


Mathematical reasoning inside synthetic intelligence has emerged as a focal space in growing superior problem-solving capabilities. AI can revolutionize scientific discovery and engineering fields by enabling machines to method high-stakes logical challenges. Nonetheless, advanced duties, particularly Olympiad-level mathematical reasoning, proceed to stretch AI’s limits, demanding superior search strategies to navigate resolution areas successfully. Current strides have introduced some success in reasoning, but intricate duties like multi-step mathematical proofs nonetheless should be solved. This want for high-precision, environment friendly reasoning pathways motivates ongoing analysis to reinforce the accuracy and reliability of AI fashions in mathematical contexts.
One main problem is the event of correct step-by-step resolution paths that AI can use for advanced problem-solving. Typical strategies usually fail to make sure resolution accuracy, particularly for multi-step, high-difficulty questions. These strategies depend on Chain-of-Thought (CoT) processing, the place options are damaged down into smaller steps, theoretically bettering accuracy. Nonetheless, CoT and its variants need assistance with duties requiring deep logical consistency throughout a number of steps, resulting in errors and inefficiencies. The lack to optimize resolution paths limits the AI’s capability to resolve advanced mathematical issues, highlighting the necessity for extra refined approaches.
A number of strategies, together with Monte Carlo Tree Search (MCTS), Tree-of-Thought (ToT), and Breadth-First Search (BFS), have been developed to deal with these points. MCTS and ToT, as an illustration, purpose to enhance reasoning by permitting iterative path exploration. Nonetheless, their grasping search mechanisms can entice the AI in domestically optimum however globally suboptimal options, considerably reducing the accuracy of advanced reasoning duties. Whereas these approaches present a foundational construction for resolution search, they usually need assistance with the vastness of potential resolution areas in high-level arithmetic, in the end constraining their effectiveness.
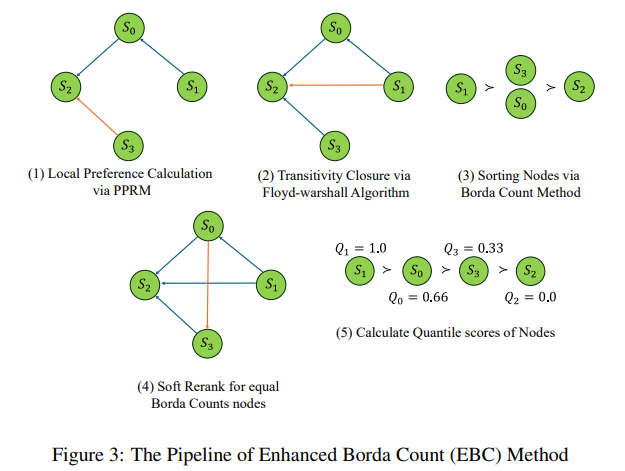
The analysis workforce from Fudan College, Shanghai Synthetic Intelligence Laboratory, College of California Merced, Hong Kong Polytechnic College, College of New South Wales, Shanghai Jiao Tong College, and Stanford College launched a pioneering framework known as LLaMA-Berry to beat these challenges. LLaMA-Berry integrates Monte Carlo Tree Search with an revolutionary Self-Refine (SR) optimization method that permits environment friendly exploration and enchancment of reasoning paths. The framework makes use of the Pairwise Choice Reward Mannequin (PPRM), which assesses resolution paths by evaluating them towards each other as an alternative of assigning absolute scores. This method permits for a extra dynamic analysis of options, optimizing total problem-solving efficiency as an alternative of focusing solely on particular person steps.
In LLaMA-Berry, the Self-Refine mechanism treats every resolution as a whole state, with MCTS guiding iterative refinements to achieve an optimum consequence. This methodology incorporates a multi-step course of involving Choice, Enlargement, Analysis, and Backpropagation phases to stability exploration and exploitation of resolution paths. In the course of the Analysis section, the PPRM calculates scores primarily based on a comparative rating. By making use of an Enhanced Borda Rely (EBC) methodology, the researchers can combination preferences throughout a number of options to determine essentially the most promising paths. PPRM permits for extra nuanced decision-making and prevents the AI from overcommitting to any single flawed pathway.
Testing on difficult benchmarks has proven that LLaMA-Berry outperforms present fashions in fixing Olympiad-level issues. For example, on the AIME24 benchmark, the framework achieved a efficiency increase of over 11% in comparison with prior strategies, with an accuracy of 55.1% on Olympiad duties, marking a big enchancment in dealing with college-level arithmetic. Its success in these duties signifies that the framework successfully manages advanced reasoning with out requiring in depth coaching. This enchancment underscores LLaMA-Berry’s capability to deal with reasoning-heavy duties extra reliably than earlier fashions, showcasing a flexible, scalable resolution for advanced AI functions.
Probably the most important discovering in LLaMA-Berry’s analysis is its effectivity in mathematical reasoning duties as a result of integration of Self-Refine and the Pairwise Choice Reward Mannequin. Benchmarks equivalent to GSM8K and MATH confirmed LLaMA-Berry outperforming open-source opponents, attaining accuracy ranges beforehand solely attainable with massive proprietary fashions like GPT-4 Turbo. For GSM8K, LLaMA-Berry reached 96.1% with restricted simulations, providing excessive effectivity in rollouts with fewer computational assets. These outcomes illustrate the robustness and scalability of LLaMA-Berry in superior benchmarks with out in depth coaching.
Key Takeaways from the Analysis on LLaMA-Berry:
- Benchmark Success: LLaMA-Berry achieved notable accuracy enhancements, equivalent to 96.1% on GSM8K and 55.1% on Olympiad-level duties.
- Comparative Analysis: The PPRM permits extra nuanced analysis by means of Enhanced Borda Rely, balancing native and world resolution preferences.
- Environment friendly Answer Paths: Self-Refine mixed with Monte Carlo Tree Search (MCTS) optimizes reasoning paths, avoiding pitfalls of conventional grasping search strategies.
- Useful resource Effectivity: LLaMA-Berry outperformed open-source fashions utilizing fewer simulations, attaining 11% to 21% enhancements on advanced benchmarks.
- Scalability and Adaptability: The framework reveals potential to broaden past mathematical reasoning, providing applicability in multimodal AI duties throughout scientific and engineering fields.

In conclusion, LLaMA-Berry represents a considerable development in AI, particularly for tackling advanced reasoning in arithmetic. The framework achieves accuracy and effectivity by leveraging Self-Refine with MCTS and PPRM, surpassing typical fashions on Olympiad-level benchmarks. This framework’s scalable method positions it as a promising software for high-stakes AI functions, suggesting potential adaptability to different advanced reasoning fields, equivalent to physics and engineering.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An Intensive Assortment of Small Language Fashions (SLMs) for Intel PCs
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.

