


Giant language fashions (LLMs) have made necessary advances in synthetic intelligence, with superior efficiency on varied duties as their parameters and coaching knowledge develop. GPT-3, PaLM, and Llama-3.1 carry out effectively in lots of purposes with billions of parameters. Nevertheless, when applied in low-power platforms, scaling LLMs poses extreme difficulties relating to coaching and inference queries. Whereas it was nonetheless experimental and uncommon, scaling proved environment friendly in reaching a bigger variety of folks over time, and because the course of progressed, it turned very unsustainable. Additionally it is essential to allow the potential of making use of LLMs on gadgets with little computational energy to deal with extra elementary points of reasoning and produce extra tokens.
Present strategies for optimizing giant language fashions comprise scaling, pruning, distillation, and quantization. Scaling enhances efficiency by growing parameters however calls for greater assets. Pruning removes much less vital mannequin elements to cut back measurement however typically sacrifices efficiency. Distillation trains smaller fashions to duplicate bigger ones however sometimes leads to decrease density. Quantization reduces numerical precision for effectivity however could degrade outcomes. These strategies fail to steadiness effectivity and efficiency effectively, so there’s a shift towards optimizing “density” as a extra sustainable metric for growing giant language fashions.
To resolve this, researchers from Tsinghua College and ModelBest Inc. proposed the idea of “Functionality density” as a brand new metric to judge the standard of LLMs throughout completely different scales and describe their tendencies when it comes to effectiveness and effectivity. The density of Giant Language Fashions (LLMs) is the ratio of efficient parameter measurement to precise parameter measurement. The efficient parameter measurement represents the variety of parameters wanted by a reference mannequin to match the efficiency of a given mannequin. That is estimated utilizing the Scaling Regulation in two steps: (1) becoming a perform between parameter measurement and language mannequin loss and (2) predicting downstream process efficiency utilizing a sigmoid perform. The efficient parameter measurement is computed after becoming loss and efficiency. Mannequin density is calculated because the ratio of efficient parameter measurement to precise measurement, the place greater density suggests higher efficiency per parameter. It’s a very helpful idea for optimizing fashions, primarily for deployment on resource-limited gadgets.
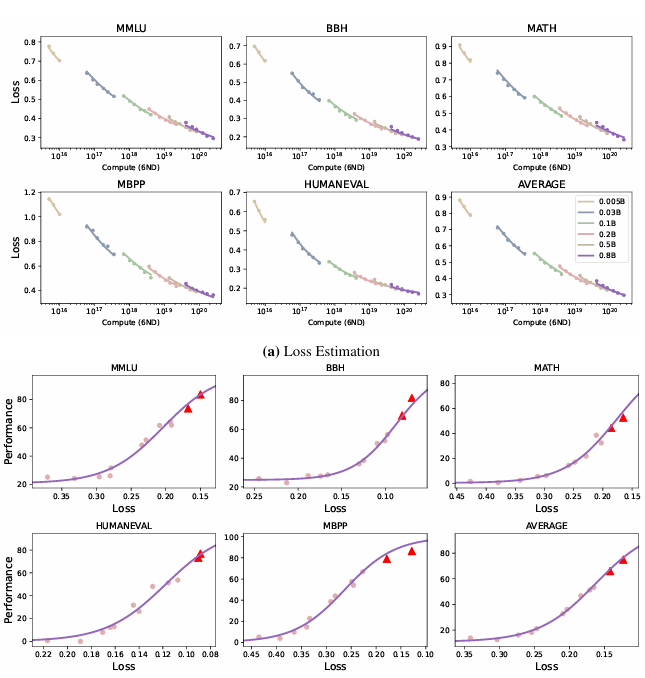
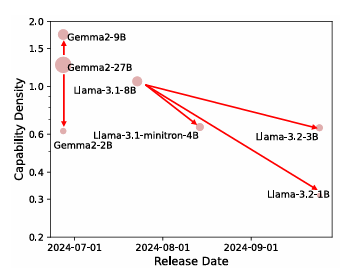
Researchers analyzed 29 open-source pre-trained fashions and evaluated the efficiency of enormous language fashions (LLMs) on varied datasets, together with MMLU, BBH, MATH, HumanEval, and MBPP, beneath few-shot settings like 5-shot, 3-shot, and 0-shot, using open-source instruments for benchmarking. The fashions have been educated with various parameter sizes, token lengths, and knowledge scales, making use of methods equivalent to chain-of-thought prompting and completely different studying fee schedulers. The efficiency scaling curves have been obtained by coaching fashions on completely different token sizes, with fashions like Llama, Falcon, MPT, Phi, Mistral, and MiniCPM being examined throughout varied configurations. Over time, the density of those fashions elevated considerably, with newer fashions, equivalent to MiniCPM-3-4B, reaching greater densities than older fashions. A linear regression mannequin indicated that the LLM density doubles roughly each 95 days. Because of this designs with extra modest capabilities and decrease prices will quickly be capable of compete with larger, extra difficult fashions, and technological advances will open the way in which to much more environment friendly designs.
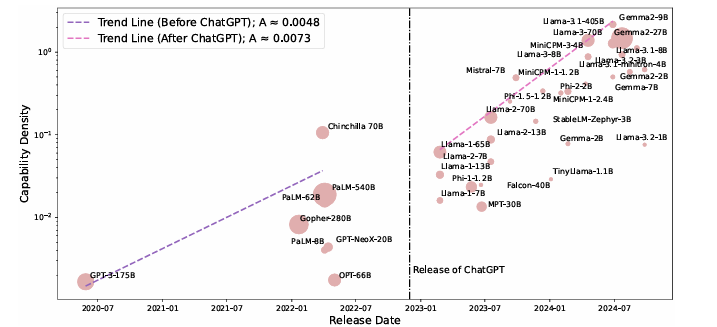
In conclusion, the proposed methodology highlighted exponentially growing functionality density in LLMs by displaying speedy growth and effectivity enhancements. The analysis outcomes on some extensively used LLM benchmarks indicated that the density of LLMs doubles each three months. Researchers additionally proposed the shift in the direction of inference FLOPs for evaluating density by contemplating deeper reasoning. This methodology can be utilized for upcoming analysis and could be a turning level within the area of LLMs!
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our publication to get trending AI analysis and dev updates
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.


