


Autoregressive (AR) fashions have modified the sector of picture era, setting new benchmarks in producing high-quality visuals. These fashions break down the picture creation course of into sequential steps, every token generated based mostly on prior tokens, creating outputs with distinctive realism and coherence. Researchers have broadly adopted AR methods for pc imaginative and prescient, gaming, and digital content material creation functions. Nonetheless, the potential of AR fashions is usually constrained by their inherent inefficiencies, notably their sluggish era course of, which stays a major hurdle in real-time functions.
Amongst many considerations, a vital one which AR fashions face is their pace. The token-by-token era course of is inherently sequential, which means every new token should look ahead to its predecessor to finish. This method limits scalability and ends in excessive latency throughout picture era duties. As an example, producing a 256×256 picture utilizing conventional AR fashions like LlamaGen requires 256 steps, translating to roughly 5 seconds on trendy GPUs. Such delays hinder their deployment in functions that demand instantaneous outcomes. Additionally, whereas AR fashions excel in sustaining the constancy of their outputs, they battle to satisfy the rising demand for each pace and high quality in large-scale implementations.
Efforts to speed up AR fashions have yielded varied strategies, similar to predicting a number of tokens concurrently or adopting masking methods throughout era. These approaches goal to cut back the required steps however usually compromise the standard of the generated pictures. For instance, in multi-token era methods, the idea of conditional independence amongst tokens introduces artifacts, undermining the cohesiveness of the output. Equally, masking-based strategies permit for sooner era by coaching fashions to foretell particular tokens based mostly on others, however their effectiveness diminishes when era steps are drastically diminished. These limitations spotlight the necessity for a brand new method to reinforce AR mannequin effectivity.
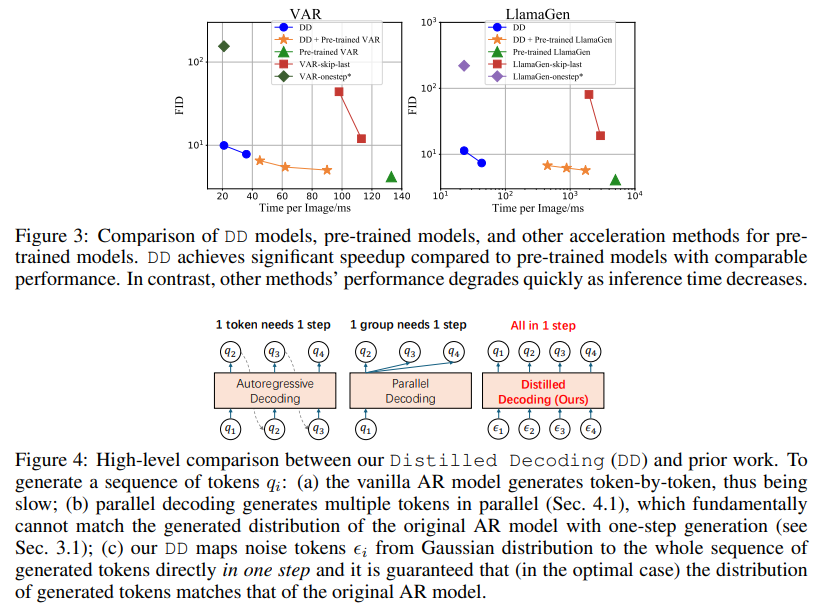
Tsinghua College and Microsoft Analysis researchers have launched an answer to those challenges: Distilled Decoding (DD). This technique builds on circulate matching, a deterministic mapping that connects Gaussian noise to the output distribution of pre-trained AR fashions. Not like typical strategies, DD doesn’t require entry to the unique coaching information of the AR fashions, making it extra sensible for deployment. The analysis demonstrated that DD can remodel the era course of from a whole lot of steps to as few as one or two whereas preserving the standard of the output. For instance, on ImageNet-256, DD achieved a speed-up of 6.3x for VAR fashions and a formidable 217.8x for LlamaGen, decreasing era steps from 256 to only one.
The technical basis of DD is predicated on its skill to create a deterministic trajectory for token era. Utilizing circulate matching, DD maps noisy inputs to tokens to align their distribution with the pre-trained AR mannequin. Throughout coaching, the mapping is distilled into a light-weight community that may immediately predict the ultimate information sequence from a noise enter. This course of ensures sooner era and offers flexibility in balancing pace and high quality by permitting intermediate steps when wanted. Not like current strategies, DD eliminates the trade-off between pace and constancy, enabling scalable implementations throughout numerous duties.
In experiments, DD highlights its superiority over conventional strategies. As an example, utilizing VAR-d16 fashions, DD achieved one-step era with an FID rating improve from 4.19 to 9.96, showcasing minimal high quality degradation regardless of a 6.3x speed-up. For LlamaGen fashions, the discount in steps from 256 to 1 resulted in an FID rating of 11.35, in comparison with 4.11 within the authentic mannequin, with a outstanding 217.8x pace enchancment. DD demonstrated related effectivity in text-to-image duties, decreasing era steps from 256 to 2 whereas sustaining a comparable FID rating of 28.95 in opposition to 25.70. The outcomes underline DD’s skill to drastically improve pace with out vital loss in picture high quality, a feat unmatched by baseline strategies.
A number of key takeaways from the analysis on DD embrace:
- DD reduces era steps by orders of magnitude, attaining as much as 217.8x sooner era than conventional AR fashions.
- Regardless of the accelerated course of, DD maintains acceptable high quality ranges, with FID rating will increase remaining inside manageable ranges.
- DD demonstrated constant efficiency throughout completely different AR fashions, together with VAR and LlamaGen, no matter their token sequence definitions or mannequin sizes.
- The method permits customers to steadiness high quality and pace by selecting one-step, two-step, or multi-step era paths based mostly on their necessities.
- The strategy eliminates the necessity for the unique AR mannequin coaching information, making it possible for sensible functions in eventualities the place such information is unavailable.
- As a result of its environment friendly distillation method, DD can doubtlessly influence different domains, similar to text-to-image synthesis, language modeling, and picture era.
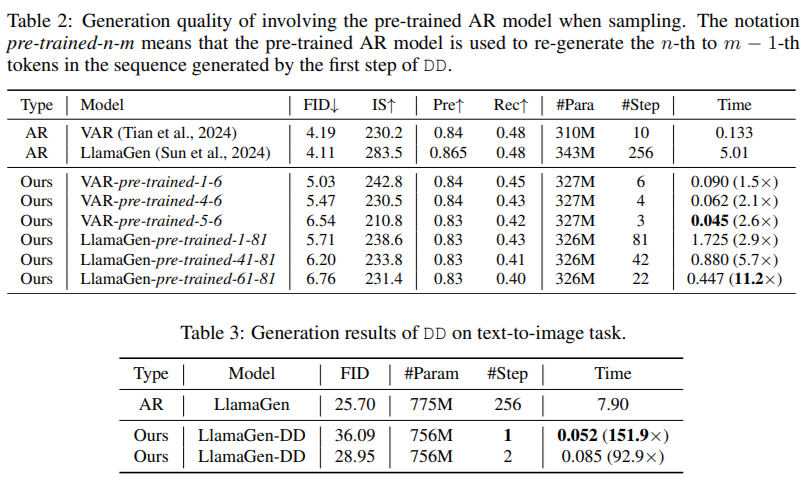
In conclusion, with the introduction of Distilled Decoding, researchers have efficiently addressed the longstanding speed-quality trade-off that has plagued AR era processes by leveraging circulate matching and deterministic mappings. The strategy accelerates picture synthesis by decreasing steps drastically and preserves the outputs’ constancy and scalability. With its sturdy efficiency, adaptability, and sensible deployment benefits, Distilled Decoding opens new frontiers in real-time functions of AR fashions. It units the stage for additional innovation in generative modeling.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for International Management in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


