


Deploying machine studying fashions on edge units poses vital challenges on account of restricted computational assets. When the scale and complexity of fashions enhance, even attaining environment friendly inference turns into difficult. Purposes reminiscent of autonomous automobiles, AR glasses, and humanoid robots require low-latency and memory-efficient operations. In such functions, present approaches fail to deal with even the computational and reminiscence overhead led to by intricate architectures reminiscent of transformers or basis fashions, making real-time, resource-aware inference a crucial want.
To beat these challenges, researchers have developed strategies reminiscent of pruning, quantization, and information distillation to scale back mannequin measurement and system-level strategies like operator fusion and fixed folding. Though efficient in particular eventualities, such approaches typically deal with single optimizations, ignoring the potential of collectively optimizing the complete computational graphs. Conventional reminiscence administration strategies in customary frameworks pay little respect to the connections and configurations of the up to date neural networks, resulting in a lot lower than optimum efficiency in large-scale functions.
FluidML is an progressive framework for inference optimization that holistically transforms mannequin execution blueprints. It focuses on graph-operator integration together with streamlining reminiscence layouts throughout computational graphs, makes use of dynamic programming for environment friendly scheduling at runtime, and the technique of superior entry to reminiscence reminiscent of loop reordering for computationally demanding duties reminiscent of matrix multiplication. FluidML offers end-to-end cross-platform compatibility by utilizing a entrance finish primarily based on ONNX and compilation primarily based on LLVM to help many operators and infers effectively for many functions.
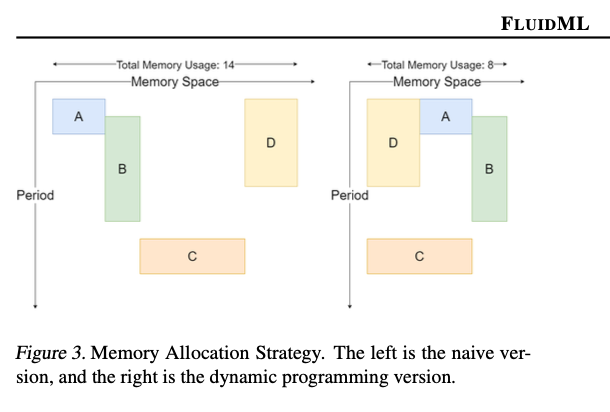
FluidML makes use of superior strategies to reinforce inference execution. It identifies the longest computational sequences in a graph and segments them into subgraphs for recursive optimization utilizing dynamic programming. Environment friendly reminiscence layouts are scheduled for execution sequences and conflicts are resolved utilizing dependency-based voting mechanisms. FluidML is constructed on prime of each MLIR and LLVM IR which permits seamless inclusion inside current workflows to attenuate overhead whereas maximizing efficiency. It will enhance utilization of the cache and time to finish memory-intensive operations reminiscent of matrix multiplication and convolution.
FluidML delivered vital efficiency enhancements, attaining as much as 25.38% discount in inference latency and as much as 41.47% discount in peak reminiscence utilization throughout a number of {hardware} platforms. These enhancements had been constant throughout fashions, starting from transformer-based language fashions like BERT and GPT-NEOX to imaginative and prescient fashions like VGG. By means of a streamlined reminiscence format technique and optimized execution of computationally costly operations, FluidML established superiority as compared with the state-of-the-art ONNX-MLIR and Apache TVM, making it a sturdy, environment friendly resolution for resource-constrained environments.
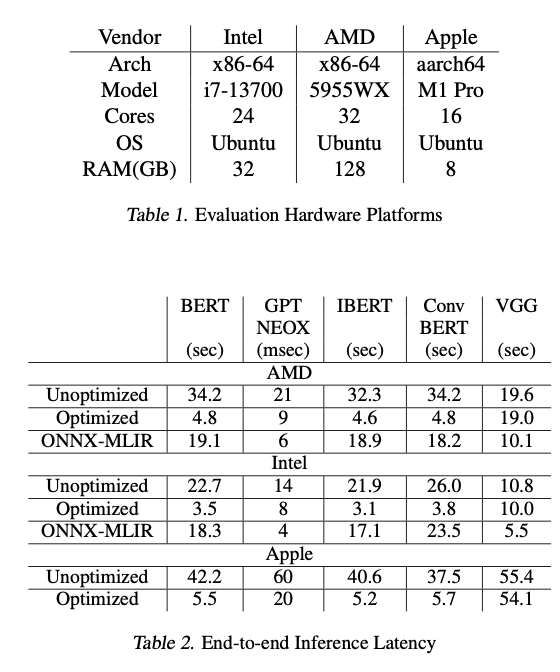
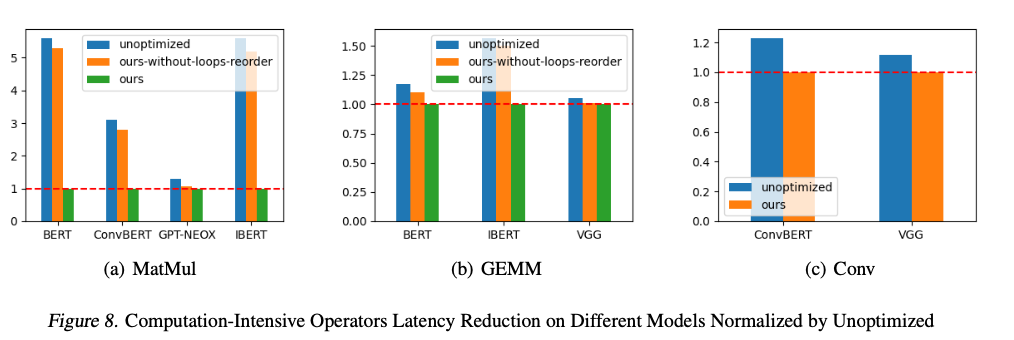
In conclusion, FluidML offers context for the revolutionary optimization of inference run time and reminiscence use in edge computing environments. The holistic design integrates in a single coherent piece memory-layout optimization, graph segmentation, and superior scheduling strategies, a few of which fill a niche left by present options. Enormous latency and reminiscence effectivity features assist in the real-time deployment of complicated machine studying fashions even in extremely resource-constrained use instances.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Digital GenAI Convention ft. Meta, Mistral, Salesforce, Harvey AI & extra. Be part of us on Dec eleventh for this free digital occasion to study what it takes to construct large with small fashions from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and extra.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


