


Giant language fashions (LLMs) are integral to fixing advanced issues throughout language processing, arithmetic, and reasoning domains. Enhancements in computational methods concentrate on enabling LLMs to course of information extra successfully, producing extra correct and contextually related responses. As these fashions turn into advanced, researchers try to develop strategies to function inside mounted computational budgets with out sacrificing efficiency.
One main problem in optimizing LLMs is their incapability to successfully motive throughout a number of duties or carry out computations past their pre-trained structure. Present strategies for bettering mannequin efficiency contain producing intermediate steps throughout activity processing, typically at the price of elevated latency and computational inefficiency. This limitation hampers their potential to carry out advanced reasoning duties, notably these requiring longer dependencies or greater accuracy in predictions.
Researchers have explored strategies like Chain-of-Thought (CoT) prompting, which guides LLMs to motive step-by-step. Whereas efficient in some instances, CoT depends on sequential processing of intermediate reasoning steps, resulting in slower computation occasions. KV-cache compression has additionally been proposed to scale back reminiscence utilization however does little to enhance reasoning capabilities. These approaches, although useful, underscore the necessity for a way that mixes effectivity with enhanced reasoning potential.
Researchers from Google DeepMind have launched a way known as Differentiable Cache Augmentation. This system makes use of a skilled coprocessor to reinforce the LLM’s key-value (kv) cache with latent embeddings, enriching the mannequin’s inside reminiscence. The important thing innovation lies in conserving the bottom LLM frozen whereas coaching the coprocessor, which operates asynchronously. The researchers designed this methodology to reinforce reasoning capabilities with out rising the computational burden throughout activity execution.
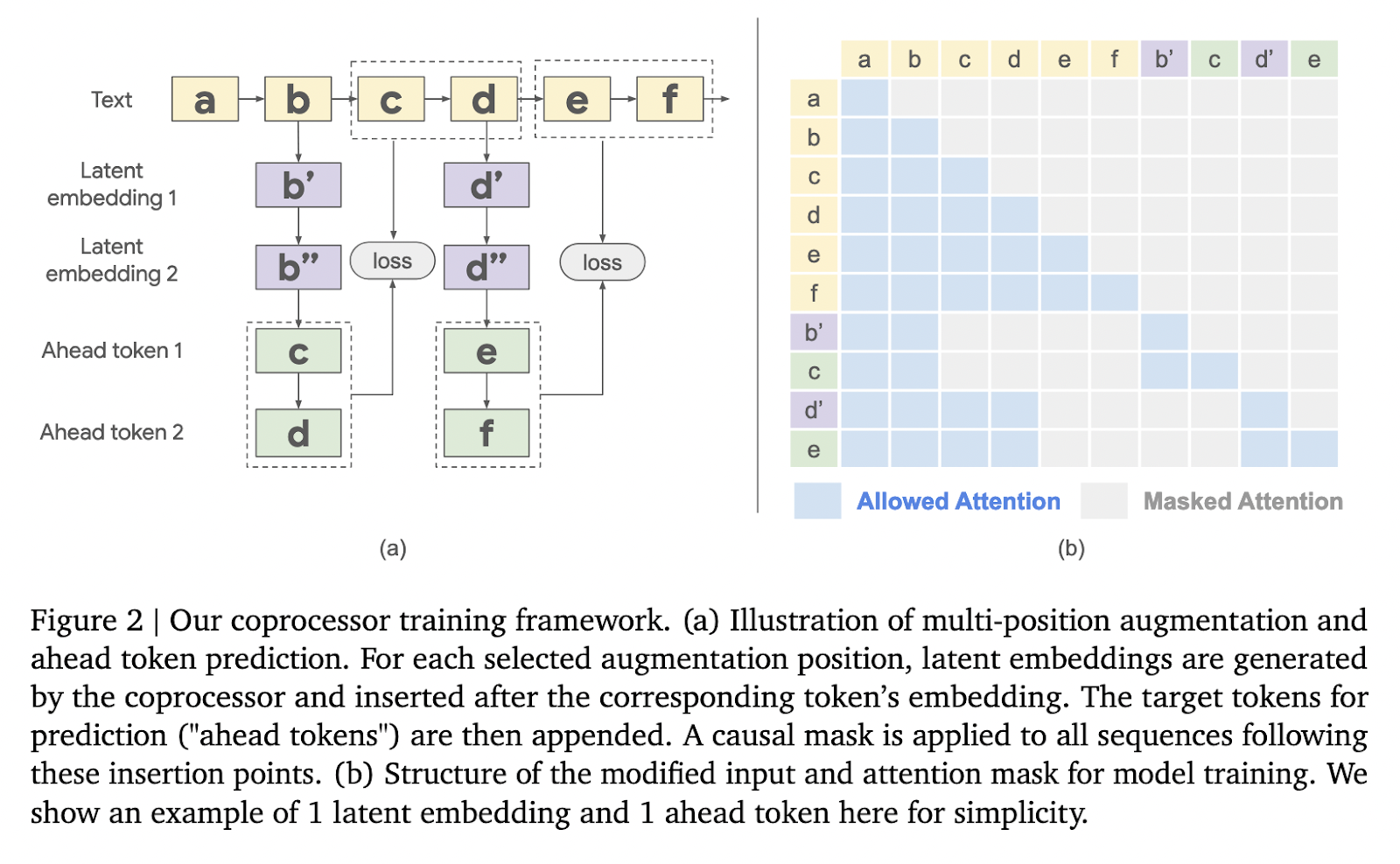
The methodology revolves round a three-stage course of. First, the frozen LLM generates a kv-cache from an enter sequence, encapsulating its inside illustration. This kv-cache is handed to the coprocessor, which processes it with extra trainable smooth tokens. Not tied to particular phrases, these tokens act as summary prompts for producing latent embeddings. As soon as processed, the augmented kv-cache is fed again into the LLM, enabling it to generate contextually enriched outputs. This asynchronous operation ensures the coprocessor’s enhancements are utilized effectively with out delaying the LLM’s main capabilities. Coaching the coprocessor is performed utilizing a language modeling loss, focusing solely on its parameters whereas preserving the integrity of the frozen LLM. This focused method permits for scalable and efficient optimization.
Efficiency evaluations demonstrated vital enhancements. The tactic was examined on the Gemma-2 2B mannequin, attaining appreciable outcomes throughout numerous benchmarks. For example, on the reasoning-intensive GSM8K dataset, accuracy improved by 10.05% when 64 latent embeddings had been used. Equally, MMLU efficiency elevated by 4.70% below the identical configuration. These enhancements underscore the mannequin’s potential to carry out higher on advanced reasoning duties. Additional, perplexity reductions had been noticed at a number of token positions. For instance, perplexity decreased by 3.94% at place one and 1.20% at place 32 when 64 latent embeddings had been utilized, showcasing the mannequin’s improved prediction capabilities over longer sequences.
Additional evaluation confirmed that the augmentation’s effectiveness scales with the variety of latent embeddings. For GSM8K, accuracy rose incrementally with extra embeddings, from 1.29% with 4 embeddings to the height enchancment of 10.05% with 64 embeddings. Comparable traits had been noticed in different benchmarks like ARC and MATH, indicating the broader applicability of this methodology. The researchers confirmed that their method persistently outperformed baseline fashions with out task-specific fine-tuning, demonstrating its robustness and flexibility.

This work represents a major step ahead in enhancing LLMs’ reasoning capabilities. By introducing an exterior coprocessor to reinforce the kv-cache, the researchers from Google DeepMind have created a way that improves efficiency whereas sustaining computational effectivity. The outcomes spotlight the potential for LLMs to deal with extra advanced duties, paving the best way for additional exploration into modular enhancements and scalable reasoning techniques. This breakthrough underscores the significance of continuous innovation in AI to fulfill the rising calls for of reasoning-intensive purposes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


