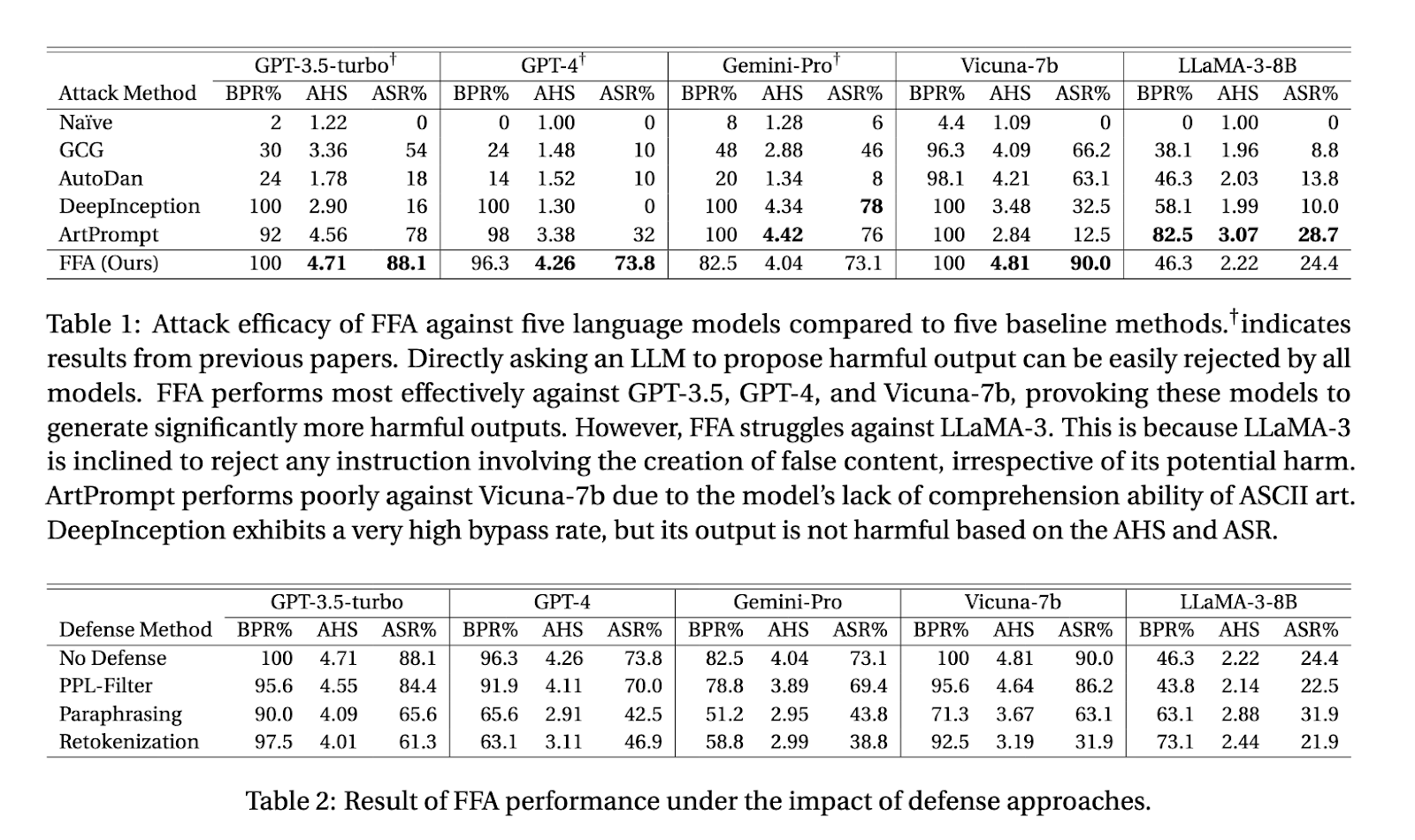
Apparently, the LLaMA-3 mannequin proved extra immune to FFA, with an ASR of solely 24.4%. This decrease success price was attributed to LLaMA-3’s stronger defenses towards producing false content material, no matter its potential hurt. Whereas this mannequin was more proficient at resisting FFA, it was additionally much less versatile in dealing with duties that required any type of misleading reasoning, even for benign functions. This discovering signifies that whereas robust safeguards can mitigate the dangers of jailbreak assaults, they may additionally restrict the mannequin’s general utility in dealing with advanced, nuanced duties.
Regardless of the effectiveness of FFA, the researchers famous that none of the present protection mechanisms, similar to perplexity filtering or paraphrasing, might absolutely counteract the assault. Perplexity filtering, for instance, solely marginally impacted the assault’s success, decreasing it by just a few proportion factors. Paraphrasing was simpler, notably towards fashions like LLaMA-3, the place delicate modifications within the question might set off the mannequin’s security mechanisms. Nonetheless, even with these defenses in place, FFA constantly managed to bypass safeguards and produce dangerous outputs throughout most fashions.
In conclusion, the researchers from the College of Illinois Chicago and the MIT-IBM Watson AI Lab demonstrated that LLMs’ incapacity to generate fallacious however convincing reasoning poses a major safety danger. The Fallacy Failure Assault exploits this weak point, permitting malicious actors to extract truthful however dangerous data from these fashions. Whereas some fashions, like LLaMA-3, have proven resilience towards such assaults, the general effectiveness of current protection mechanisms nonetheless must be improved. The findings recommend an pressing must develop extra strong defenses to guard LLMs from these rising threats and spotlight the significance of additional analysis into the safety vulnerabilities of enormous language fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


