


Precisely predicting the place an individual is wanting in a scene—gaze goal estimation—represents a big problem in AI analysis. Integrating advanced cues comparable to head orientation and scene context should be used to deduce gaze course. Historically, strategies for this downside use multi-branch architectures, processing the scene and head options individually earlier than integrating them with auxiliary inputs, comparable to depth and pose. Nonetheless, these strategies are computationally intensive, laborious to coach, and infrequently fail to generalize effectively throughout datasets. This requires overcoming these points in order that the functions in understanding human habits, robotics, and assistive applied sciences can progress.
Current gaze estimation strategies closely depend upon multi-branch pipelines, the place separate encoders deal with the scene and head options, adopted by fusion modules to mix these inputs. To enhance effectivity, many of those fashions use extra alerts, comparable to pose, depth, and auxiliary options, that are obtained from particular modules. Nonetheless, these approaches have a number of limitations. First, their excessive computational value makes real-time implementation unimaginable. Second, these programs typically require massive quantities of labeled coaching information, which is labor-intensive and practically unimaginable to scale. This limits their capacity to switch realized generalizations to quite a few environments and datasets when counting on specific encoders with supplementary inputs.
To handle these points, researchers from the Georgia Institute of Expertise and the College of Illinois Urbana-Champaign launched Gaze-LLE, a streamlined and environment friendly framework for gaze goal estimation. Gaze-LLE eliminates the necessity for advanced multi-branch architectures by means of a static DINOv2 visible encoder and a minimalist decoder module. The framework makes use of a unified spine for function extraction and has an progressive head positional prompting mechanism that permits the gaze estimation to be particular to sure people within the scene. Among the main contributions of this technique are lowering trainable parameters to a big stage that interprets into 95% fewer computations as compared with conventional strategies. Gaze-LLE can also be a profitable technique in remodeling transformer-based encoders at a big scale. It precisely permits gaze estimation with out advanced auxiliary fashions and permits for the upkeep of superior efficiency with minimal changes throughout a spread of datasets and duties by means of a easy and scalable structure.
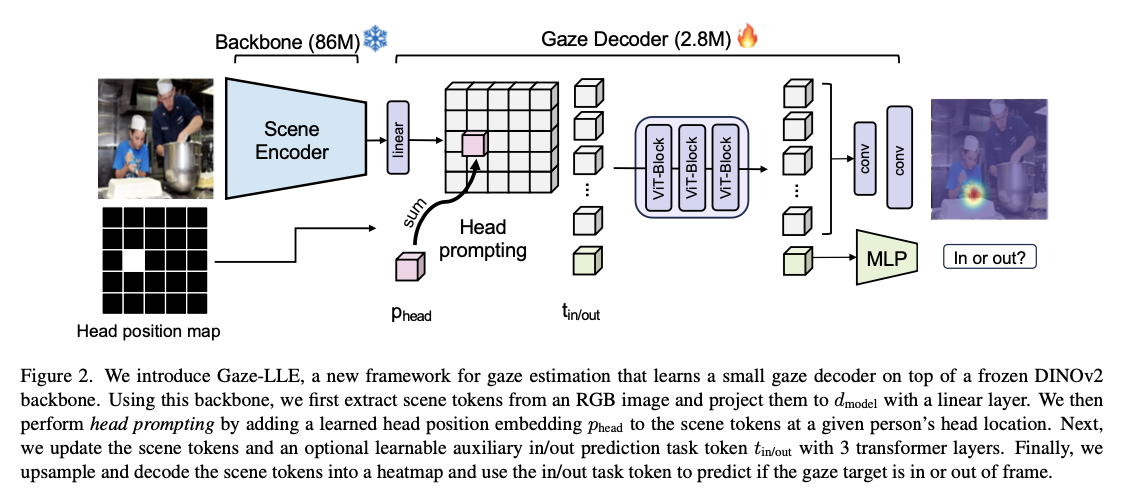
The structure of Gaze-LLE includes two principal parts. First, a frozen DINOv2 visible encoder extracts sturdy options from the enter picture, that are then projected right into a lower-dimensional house by way of a linear layer for environment friendly processing. Second, a light-weight gaze decoder integrates these scene options with a head place embedding that encodes the situation of the person being noticed. This mechanism permits the mannequin to give attention to the precise supply of gaze. The gaze decoder consists of three transformer layers meant for use for function enhancement, and it produces a gaze heatmap that signifies attainable targets of gaze, in addition to an in-frame classification to find out whether or not the gaze falls throughout the observable body. The straightforward mannequin requires utilizing a simple coaching goal: merely a pixel-wise binary cross-entropy loss, permitting the optimum tuning and not using a refined strategy primarily based on advanced multitasking goals. Benchmarks comprised benchmark datasets: GazeFollow, VideoAttentionTarget, and ChildPlay.
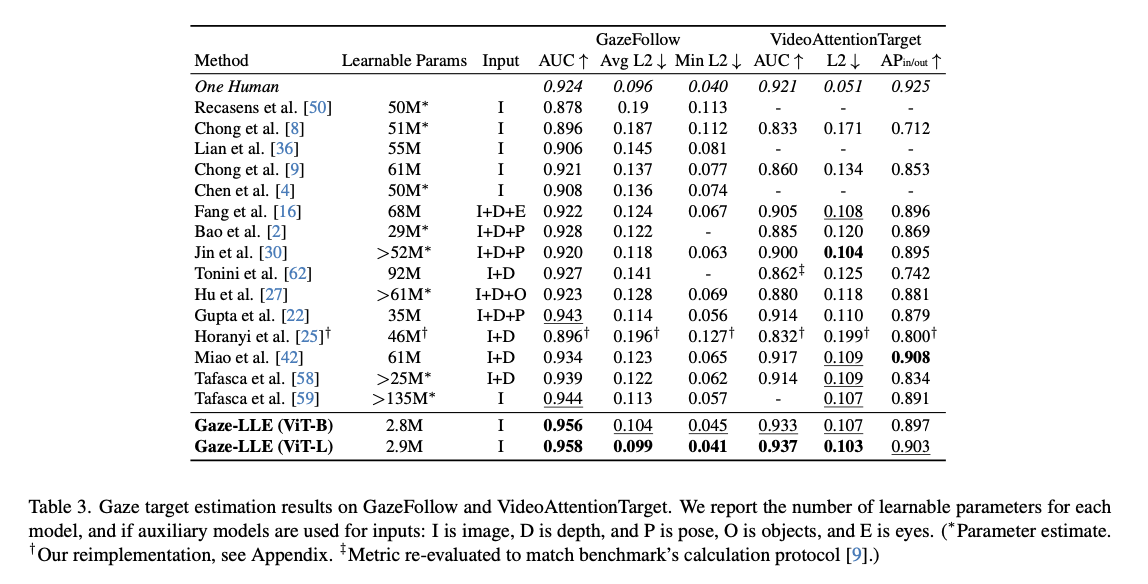
Gaze-LLE achieves state-of-the-art efficiency throughout a number of benchmarks with considerably fewer parameters and sooner coaching occasions. The GazeFollow dataset, yields an AUC of 0.958 and a median L2 error of 0.099, besting prior strategies each in precision and in computational effectivity. The coaching time is, specifically, remarkably environment friendly, with the mannequin attaining convergence inside lower than 1.5 GPU hours and considerably outperforming conventional multi-branch architectures. Additional, Gaze-LLE additionally reveals sturdy generalization properties as its excessive efficiency is retained over a number of datasets, like ChildPlay and GOO-Actual, even with out fine-tuning. Outcomes like these present that the frozen foundational fashions in an optimized structure may be helpful for correct and versatile gaze estimation.

In abstract, Gaze-LLE redefines gaze goal estimation with a streamlined and efficient framework that brings in elementary visible encoders and an progressive head positional prompting system. Free from the intricacies of architectures with a number of branches, this achieves larger accuracy, higher effectivity, and scalability. Furthermore, its capacity to generalize throughout varied datasets supplies promise for its functions in additional analysis on human habits and associated fields, thus introducing a brand new benchmark for the development of gaze estimation analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


