


Massive Language Fashions (LLMs) have revolutionized numerous domains, with a very transformative impression on software program growth by code-related duties. The emergence of instruments like ChatGPT, Copilot, and Cursor has essentially modified how builders work, showcasing the potential of code-specific LLMs. Nonetheless, a big problem persists in creating open-source code LLMs, as their efficiency constantly lags behind state-of-the-art fashions. This efficiency hole primarily stems from the proprietary coaching datasets utilized by main LLM suppliers, who keep strict management over these essential sources. The shortage of entry to high-quality coaching information creates a considerable barrier for the broader analysis neighborhood, hindering their capability to ascertain sturdy baselines and develop a deeper understanding of how top-performing code LLMs perform.
Earlier analysis efforts in code language modeling have taken numerous approaches to advance AI purposes in software program engineering. Proprietary fashions have demonstrated spectacular efficiency enhancements throughout a number of code-related benchmarks, however their closed nature considerably restricts additional innovation. The analysis neighborhood has responded by creating open-source options similar to CodeGen, StarCoder, CodeLlama, and DeepSeekCoder, which have helped foster continued development within the discipline. These fashions have been evaluated throughout numerous benchmarks, together with code retrieval, translation, effectivity evaluation, and repository-level code completion duties. Just lately, there was a big push in direction of open-source LLMs, with initiatives like LLaMA, Mistral, Qwen, and ChatGLM releasing not solely mannequin checkpoints but in addition complete coaching datasets. Significantly noteworthy are totally open initiatives similar to OLMo and StarCoderV2, which give intensive documentation of their coaching processes, information pipelines, and intermediate checkpoints, selling transparency and reproducibility within the discipline.
Researchers from INF and M-A-P current OpenCoder, a strong initiative designed to handle the transparency hole in code-specific language fashions by three major goals. The challenge goals to supply researchers with a totally clear baseline code LLM for learning mechanical interpretability and information distribution patterns, conduct complete investigations into pretrain and instruction information curation methodologies, and allow personalized options by detailed mannequin growth insights. The analysis reveals essential design selections in information curation throughout totally different coaching levels, emphasizing the significance of thorough information cleansing, efficient deduplication methods on the file degree, and cautious consideration of GitHub star metrics. A major discovering signifies that high-quality information turns into more and more essential throughout the annealing section, whereas a two-stage instruction tuning strategy proves significantly efficient for creating broad capabilities adopted by code-specific refinements. This complete strategy positions OpenCoder as a totally open-source Code LLM, constructed on clear processes and reproducible datasets, aimed toward advancing the sector of code intelligence research.
Pre-Coaching Information
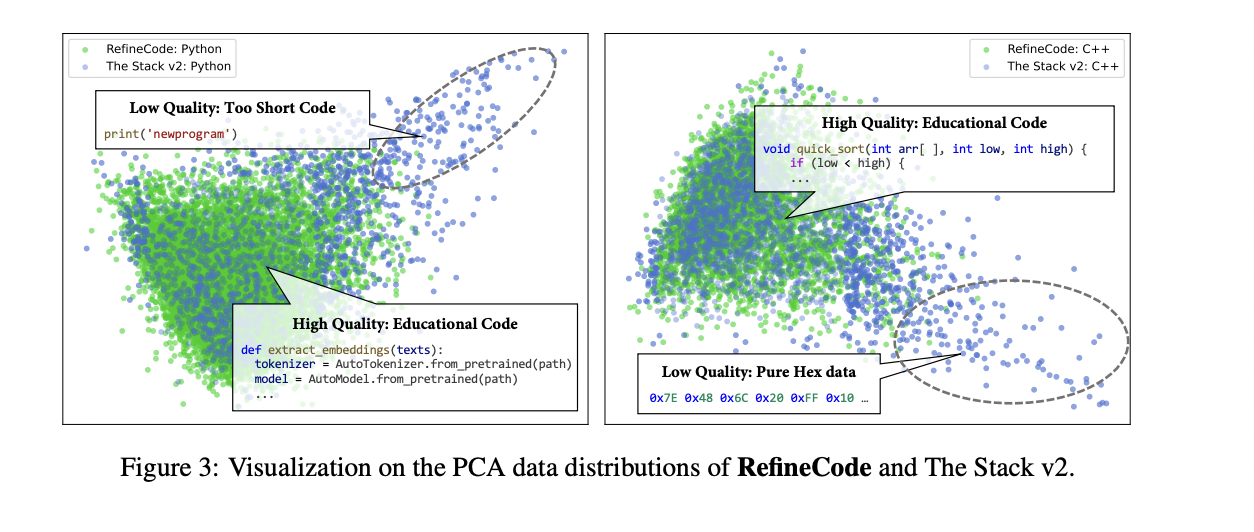
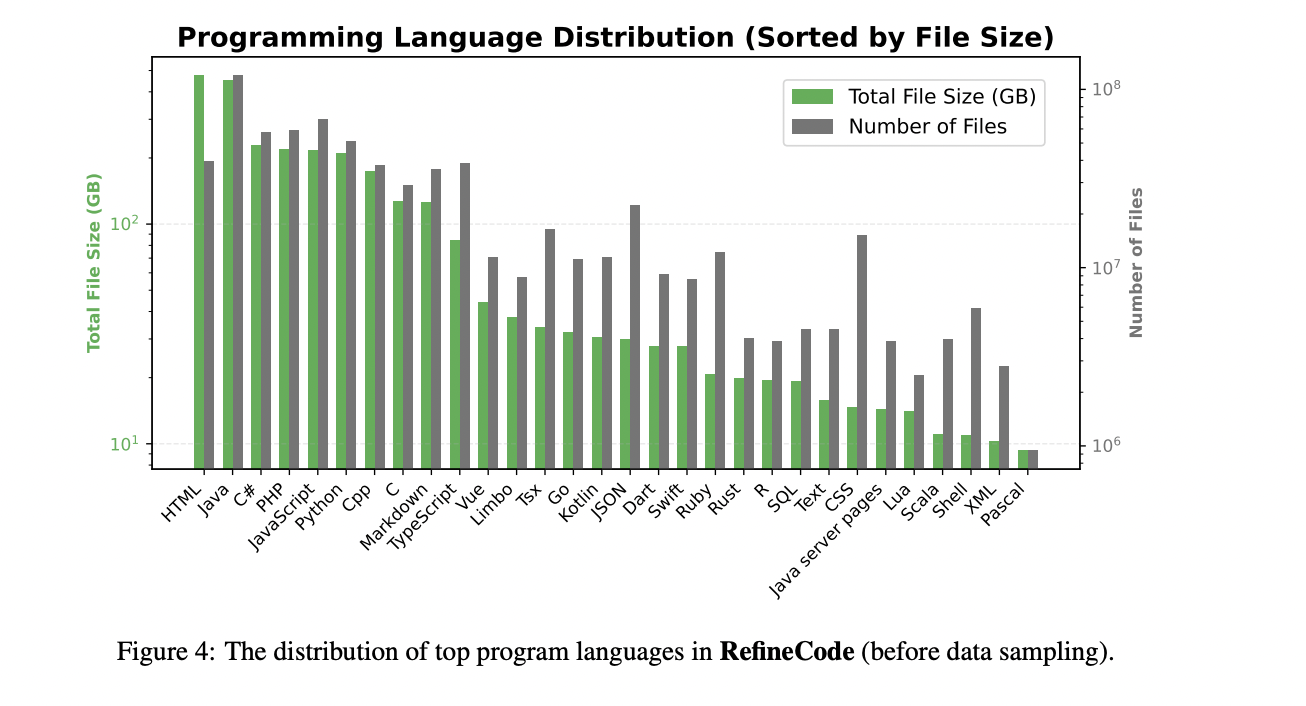
OpenCoder begins with a classy information processing pipeline centered on RefineCode, a high-quality, reproducible dataset comprising 960 billion tokens throughout 607 programming languages. The info preparation course of follows a meticulous five-step strategy to make sure optimum high quality and variety. The preprocessing section initially excludes recordsdata bigger than 8MB and restricts choice to particular programming language file extensions. The deduplication course of employs each actual and fuzzy strategies, using SHA256 hash values and LSH strategies to remove duplicate content material whereas preserving recordsdata with larger star counts and up to date commit instances. The transformation section addresses pervasive points by copyright discover elimination and Personally Identifiable Data (PII) discount. The filtering stage implements three distinct classes of guidelines: pure language filtering, basic code filtering, and language-specific filtering for eight main programming languages. Lastly, the info sampling section maintains distribution steadiness by downsampling over-represented languages like Java and HTML, finally producing roughly 730 billion tokens for pretraining. Comparative evaluation utilizing PCA visualization demonstrates that RefineCode achieves a extra concentrated embedding distribution in comparison with earlier datasets, indicating larger high quality and consistency.


Pre-Coaching
The OpenCoder structure encompasses two mannequin variants: a 1.5 billion parameter mannequin and an 8 billion parameter mannequin. The 1.5B model options 24 layers with 2240 hidden dimensions and 14 consideration heads, whereas the 8B model follows the Llama-3.1-8B structure with 32 layers, 4096 hidden dimensions, and eight consideration heads. Each fashions make the most of the SwiGLU activation perform and make use of a vocabulary measurement of 96,640. The coaching course of follows a classy pipeline throughout a number of phases. Throughout pretraining, each fashions are educated on an enormous multilingual dataset together with Chinese language, English, and 607 programming languages. The 1.5B mannequin processes 2 trillion tokens over 4 epochs, adopted by annealing coaching on 100 billion further tokens. The 8B mannequin undergoes coaching on 2.5 trillion tokens for 3.5 epochs, with a subsequent decay section utilizing 100 billion tokens. Each fashions make use of the WSD studying schedule with rigorously tuned hyperparameters. Coaching is performed on giant GPU clusters, with the 1.5B mannequin requiring 28,034 GPU hours on H800s and the 8B mannequin consuming 96,000 GPU hours on H100s.
Publish Coaching
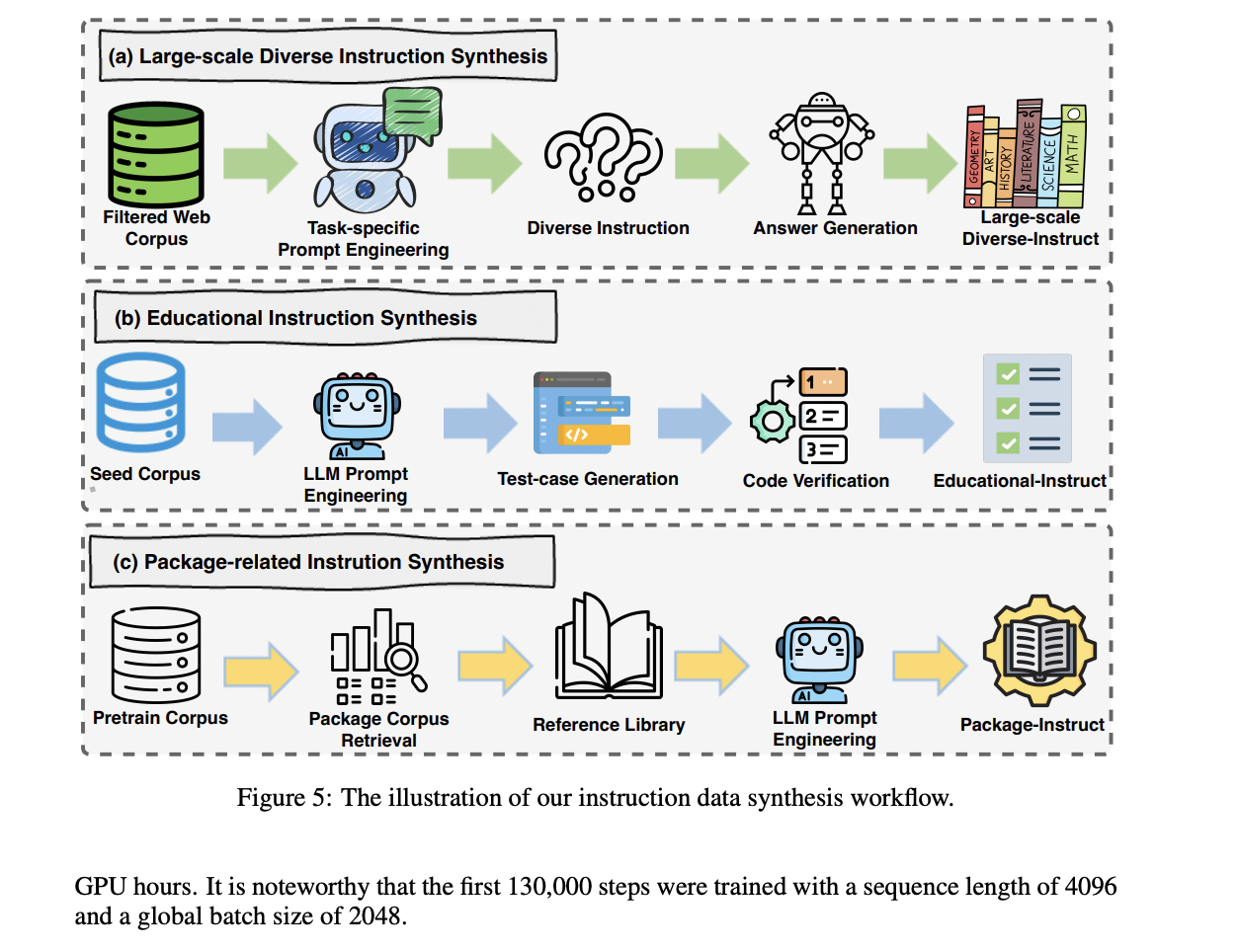
The post-training section of OpenCoder includes an intensive and complex strategy to instruction tuning, through the use of a number of information sources and synthesis strategies. The method begins with accumulating open-source instruction corpora from numerous sources like Evol-Instruct, Infinity-Instruct, and McEval, with cautious language sampling and LLM-based filtering to extract code-relevant content material. Actual consumer queries from WildChat and Code-290k-ShareGpt are included after thorough cleansing and high quality enhancement by LLM regeneration. The structure implements three specialised instruction synthesis approaches: Instructional Instruction Synthesis employs a scorer mannequin to establish high-quality seed information and generates check circumstances for validation; Bundle-related Instruction Synthesis addresses the problem of outdated package deal utilization by incorporating present documentation from fashionable Python libraries; and Massive-scale Various Instruction Synthesis makes use of a complete framework that features context cleansing, job specification, immediate engineering, and response refinement. Every element is designed to make sure the ultimate instruction dataset is numerous, sensible, and aligned with present programming practices.
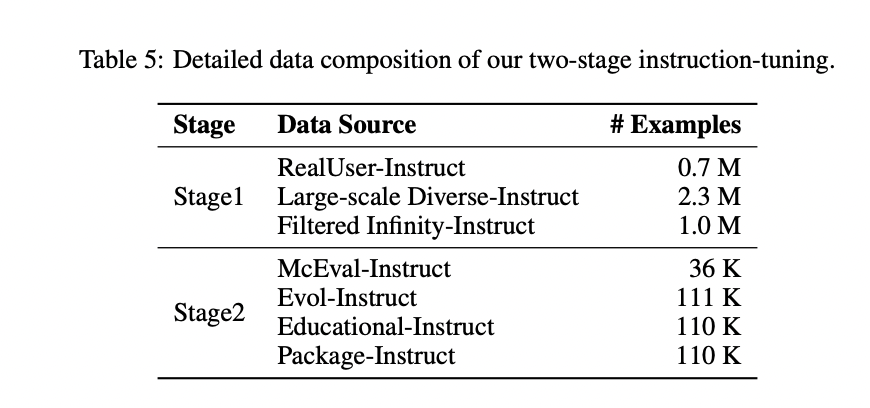
OpenCoder employs a strategic two-stage instruction-tuning course of to develop complete capabilities in each theoretical laptop science and sensible coding duties. The primary stage focuses on theoretical information, using a mixture of RealUser-Instruct (0.7M examples), Massive-scale Various-Instruct (2.3M examples), and Filtered Infinity-Instruct (1.0M examples) to construct a robust basis in laptop science ideas like algorithms, information constructions, and networking ideas. The second stage transitions to sensible coding proficiency, incorporating McEval-Instruct (36K examples), Evol-Instruct (111K examples), Instructional-Instruct (110K examples), and Bundle-Instruct (110K examples). This stage emphasizes publicity to high-quality GitHub code samples, guaranteeing the mannequin can generate syntactically and semantically right code whereas sustaining correct formatting and construction. This dual-phase strategy permits OpenCoder to steadiness theoretical understanding with sensible coding capabilities, making a extra versatile and efficient code technology system.
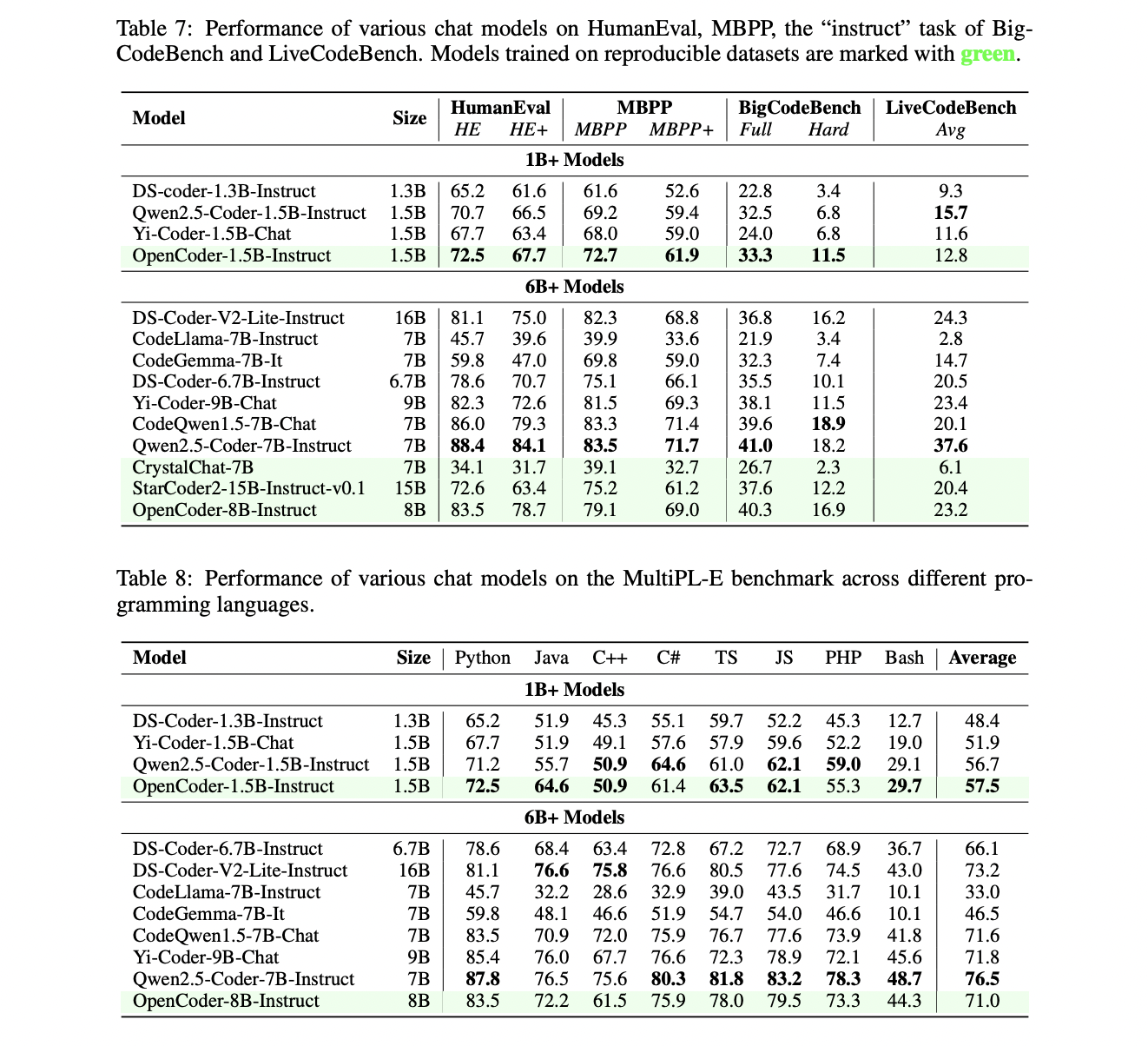
The analysis of OpenCoder demonstrates its distinctive efficiency throughout a number of benchmarks, assessing each base fashions and instruction-tuned variations. The bottom fashions have been primarily evaluated on code completion capabilities by established benchmarks like HumanEval, MBPP (together with their enhanced variations HumanEval+ and MBPP+), and BigCodeBench. These assessments measured the mannequin’s proficiency in understanding and making use of Python information constructions, and algorithms, and dealing with complicated library interactions.
The instruction-tuned fashions underwent extra complete testing throughout 5 main benchmarks. LiveCodeBench evaluated the mannequin’s capability to resolve complicated algorithmic issues from platforms like LeetCode and CodeForces. MultiPL-E assessed code technology capabilities throughout a number of programming languages together with C++, Java, PHP, and TypeScript. McEval completely evaluated 40 programming languages with roughly 2,000 samples, the place OpenCoder-8B-Instruct demonstrated superior multilingual efficiency in comparison with similar-sized open-source fashions. Equally, MdEval examined the mannequin’s debugging capabilities throughout 18 languages with 1.2K samples, showcasing OpenCoder’s efficient bug identification and fixing skills.
The outcomes constantly point out that OpenCoder achieves state-of-the-art efficiency amongst open-source fashions, significantly excelling in multilingual code technology and debugging duties. These complete evaluations validate the effectiveness of OpenCoder’s two-stage instruction-tuning strategy and its refined structure.
OpenCoder represents a big development in open-source code language fashions, attaining efficiency similar to proprietary options whereas sustaining full transparency. Via the discharge of its complete coaching supplies, together with information pipelines, datasets, and detailed protocols, OpenCoder units a brand new commonplace for reproducible analysis in code AI. The intensive ablation research performed throughout numerous coaching phases present invaluable insights for future growth, making OpenCoder not only a highly effective software however a basis for advancing the sector of code intelligence.
Take a look at the Paper, Mission, GitHub Web page, and Fashions on Hugging Face. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Clever Doc Processing with GenAI in Monetary Companies and Actual Property Transactions
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


