


A big problem within the subject of synthetic intelligence is to facilitate massive language fashions (LLMs) to generate 3D meshes from textual content descriptions instantly. Standard strategies limit LLMs from working as text-based elements and take away multimodal workflows that mix textual and 3D content material creation. A lot of the present frameworks require extra architectures or large computational assets, making them tough to make use of in real-time, interactive environments like video video games, digital actuality, and industrial design, for instance. Missing unified techniques that colloquially mix textual content understanding and 3D era additional complicates environment friendly and accessible 3D content material creation. In distinction, the options to such issues would possibly change the panorama of multimodal AI and make 3D design workflows extra intuitive and scalable.
Current approaches to 3D era may be broadly categorized into auto-regressive fashions and score-distillation strategies. Auto-regressive fashions like MeshGFT and PolyGen tokenize 3D mesh information and use transformers to create object meshes. They carry out properly however have been skilled from scratch and don’t include any integration of pure language; moreover this, they require big computational assets. Rating-distillation strategies comprise DreamFusion and Magic3D; they use a single pre-trained diffusion mannequin for creating objects. These strategies depend on intermediate representations corresponding to signed distance fields or voxel grids, which embrace extra processing and are computationally costly and, subsequently, should not very environment friendly for real-time purposes. Neither kind permits the flexibleness wanted to simply insert text-based and 3D era capabilities inside a unified, environment friendly framework.
NVIDIA and Tsinghua College researchers introduce LLAMA-MESH, the first-ever framework combining the representations of textual content and 3D modalities right into a single structure. The text-based OBJ file format encodes 3D meshes in plain textual content, consisting of vertex coordinates and face definitions. As a result of there’s neither the necessity to broaden token vocabularies nor to change tokenizers, the design cuts computational price; by utilizing spatial data and mixing that with the LLMs’ conditioned basis, LLAMA-MESH permits customers to generate 3D content material instantly from textual content prompts. Its coaching on an editorial dataset of interleaved text-3D dialogues permits for producing capabilities, together with the interpretation and outline of 3D meshes in pure language. Moreover, its integration eliminates separate architectures and, therefore renders the framework extremely environment friendly and versatile for conducting multimodal duties.
Meshes are encoded within the OBJ format, with vertex coordinates and face definitions transformed into plain textual content sequences. Quantization is utilized to vertex coordinates to scale back the size of the token sequences with out compromising the geometric constancy for compatibility with the LLM context window. Wonderful-tuning takes place over a dataset developed from Objaverse, that comprises over 31,000 curated meshes, prolonged to 125,000 samples by means of information augmentation. Captions are produced with Cap3D whereas the richness of dialogue buildings is set primarily based on rule-based patterns in addition to LLM augmentation strategies. It was fine-tuned on 32 A100 GPUs for 21,000 iterations utilizing a mixture of mesh era, mesh understanding, and conversational duties. The used structure is LLaMA 3.1-8B-Instruct, offering a great initialization when combining the textual content and 3D modalities.
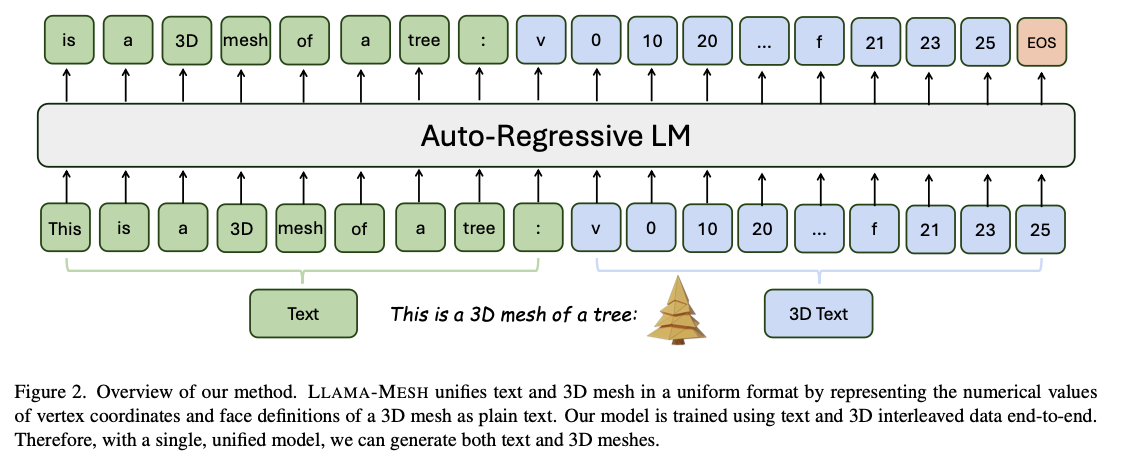
LLAMA-MESH achieves excellent efficiency: creates numerous, high-quality 3D meshes with artist-like topology whereas outperforming conventional approaches when it comes to computational effectivity on the stability of multimodal duties, with sound language understanding and reasoning capabilities. The structure seems stronger for text-to-3D era, confirmed in real-world design and interactive atmosphere purposes. That’s, end-to-end integration of textual content understanding and 3D creation was enabled; it’s a vital development in multimodal AI.
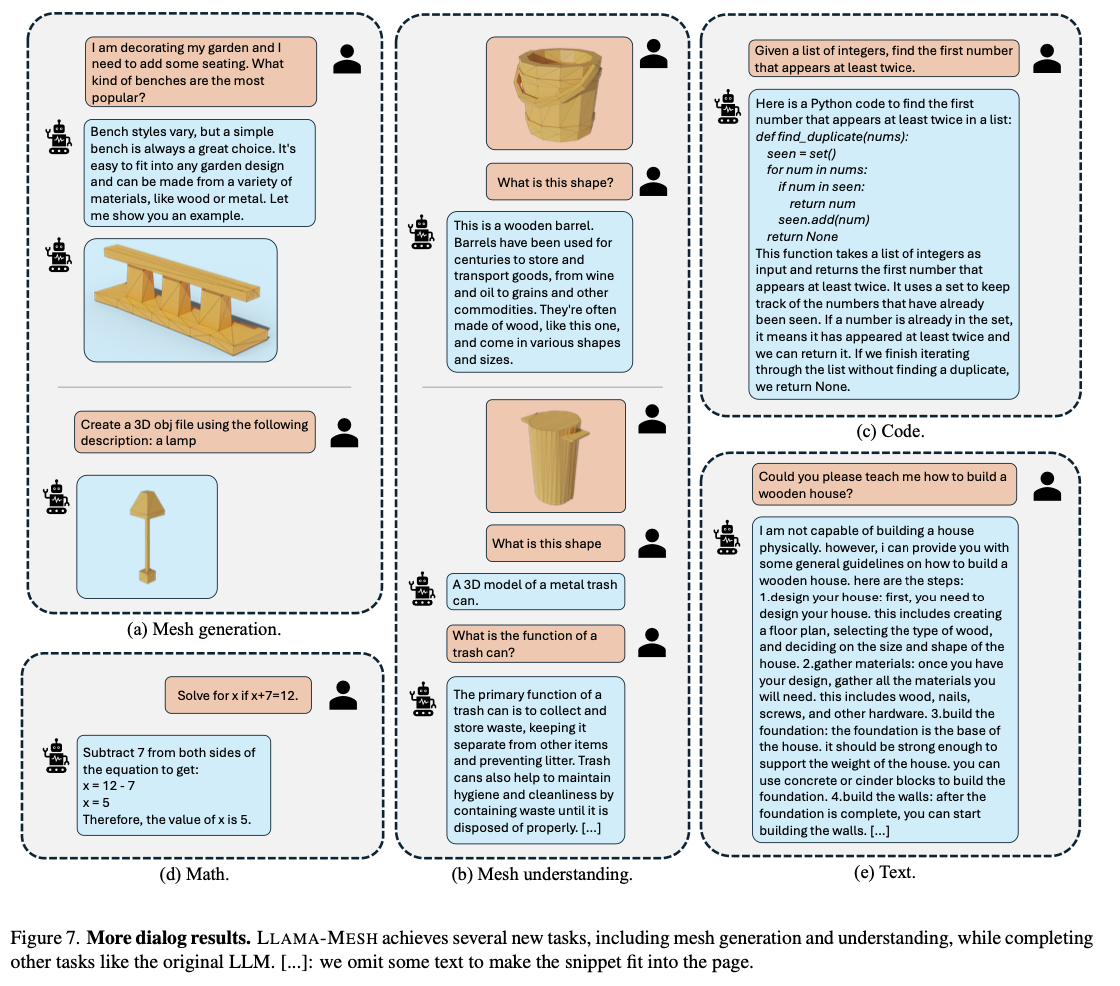

By bridging the hole between textual and 3D modalities, LLAMA-MESH presents an environment friendly and unified resolution for producing and deciphering 3D meshes instantly from textual prompts. Equally well-suited outcomes like such that might be produced by means of specialised 3D fashions, a power of that is regarded as as sturdy a language-awareness skill. This work has unlocked new methods and avenues towards extra intuitive, language-driven approaches to 3D workflows and has made large adjustments in gaming, digital actuality, and industrial design purposes.
Try the Paper and Mission. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Providers and Actual Property Transactions– From Framework to Manufacturing
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.

