


Generative AI fashions, pushed by Giant Language Fashions (LLMs) or diffusion methods, are revolutionizing inventive domains like artwork and leisure. These fashions can generate numerous content material, together with texts, photographs, movies, and audio. Nonetheless, refining the standard of outputs requires extra inference strategies throughout deployment, equivalent to Classifier-Free Steering (CFG). Whereas CFG improves constancy to prompts, it presents two important challenges: elevated computational prices and diminished output variety. This quality-diversity trade-off is a crucial situation in generative AI. Specializing in high quality tends to scale back variety, whereas growing variety can decrease high quality, and balancing these facets is essential for creating AI methods.
Present strategies like Classifier-free steering (CFG) have been broadly utilized to domains like picture, video, and audio technology. Nonetheless, its unfavourable affect on variety limits its usefulness in exploratory duties. One other methodology, Data distillation, has emerged as a strong method for coaching state-of-the-art fashions, with some researchers proposing offline strategies to distill CFG-augmented fashions. The High quality-diversity trade-offs of various inference-time methods like temperature sampling, top-k sampling, and nucleus sampling have been in contrast, with nucleus sampling performing finest when high quality is prioritized. Different associated works, equivalent to Mannequin Merging for Pareto-Optimality and Music Era, are additionally mentioned on this paper.
Researchers from Google DeepMind have proposed a novel finetuning process referred to as diversity-rewarded CFG distillation to deal with the restrictions of classifier-free steering (CFG) whereas preserving its strengths. This method combines two coaching targets: a distillation goal that encourages the mannequin to observe CFG-augmented predictions and a reinforcement studying (RL) goal with a variety reward to advertise assorted outputs for given prompts. Furthermore, this methodology permits weight-based mannequin merging methods to manage the quality-diversity trade-off at deployment time. Additionally it is utilized to the MusicLM text-to-music generative mannequin, demonstrating superior efficiency in quality-diversity Pareto optimality in comparison with commonplace CFG.
The experiments had been carried out to deal with three key questions:
- The effectiveness of CFG distillation.
- The affect of variety rewards in reinforcement studying.
- The potential of mannequin merging for making a steerable quality-diversity entrance.
The evaluations on high quality evaluation contain human raters to get acoustic high quality, textual content adherence, and musicality on a 1-5 scale, utilizing 100 prompts with three raters per immediate. Variety is equally evaluated, with raters evaluating pairs of generations from 50 prompts. The analysis metrics embrace the MuLan rating for textual content adherence and the Person Choice rating primarily based on pairwise preferences. The examine incorporates human evaluations for high quality, variety, quality-diversity trade-offs, and qualitative evaluation to supply an in depth evaluation of the proposed methodology’s efficiency in music technology.
Human evaluations present that the CFG-distilled mannequin performs comparably to the CFG-augmented base mannequin when it comes to high quality, and each outperform the unique base mannequin. For variety, the CFG-distilled mannequin with variety reward (β = 15) considerably outperforms each the CFG-augmented and CFG-distilled (β = 0) fashions. Qualitative evaluation of generic prompts like “Rock music” confirms that CFG improves high quality however reduces variety, whereas the β = 15 mannequin generates a wider vary of rhythms with enhanced high quality. For particular prompts like “Opera singer,” the quality-focused mannequin (β = 0) produces typical outputs, whereas the various mannequin (β = 15) creates extra unconventional and artistic outcomes. The merged mannequin successfully balances these qualities, producing high-quality music.
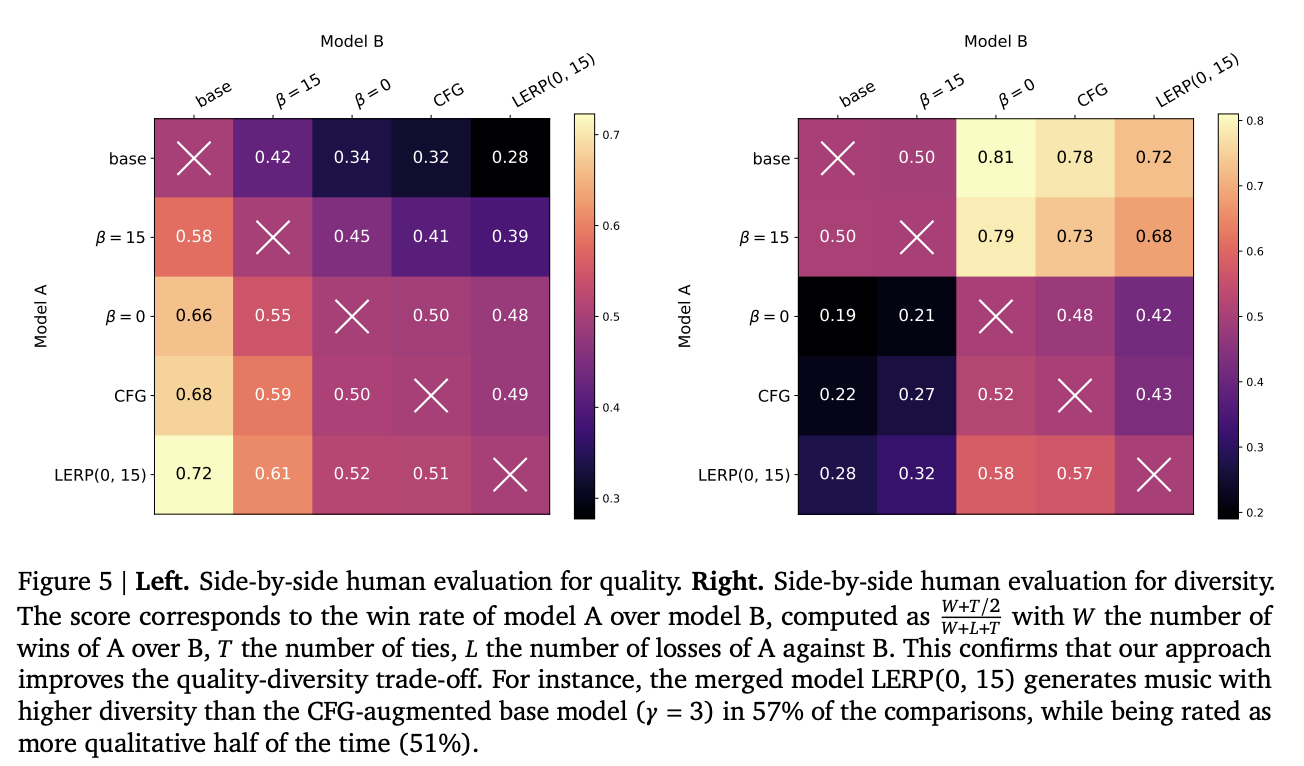
In conclusion, researchers from Google DeepMind have launched a finetuning process referred to as diversity-rewarded CFG distillation to enhance the quality-diversity trade-off in generative fashions. This method combines three key parts: (a) on-line distillation of classifier-free steering (CFG) to get rid of computational overhead, (b) reinforcement studying with a variety reward primarily based on similarity embeddings, and (c) mannequin merging for dynamic management of the quality-diversity stability throughout deployment. Intensive experiments in text-to-music technology validate the effectiveness of this technique, with human evaluations confirming the superior efficiency of the finetuned-then-merged mannequin. This method holds nice potential for purposes the place creativity and alignment with person intent are necessary.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Information Retrieval Convention (Promoted)

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the affect of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.


