


Multimodal Artwork Projection (M-A-P) researchers have launched FineFineWeb, a big open-source computerized classification system for fine-grained net knowledge. The mission decomposes the deduplicated Fineweb into 67 distinctive classes with intensive seed knowledge. Furthermore, a complete correlation evaluation between vertical classes and customary benchmarks and detailed URL and content material distribution evaluation are carried out. The system gives specialised check units for PPL analysis, that includes each “small cup” validation and “medium cup” check choices. Full coaching supplies for FastText and Bert implementation accompany the dataset, with upcoming strategies for knowledge proportioning primarily based on RegMix methodology.
The info development course of for FineFineWeb follows a scientific multi-step workflow. The preliminary deduplication of FineWeb employs precise deduplication and MinHash strategies. URL labeling makes use of GPT-4 to course of the highest million root URLs, categorizing them into Area-of-Curiosity (DoI) and Area-of-Non-Curiosity (DoNI) URLs. Additional, the coarse recall part entails domain-specific sampling primarily based on the labeled root URLs, with Qwen2-7B-Instruct dealing with the labeling of 500K constructive and unfavorable knowledge factors. FastText fashions, educated on this labeled knowledge, carry out coarse recall operations throughout FineWeb to generate Coarse DoI Knowledge.
The high-quality recall stage advances the info refinement course of utilizing Qwen2-72B-Instruct to label the Coarse DoI Knowledge, creating 100K Dol constructive and 100K Dol unfavorable knowledge factors. After that, a BERT mannequin, educated on this labeled knowledge, performs high-quality recall to supply the ultimate DoI subset of FineFineWeb. Furthermore, the whole coarse-fine recall iteration undergoes three rounds with particular modifications:
- FastText is re-trained utilizing up to date seed knowledge, which mixes BERT-recalled samples, BERT-dropped samples, and beforehand labeled seed knowledge.
- The BERT mannequin retains frozen throughout subsequent iterations.
- Steps for coaching FastText, coarse recall, and high-quality recall are repeated with out re-labeling knowledge with Qwen2-Instruct fashions.
The domain-domain similarity Evaluation employs a classy analytical strategy utilizing proportional weighted sampling throughout area subsets, processing one billion tokens from the area subsets. Then the BGE-M3 mannequin is used to generate two varieties of embeddings: area embeddings from area subset samples and benchmark embeddings from benchmark samples. The evaluation concludes by calculating MMD and Wasserstein distances between area embeddings and benchmark embeddings to quantify area relationships.
The similarity evaluation reveals a number of key patterns in domain-benchmark relationships. Code-related benchmarks (MBPP and HumanEval) present vital distance from most domains besides arithmetic, indicating restricted code illustration within the dataset. Common information benchmarks (Hellaswag, ARC, MMLU, BoolQ) display shut relationships with a number of domains, suggesting broad information distribution, whereas excluding playing content material. Furthermore, GSM8K and TriviaQA exhibit notable domain-specific variations, significantly in arithmetic and factual content material. Lastly, the playing area stands distinctly separate, displaying minimal overlap with different domains and benchmarks.
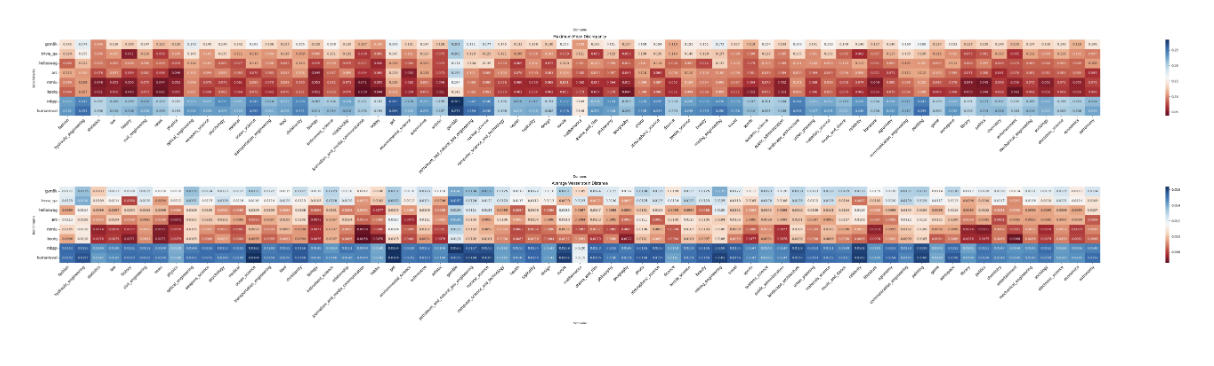
The domain-domain duplication evaluation examines URL uniqueness throughout domains utilizing TF-IDF values. Excessive TF-IDF scores point out domain-specific distinctive URLs, whereas low values counsel frequent URLs throughout domains. The evaluation reveals minimal duplication throughout most domains, with exceptions in topicality, pet, and atmospheric science classes. The domain-benchmark correlation research, carried out throughout 28 fashions, compares domain-specific efficiency (BPC) rankings with benchmark efficiency rankings utilizing Spearman correlation. STEM-related domains present stronger correlations with reasoning-focused benchmarks (ARC, MMLU, GSM8K, HumanEval, MBPP), whereas knowledge-intensive domains like literature and historical past correlate increased with fact-based benchmarks like TriviaQA.
Try the Dataset and Tweet. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….

Sajjad Ansari is a closing 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a give attention to understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


