

: An Unsupervised Technique for Pretraining Imaginative and prescient-Language-Motion (VLA) Fashions with out Floor-Reality Robotic Motion Labels")
Imaginative and prescient-Language-Motion Fashions (VLA) for robotics are skilled by combining giant language fashions with imaginative and prescient encoders after which fine-tuning them on numerous robotic datasets; this permits generalization to new directions, unseen objects, and distribution shifts. Nevertheless, numerous real-world robotic datasets principally require human management, which makes scaling tough. However, Web video knowledge affords many examples of human habits and bodily interactions at scale, presenting a greater strategy to beat the constraints of small, specialised robotic datasets. Additionally, studying from web movies is a bit robust for 2 causes: most on-line movies don’t have clear labels for his or her corresponding actions, and the conditions proven in internet movies are very totally different from the environments that robots work in.
Imaginative and prescient-Language Fashions (VLMs), skilled on intensive internet-scale datasets encompassing textual content, picture, and video, have demonstrated understanding and producing text-to-print and multimodal knowledge. Lately, incorporating auxiliary targets, corresponding to visible traces, language reasoning paths, or developing a conversational-style instruction dataset utilizing robotic trajectory knowledge throughout VLA coaching has improved efficiency. Nevertheless, these strategies nonetheless closely depend on labeled motion knowledge, which limits the scalability of creating normal VLAs since they are going to be bounded by the quantity of robotic knowledge made obtainable by human teleoperation. Coaching Robotic Insurance policies from Movies include wealthy details about dynamics and habits, which could be doubtlessly useful for robotic studying. Some latest works discover the advantages of video generative fashions pre-trained on human movies for downstream robotic duties. One other line of labor goals to be taught helpful info from human movies by studying from interactions, affordances, or visible traces extracted from human movies. One other line of labor goals to be taught robotic manipulation insurance policies by retargeting human motions to robotic motions. These works depend on off-the-shelf fashions corresponding to hand pose estimators or movement seize methods to retarget the human motions on to robotic motions. Current strategies for coaching robots are both task-specific or require completely mixed human-robot knowledge, limiting their generalization of it. Some approaches label giant datasets with small quantities of action-labeled knowledge to coach robots, however they nonetheless have points with scaling based on the necessity.
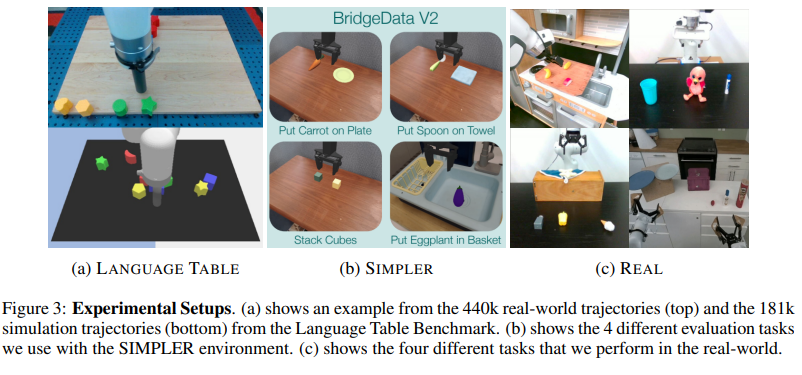
The researchers from the KAIST, College of Washington, Microsoft Analysis, NVIDIA, and Allen Institute for AI proposed Latent Motion Pre Coaching for Basic Motion fashions (LAPA), an unsupervised technique that leverages internet-scale movies with out robotic motion labels. They proposed this technique to be taught from internet-scale movies that do not need robotic motion labels. LAPA includes coaching an motion quantization mannequin leveraging VQ-VAE-based goal to be taught discrete latent actions between picture frames, then pre-train a latent VLA mannequin to foretell these latent actions from observations and job descriptions, and eventually fine-tune the VLA on small-scale robotic manipulation knowledge to map from latent to robotic actions. Experimental outcomes reveal that the tactic proposed considerably outperforms present methods that prepare robotic manipulation insurance policies from large-scale movies. Moreover, it outperforms the state-of-the-art VLA mannequin skilled with robotic motion labels on real-world manipulation duties that require language conditioning, generalization to unseen objects, and semantic generalization to unseen directions.
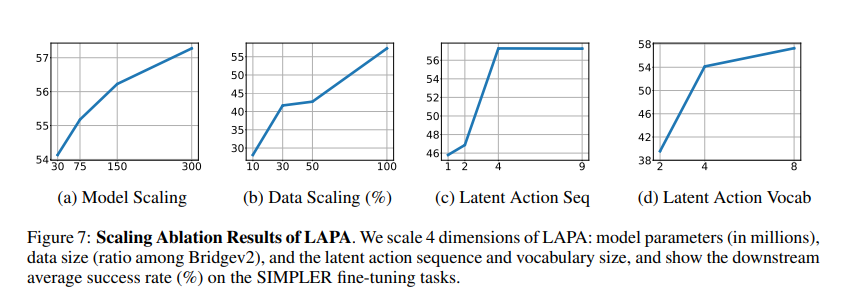
LAPA consists of two pretraining levels adopted by fine-tuning to attach latent actions to actual robotic actions. Within the first stage, a VQ-VAE-based technique is used to interrupt down actions into smaller, primary elements with no need any set classes for these actions. The second stage includes habits cloning, the place a Imaginative and prescient-Language Mannequin predicts latent actions from video observations and job descriptions. The mannequin is then fine-tuned on a small robotic manipulation dataset to be taught the mapping from latent to robotic actions. LAPA, which stands for the proposed Imaginative and prescient-Language-Motion (VLA) mannequin, outperforms the earlier greatest mannequin, OPENVLA, regardless of being skilled solely on human manipulation movies. It exhibits higher efficiency than bigger robotic datasets like Bridgev2 and is 30-40 instances extra environment friendly in pretraining, utilizing solely 272 H100 hours in comparison with OPENVLA’s 21,500 A100-hours. LAPA’s efficiency advantages from bigger fashions and datasets, however there are diminishing returns at sure scales. Moreover, it aligns nicely with actual actions, proving efficient in duties involving human manipulation. Furthermore, simulations reveal LAPA’s capacity to plan robotic actions primarily based on easy directions, highlighting its potential to be used in advanced robotic methods. LAPA considerably improves robotic efficiency in duties, each in simulations and real-world situations, in comparison with earlier strategies that additionally depend on unlabeled video. It even outperforms the present greatest mannequin that makes use of labeled actions by 6.22%, and it’s over 30 instances extra environment friendly in pretraining.
In conclusion, LAPA is a scalable pre-training technique for constructing VLAs utilizing actionless movies. Throughout three benchmarks spanning each simulation and real-world robotic experiments, it confirmed that this technique considerably improves switch to downstream duties in comparison with present approaches. It additionally introduced a state-of-the-art VLA mannequin that surpasses present fashions skilled on 970K action-labeled trajectories. Moreover, it demonstrated that LAPA might be utilized purely to human manipulation movies, the place express motion info is absent, and the embodiment hole is substantial.
Regardless of these distinctive options, LAPA underperforms in comparison with motion pretraining relating to fine-grained movement era duties like greedy. Rising the latent motion era area may assist handle this concern. Second, just like prior VLAs, LAPA additionally encounters latency challenges throughout real-time inference. Adopting a hierarchical structure, the place a smaller head predicts actions at a better frequency, may doubtlessly cut back latency and enhance fine-grained movement era. LAPA exhibits digital camera actions however hasn’t been examined past manipulation movies, like in self-driving automobiles or navigation. This work could be expanded to create scalable robotic fashions and assist future analysis.
Take a look at the Paper, Mannequin Card on HuggingFace, and Venture Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Fantastic-Tuned Fashions: Predibase Inference Engine (Promoted)
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science diploma on the Indian Institute of Expertise (IIT) Kharagpur. She has a deep ardour for Knowledge Science and actively explores the wide-ranging functions of synthetic intelligence throughout numerous industries. Fascinated by technological developments, Nazmi is dedicated to understanding and implementing cutting-edge improvements in real-world contexts.


