


A big problem in info retrieval immediately is figuring out probably the most environment friendly methodology for nearest-neighbor vector search, particularly with the rising complexity of dense and sparse retrieval fashions. Practitioners should navigate a variety of choices for indexing and retrieval strategies, together with HNSW (Hierarchical Navigable Small-World) graphs, flat indexes, and inverted indexes. These strategies provide totally different trade-offs by way of velocity, scalability, and high quality of retrieval outcomes. As datasets turn out to be bigger and extra complicated, the absence of clear operational steering makes it troublesome for practitioners to optimize their techniques, significantly for purposes requiring excessive efficiency, corresponding to serps and AI-driven purposes like question-answering techniques.
Historically, nearest-neighbor search is dealt with utilizing three essential approaches: HNSW indexes, flat indexes, and inverted indexes. HNSW indexes are generally used for his or her effectivity and velocity in large-scale retrieval duties, significantly with dense vectors, however they’re computationally intensive and require vital indexing time. Flat indexes, whereas actual of their retrieval outcomes, turn out to be impractical for giant datasets resulting from slower question efficiency. Sparse retrieval fashions, like BM25 or SPLADE++ ED, depend on inverted indexes and could be efficient in particular eventualities however typically lack the wealthy semantic understanding supplied by dense retrieval fashions. The principle limitation throughout these approaches is that none are universally relevant, with every methodology providing totally different strengths and weaknesses relying on the dataset measurement and retrieval
Researchers from the College of Waterloo introduce an intensive analysis of the trade-offs between HNSW, flat, and inverted indexes for each dense and sparse retrieval fashions. This analysis offers an in depth evaluation of the efficiency of those strategies, measured by indexing time, question velocity (QPS), and retrieval high quality (nDCG@10), utilizing the BEIR benchmark dataset. The researchers purpose to offer sensible, data-driven recommendation on the optimum use of every methodology based mostly on the dataset measurement and retrieval necessities. Their findings point out that HNSW is extremely environment friendly for large-scale datasets, whereas flat indexes are higher fitted to smaller datasets resulting from their simplicity and actual outcomes. Moreover, the research explores the advantages of utilizing quantization strategies to enhance the scalability and velocity of the retrieval course of, providing a big enhancement for practitioners working with massive datasets.
The experimental setup makes use of the BEIR benchmark, a set of 29 datasets designed to mirror real-world info retrieval challenges. The dense retrieval mannequin used is BGE (Base Common Embeddings), with SPLADE++ ED and BM25 serving because the baselines for sparse retrieval. The analysis focuses on two kinds of dense retrieval indexes: HNSW, which constructs graph-based constructions for nearest-neighbor search, and flat indexes, which depend on brute-force search. Inverted indexes are used for sparse retrieval fashions. The evaluations are performed utilizing the Lucene search library, with particular configurations corresponding to M=16 for HNSW. Efficiency is assessed utilizing key metrics like nDCG@10 and QPS, with question efficiency evaluated underneath two situations: cached queries (precomputed question encoding) and ONNX-based real-time question encoding.
The outcomes reveal that for smaller datasets (underneath 100K paperwork), flat and HNSW indexes present comparable efficiency by way of each question velocity and retrieval high quality. Nevertheless, as dataset sizes improve, HNSW indexes start to considerably outperform flat indexes, significantly by way of question analysis velocity. For giant datasets exceeding 1 million paperwork, HNSW indexes ship far increased queries per second (QPS), with solely a marginal lower in retrieval high quality (nDCG@10). When coping with datasets of over 15 million paperwork, HNSW indexes display substantial enhancements in velocity whereas sustaining acceptable retrieval accuracy. Quantization strategies additional enhance efficiency, significantly in massive datasets, providing notable will increase in question velocity and not using a vital discount in high quality. General, dense retrieval strategies utilizing HNSW show to be far more practical and environment friendly than sparse retrieval fashions, significantly for large-scale purposes requiring excessive efficiency.
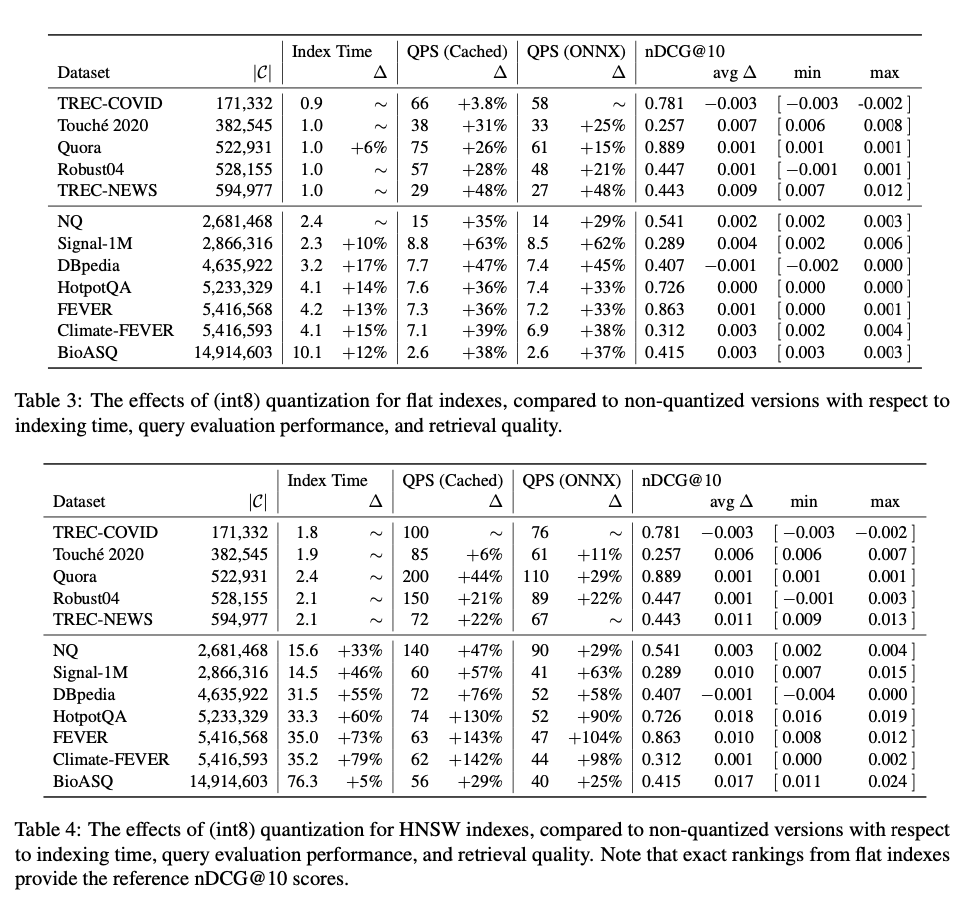
This analysis affords important steering for practitioners in dense and sparse retrieval, offering a complete analysis of the trade-offs between HNSW, flat, and inverted indexes. The findings recommend that HNSW indexes are well-suited for large-scale retrieval duties resulting from their effectivity in dealing with queries, whereas flat indexes are perfect for smaller datasets and fast prototyping resulting from their simplicity and accuracy. By offering empirically-backed suggestions, this work considerably contributes to the understanding and optimization of contemporary info retrieval techniques, serving to practitioners make knowledgeable selections for AI-driven search purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


