


Imaginative and prescient-Language Fashions (VLMs) enable machines to know and purpose in regards to the visible world by way of pure language. These fashions have functions in picture captioning, visible query answering, and multimodal reasoning. Nevertheless, most fashions are designed and skilled predominantly for high-resource languages, leaving substantial gaps in accessibility and value for audio system of low-resource languages. This hole highlights the significance of growing multilingual programs that cater to a world viewers whereas sustaining excessive efficiency throughout numerous linguistic and cultural contexts. Nevertheless, a priority in growing multilingual VLMs lies within the availability and high quality of multilingual datasets.
Even when there are datasets, they’ve these limitations:
- Current pretraining datasets, similar to COCO, Visible Genome, and LAION, are overwhelmingly centered on English, limiting their generalization means throughout languages and cultures.
- Many datasets additionally include poisonous or biased content material, perpetuating stereotypes and undermining the moral deployment of AI programs.
The restricted illustration of numerous languages, mixed with the presence of culturally insensitive materials, hampers the efficiency of VLMs in underrepresented areas and raises considerations about equity and inclusivity.
Researchers have turned to numerous strategies of dataset growth and high quality enchancment to handle these limitations. For instance, datasets like Multi30k and Crossmodal-3600 have tried to offer multilingual assist however should be expanded in scale and variety. Semi-automated translations of image-text datasets have been used to increase language protection in fashions similar to PALO and X-LLaVA. Nevertheless, these efforts typically lead to uneven distributions throughout languages and fail to handle the toxicity current within the unique information. The shortage of systematic approaches to filtering dangerous content material additional worsens the difficulty.
A group of researchers from Cisco Meraki, Cohere For AI Group, Indiana College Bloomington, Imperial School London, Georgia Institute of Expertise, The Alan Turing Institute, Bangladesh College of Engineering and Expertise, College of Pennsylvania, IIT Bombay, TU Darmstadt, Articul8 AI, Capital One, IIT Dhanbad, and MBZUAI launched Maya, an 8B parameters open-source multilingual multimodal vision-language mannequin that goals to beat current dataset high quality and toxicity limitations. The mannequin leverages a brand new pretraining dataset containing 558,000 image-text pairs distributed equally throughout eight languages: English, Chinese language, French, Spanish, Russian, Hindi, Japanese, and Arabic. This dataset underwent rigorous toxicity filtering, with over 7,531 poisonous photos and captions eliminated utilizing instruments like LLaVAGuard and Poisonous-BERT. Maya’s growth additionally centered on balancing information distribution to forestall biases.
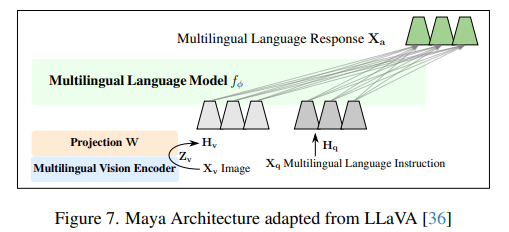
Maya’s structure is constructed on the LLaVA framework and incorporates superior strategies for image-text alignment and multilingual adaptation. The mannequin employs SigLIP, a imaginative and prescient encoder able to dealing with variable enter dimensions, and Aya-23, a multilingual language mannequin skilled throughout 23 languages. A two-layer projection matrix bridges picture options to language options, optimizing efficiency whereas sustaining computational effectivity. Pretraining was performed on 8xH100 GPUs with a world batch measurement of 256; instruction fine-tuning utilized the PALO 150K dataset. This coaching course of was designed to make sure high-quality outputs, with pretraining taking roughly 20 hours and fine-tuning requiring 48 hours.
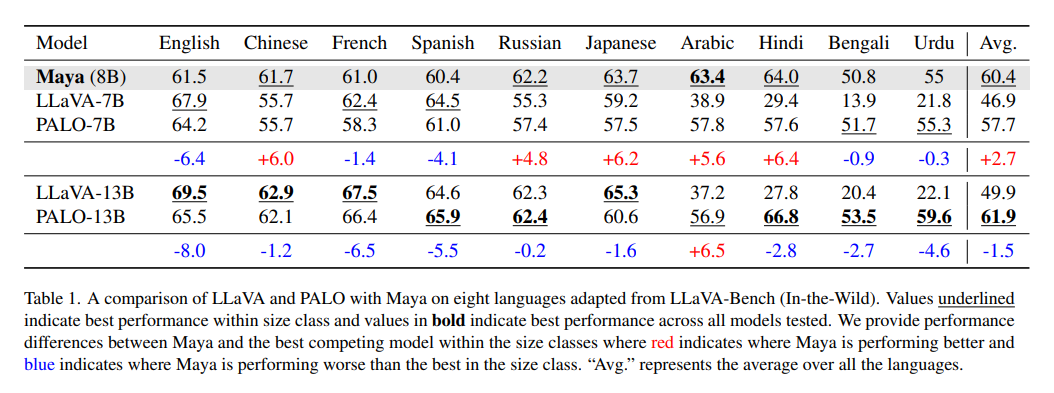
Efficiency-wise, on multilingual benchmarks similar to LLaVA-Bench-In-The-Wild, Maya outperformed similar-size fashions like LLaVA-7B and PALO-7B in 5 out of eight languages, together with notable success in Arabic attributable to its sturdy translation and dataset design. Throughout English-only benchmarks, Maya maintained aggressive accuracy, with marginal features noticed in duties like textual content translation and numerical calculation for the toxicity-free variant. Nevertheless, some advanced reasoning duties confirmed slight efficiency declines, indicating that eradicating numerous, probably poisonous content material might influence sure capabilities.
Some key takeaways and highlights from the Maya mannequin analysis are summarized beneath:
- Maya’s pretraining dataset contains 558,000 image-text pairs expanded to 4.4 million samples throughout eight languages. Rigorous toxicity filtering eliminated 7,531 poisonous components, guaranteeing cleaner information.
- The mannequin helps eight languages, attaining balanced information distribution and cultural inclusivity by way of optimized translation and pretraining methods.
- SigLIP for imaginative and prescient encoding and Aya-23 for multilingual language modeling allow high-quality image-text alignment and cross-linguistic comprehension.
- Maya outperformed comparable fashions in 5 languages and matched bigger fashions in a number of benchmarks.
- Maya units a precedent for moral and truthful AI practices by addressing toxicity and biases.
In conclusion, by introducing Maya, the analysis addresses restricted multilingual and culturally delicate datasets in VLMs. This mannequin combines an modern dataset of 558,000 image-text pairs throughout eight languages with rigorous toxicity filtering and balanced illustration to make sure inclusivity and moral deployment. Leveraging superior structure and multilingual adaptation strategies, Maya outperforms similar-size fashions in a number of languages, setting a brand new customary for multilingual AI.
Take a look at the Paper and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our e-newsletter to get trending AI analysis and dev updates
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


