

: A Dataset and Benchmark to Consider the Robustness of Offline Reinforcement Studying Brokers to Visible Distractors")
Reinforcement studying (RL) supplies a framework for studying behaviors for management and making choices (referred to as insurance policies) that assist the mannequin earn essentially the most rewards in a given setting. On-line RL algorithms iteratively take actions, accumulating observations and rewards from the setting, after which replace their coverage utilizing the most recent expertise. This on-line studying course of is, nevertheless basically sluggish. Not too long ago it has change into clear that studying behaviors from giant beforehand collected datasets through behavioral cloning or different types of offline RL, is an efficient different technique to construct scalable generalist brokers. Regardless of these advances, current analysis signifies that brokers educated on offline visible knowledge typically exhibit poor generalization to novel visible domains and may fail underneath minor visible variations in control-irrelevant components, similar to background or digicam viewpoint. This subject hampers the generalization of brokers educated on visible knowledge.
Many environments have been developed to review the efficiency of RL brokers. Nonetheless, these environments consider the robustness of on-line RL brokers to visible distractors and don’t present pre-collected trajectories for offline studying. Whereas a number of datasets exist to evaluate the generalization of those representation-learning methods to numerous visible perturbations these datasets don’t present the important properties wanted to judge these representation-learning strategies for management completely. Current datasets and benchmarks for offline RL typically lack the variety and robustness wanted to evaluate the brokers underneath various visible situations. They sometimes don’t embody each state and pixel observations, limiting their utility in assessing the illustration hole.
To mitigate these points, the Google DeepMind researchers introduce the DeepMind Management Imaginative and prescient Benchmark (DMC-VB), a complete dataset designed to judge the robustness of offline RL brokers in steady management duties with visible distractors2. DMC-VB contains various duties, visible variations, and knowledge from insurance policies of various ability ranges, making it a extra rigorous benchmark for illustration studying strategies.
To fill the gaps, a gaggle of researchers from Google DeepMind launched the DeepMind Management Imaginative and prescient Benchmark (DMC-VB)—a dataset collected utilizing the DeepMind Management Suite and numerous extensions thereof. DMC-VB is rigorously designed to allow systematic and rigorous analysis of illustration studying strategies for management within the presence of visible variations, by satisfying six key desiderata. (a) It comprises a range of duties together with duties the place state-of-the-art algorithms wrestle to drive the event of novel algorithms. (b) It comprises several types of visible distractors (e.g. altering background, shifting digicam) to review the robustness of assorted life like visible variations. (c) It contains demonstrations of differing high quality to research whether or not efficient insurance policies might be derived from suboptimal demonstrations. (d) It contains each pixel observations and states, the place states are related proprioceptive and exteroceptive measurements. Insurance policies educated on states can then present an higher certain to quantify the “illustration hole” of insurance policies educated on pixels. (e) It’s bigger than earlier datasets. (f) It contains duties the place the objective can’t be decided from visible observations, for which current work means that pretraining representations are vital. As DMC-VB is the primary dataset to fulfill these six desiderata it’s nicely positioned to advance analysis in illustration studying for management. DMC-VB comprises each easier locomotion duties and more durable 3D navigation duties.
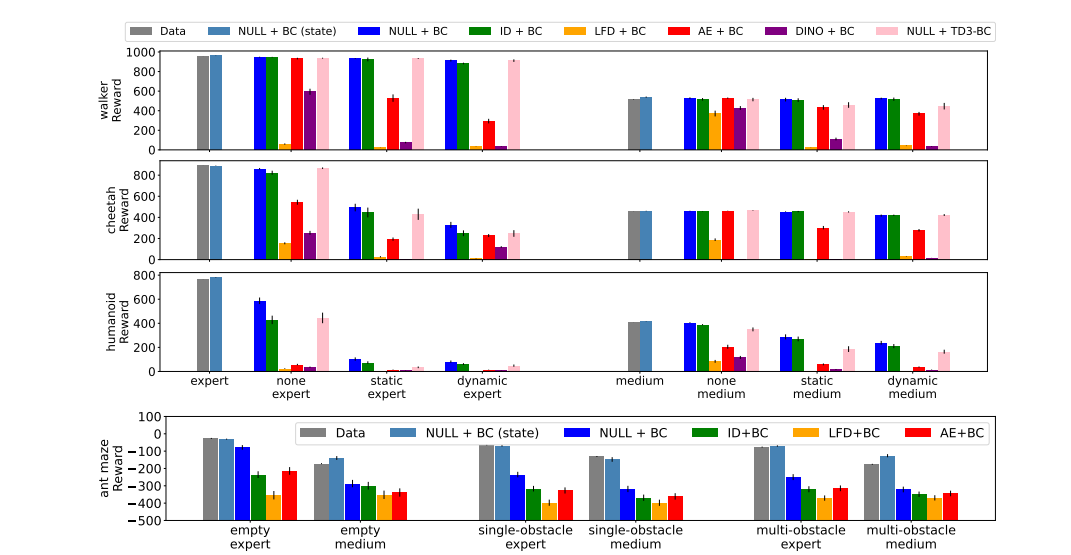
Accompanying the dataset, they proposed three benchmarks that leverage the rigorously designed properties of DMC-VB to judge illustration studying strategies for management. (B1) evaluates the degradation of coverage studying within the presence of visible distractors and, in doing so, quantifies the illustration hole between brokers educated on states and pixel observations. Researchers discovered that the easy conduct cloning (BC) baseline is the most effective total technique and that just lately proposed illustration studying strategies, similar to inverse dynamics (ID), don’t present advantages on our benchmark. (B2) investigates a sensible setting with entry to a big dataset of mixed-quality knowledge and some skilled demonstrations. Upon deep investigation, researchers found that utilizing a mixture of knowledge to pre-train visible representations helps enhance how brokers study insurance policies. Additionally, when finding out how brokers study from demonstrations with hidden objectives (like after they discover a brand new setting with out particular objectives), they discovered that these pre-trained representations assist brokers rapidly study new duties with only some examples.
The paper presents a sturdy resolution to judge the generalization of offline RL brokers underneath visible variations and consider their effectiveness. DMC-VB may very well be prolonged to a broader vary of environments, together with sparse rewards, a number of brokers, complicated manipulation duties, or stochastic dynamics. Additionally, the artificial nature of our visible distractors could increase questions concerning the generalization of our findings to real-world duties. The DMC-VB dataset and benchmarks present an in depth framework for advancing analysis in illustration studying for management duties and henceforth present a future base for upcoming researchers.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Effective-Tuned Fashions: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.

")

