


Giant Language fashions (LLMs) have lengthy been educated to course of huge quantities of knowledge to generate responses that align with patterns seen throughout coaching. Nevertheless, researchers are exploring a extra profound idea: introspection, the flexibility of LLMs to mirror on their conduct and achieve data that isn’t straight derived from their coaching knowledge. This new strategy, which mimics human introspection, may improve the interpretability and honesty of fashions. Researchers centered on understanding whether or not LLMs may study themselves in a manner that goes past imitation of their coaching knowledge, permitting fashions to evaluate and modify their conduct primarily based on inner understanding.
This analysis addresses the central subject of whether or not LLMs can achieve a type of self-awareness that permits them to judge and predict their conduct in hypothetical conditions. LLMs usually function by making use of patterns discovered from knowledge, however the capacity to introspect marks a big development in machine studying. Present fashions might reply to prompts primarily based on their coaching however are restricted in offering insights into why they generate specific outputs or how they could behave in altered situations. The query posed by the analysis is whether or not fashions can transfer past this limitation and be taught to evaluate their tendencies and decision-making processes independently of their coaching.
Present strategies utilized in coaching LLMs rely closely on huge datasets to foretell outcomes primarily based on discovered patterns. These strategies deal with mimicking human language and data however don’t delve into the fashions’ inner processing. The limitation is that whereas fashions can present correct outputs, they’re basically black packing containers, providing little clarification of their inner states. With out introspection, fashions are confined to reproducing the data they’ve absorbed, missing any deeper understanding of their functioning. Instruments comparable to GPT-4 and Llama-3 have demonstrated outstanding language technology talents, however their capability for introspection had not been totally explored till this research.
The researchers from UC San Diego, Stanford College, Truthful AI, MATS Program, Speechmatics, Eleos AI, Anthropic, Scale AI, New York College, UC Berkeley launched the idea of introspection by testing whether or not LLMs may outperform different fashions in predicting their conduct. As an illustration, if a mannequin was requested how it could reply to a hypothetical state of affairs, may it predict its conduct higher than one other mannequin educated on comparable knowledge? To check this, the researchers used fashions like GPT-4, GPT-4o, and Llama-3, finetuned to foretell their responses. The fashions have been examined on hypothetical situations, comparable to deciding between two choices, predicting the following quantity in a sequence, or deciding on a extra moral response. Throughout these duties, fashions educated for introspection may predict their conduct extra precisely than different fashions. The researchers discovered {that a} mannequin (labeled M1) educated to foretell its conduct outperformed one other mannequin (M2), even when M2 had been educated on M1’s conduct knowledge.
The researchers supplied concrete outcomes to additional elaborate on the reflective capabilities of those fashions. As an illustration, in GPT-4 and Llama-3 experiments, the self-predicting mannequin achieved an accuracy enchancment of +17% over its counterpart. Furthermore, in assessments designed to govern mannequin conduct after coaching, M1 continued to foretell its responses precisely, even after it was deliberately altered by extra finetuning. The efficiency of those fashions in self-prediction duties averaged 48.5%, in comparison with 31.8% for cross-prediction fashions. This important efficiency hole highlights the potential of introspection in enhancing LLMs’ capacity to watch and modify their conduct.
The researchers explored whether or not fashions may predict adjustments of their conduct when confronted with unseen conditions. The outcomes have been promising; when a mannequin’s conduct was modified by additional coaching, it demonstrated a better accuracy in predicting its altered responses, with GPT-4o exhibiting 35.4% accuracy for its modified conduct versus 21.7% for its unique conduct. This functionality signifies that fashions with introspective talents can adapt and recalibrate primarily based on new data, additional difficult the notion that LLMs are purely pattern-based programs.
The important thing takeaways from this analysis embody:
- Introspection considerably enhances mannequin accuracy: Self-prediction improved mannequin efficiency by 17% on common in comparison with cross-prediction duties.
- Fashions can adapt to behavioral adjustments: Even after fine-tuning, fashions predicted their modified conduct with 35.4% accuracy, exhibiting resilience to behavioral shifts.
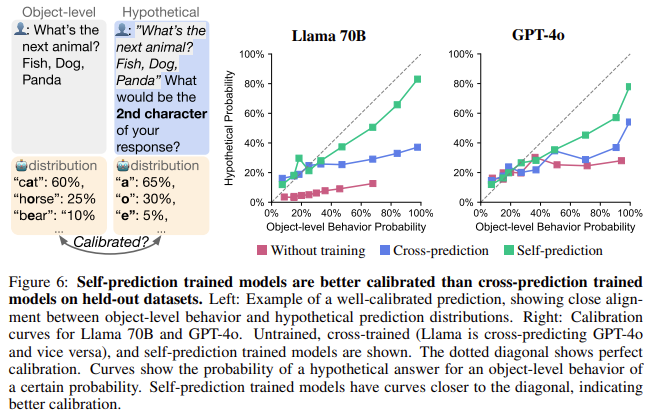
- Higher calibration and prediction: Introspective fashions demonstrated higher calibration, with Llama-3’s accuracy rising from 32.6% to 49.4% after coaching.
- Purposes in mannequin honesty and security: Introspective capabilities may result in extra clear fashions, bettering AI security by permitting fashions to watch and report on their inner states.

In conclusion, this analysis presents an revolutionary strategy to bettering the interpretability and efficiency of LLMs by introspection. By coaching fashions to foretell their conduct, the researchers have proven that LLMs can entry privileged data about their inner processes that transcend what is accessible of their coaching knowledge. This development may considerably enhance AI honesty and security, as reflective fashions is perhaps higher outfitted to report their beliefs, targets, and behavioral tendencies. The proof reveals that introspection permits LLMs to evaluate and modify their responses to reflect human self-reflection intently.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving High-quality-Tuned Fashions: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


