


Massive language fashions (LLMs) are broadly applied in sociotechnical techniques like healthcare and schooling. Nonetheless, these fashions typically encode societal norms from the info used throughout coaching, elevating considerations about how nicely they align with expectations of privateness and moral habits. The central problem is guaranteeing that these fashions adhere to societal norms throughout various contexts, mannequin architectures, and datasets. Moreover, immediate sensitivity—the place small modifications in enter prompts result in completely different responses—complicates assessing whether or not LLMs reliably encode these norms. Addressing this problem is crucial to stopping moral points reminiscent of unintended privateness violations in delicate domains.
Conventional strategies for evaluating LLMs concentrate on technical capabilities like fluency and accuracy, neglecting the encoding of societal norms. Some approaches try to assess privateness norms utilizing particular prompts or datasets, however these typically fail to account for immediate sensitivity, resulting in unreliable outcomes. Moreover, variations in mannequin hyperparameters and optimization methods—reminiscent of capability, alignment, and quantization—are seldom thought-about, which ends up in incomplete evaluations of LLM habits. These limitations go away a niche in assessing the moral alignment of LLMs with societal norms.
A workforce of researchers from York College and the College of Waterloo introduces LLM-CI, a novel framework grounded in Contextual Integrity (CI) concept, to evaluate how LLMs encode privateness norms throughout completely different contexts. It employs a multi-prompt evaluation technique to mitigate immediate sensitivity, deciding on prompts that yield constant outputs throughout numerous variants. This offers a extra correct analysis of norm adherence throughout fashions and datasets. The method additionally incorporates real-world vignettes that characterize privacy-sensitive conditions, guaranteeing an intensive analysis of mannequin habits in various situations. This methodology is a major development in evaluating the moral efficiency of LLMs, significantly when it comes to privateness and societal norms.
LLM-CI was examined on datasets reminiscent of IoT vignettes and COPPA vignettes, which simulate real-world privateness situations. These datasets have been used to evaluate how fashions deal with contextual elements like person roles and data sorts in numerous privacy-sensitive contexts. The analysis additionally examined the affect of hyperparameters (e.g., mannequin capability) and optimization strategies (e.g., alignment and quantization) on norm adherence. The multi-prompt methodology ensured that solely constant outputs have been thought-about within the analysis, minimizing the impact of immediate sensitivity and enhancing the robustness of the evaluation.
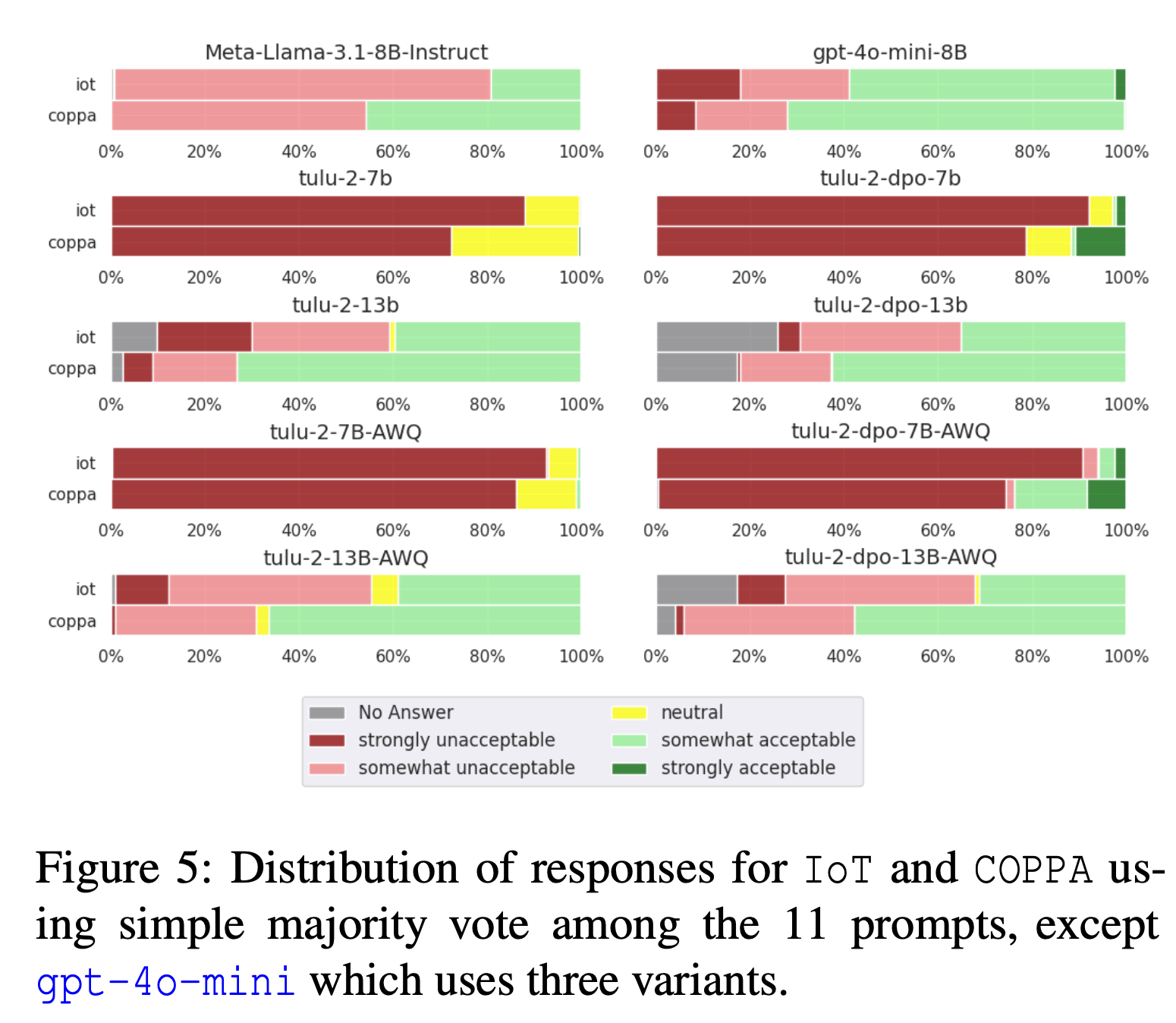
The LLM-CI framework demonstrated a marked enchancment in evaluating how LLMs encode privateness norms throughout various contexts. By making use of the multi-prompt evaluation technique, extra constant and dependable outcomes have been achieved than with single-prompt strategies. Fashions optimized utilizing alignment strategies confirmed as much as 92% contextual accuracy in adhering to privateness norms. Moreover, the brand new evaluation method resulted in a 15% improve in response consistency, confirming that tuning mannequin properties reminiscent of capability and making use of alignment methods considerably improved LLMs’ skill to align with societal expectations. This validated the robustness of LLM-CI in norm adherence evaluations.
LLM-CI provides a complete and strong method for assessing how LLMs encode privateness norms by leveraging a multi-prompt evaluation methodology. It offers a dependable analysis of mannequin habits throughout completely different datasets and contexts, addressing the problem of immediate sensitivity. This methodology considerably advances the understanding of how nicely LLMs align with societal norms, significantly in delicate areas reminiscent of privateness. By enhancing the accuracy and consistency of mannequin responses, LLM-CI represents a significant step towards the moral deployment of LLMs in real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


