


Integrating imaginative and prescient and language processing in AI has develop into a cornerstone for growing programs able to concurrently understanding visible and textual knowledge, i.e., multimodal knowledge. This interdisciplinary discipline focuses on enabling machines to interpret photographs, extract related textual data, and discern spatial and contextual relationships. These capabilities promise to reshape real-world purposes by bridging the visible and linguistic understanding hole from autonomous autos to superior human-computer interplay programs.
Regardless of many accomplishments within the discipline, it has notable challenges. Many fashions prioritize high-level semantic understanding of photographs, capturing general scene descriptions however typically overlooking detailed pixel or region-level data. This omission undermines their efficiency in specialised duties requiring intricate comprehension, similar to textual extraction from photographs or understanding spatial object relationships. Additionally, integrating a number of imaginative and prescient encoders to handle these points typically leads to computational inefficiency, rising coaching and deployment complexity.
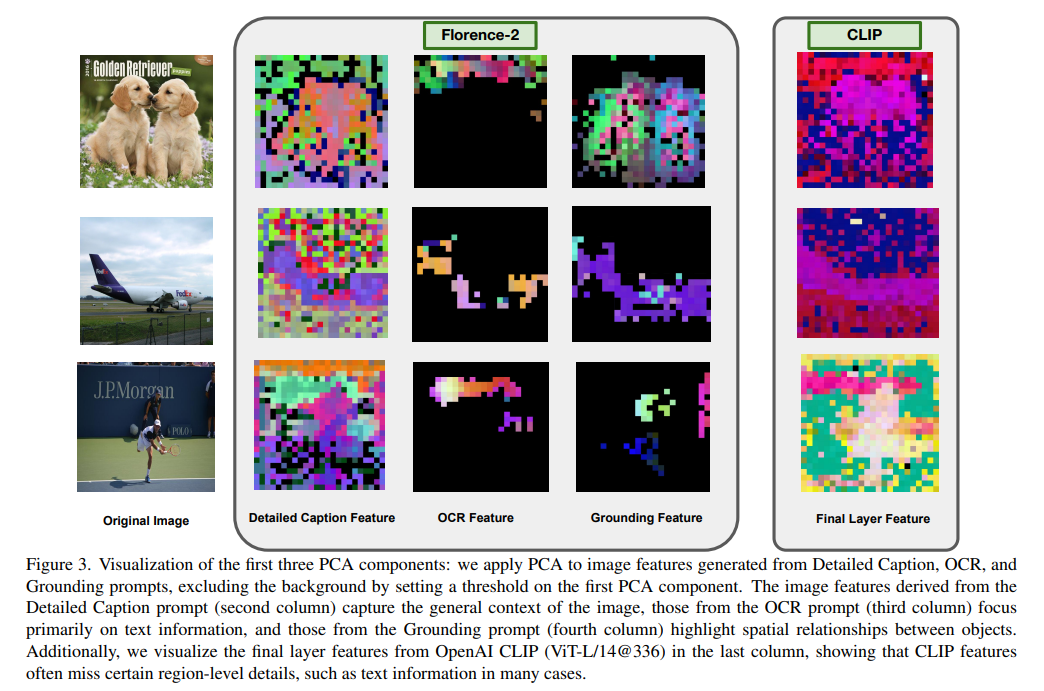
Instruments like CLIP have traditionally set a benchmark for aligning visible and textual representations utilizing contrastive pretraining. Whereas efficient for basic duties, CLIP’s reliance on single-layer semantic options limits its adaptability to various challenges. Superior approaches have launched self-supervised and segmentation fashions that tackle particular duties, but they incessantly depend on a number of encoders, which may enhance the computational calls for. These limitations spotlight the necessity for a flexible and environment friendly strategy that balances generalization and task-specific precision.
Researchers from the College of Maryland and Microsoft launched Florence-VL, a singular structure to handle these challenges and improve vision-language integration. This mannequin employs a generative imaginative and prescient basis encoder, Florence-2, to supply task-specific visible representations. This encoder departs from conventional strategies by using a prompt-based strategy, enabling it to tailor its options to numerous duties similar to picture captioning, object detection, and optical character recognition (OCR).
Central to Florence-VL’s effectiveness is its Depth-Breadth Fusion (DBFusion) mechanism, which integrates visible options throughout a number of layers and prompts. This twin strategy ensures the mannequin captures granular and high-level particulars, catering to various vision-language duties. Depth options are derived from hierarchical layers, providing detailed visible insights, whereas breadth options are extracted utilizing task-specific prompts, making certain adaptability to numerous challenges. Florence-VL combines these options effectively by using a channel-based fusion technique, sustaining computational simplicity with out sacrificing efficiency. Intensive coaching on 16.9 million picture captions and 10 million instruction datasets additional optimizes the mannequin’s capabilities. Not like conventional fashions that freeze sure parts throughout coaching, Florence-VL fine-tunes its complete structure throughout pretraining, reaching enhanced alignment between visible and textual modalities. Its instruction-tuning part refines its capability to adapt to downstream duties, supported by high-quality datasets curated for particular purposes.
Florence-VL has been examined throughout 25 benchmarks, together with visible query answering, OCR, and chart comprehension duties. It achieved an alignment lack of 2.98, considerably surpassing fashions similar to LLaVA-1.5 and Cambrain-8B. The Florence-VL 3B variant excelled in 12 out of 24 evaluated duties, whereas the bigger 8B model persistently outperformed rivals. Its outcomes on OCRBench and InfoVQA benchmarks underline its capability to extract and interpret textual data from photographs with unparalleled precision.
Key takeaways from the analysis on Florence-VL are as follows:
- Unified Imaginative and prescient Encoding: A single imaginative and prescient encoder reduces complexity whereas sustaining task-specific adaptability.
- Process-Particular Flexibility: The prompt-based mechanism helps various purposes, together with OCR and grounding.
- Enhanced Fusion Technique: DBFusion ensures a wealthy mixture of depth and breadth options, capturing granular and contextual particulars.
- Superior Benchmark Outcomes: Florence-VL leads efficiency in 25 benchmarks, reaching an alignment lack of 2.98.
- Coaching Effectivity: Nice-tuning your entire structure throughout pretraining enhances multimodal alignment, yielding higher process outcomes.

In conclusion, Florence-VL addresses the crucial limitations of current vision-language fashions by introducing an progressive strategy that successfully combines granular and high-level visible options. The multimodal mannequin ensures task-specific adaptability by leveraging Florence-2 as its generative imaginative and prescient encoder and using the Depth-Breadth Fusion (DBFusion) mechanism whereas sustaining computational effectivity. Florence-VL excels throughout various purposes, similar to OCR and visible query answering, reaching superior efficiency throughout 25 benchmarks.
Try the Paper, Demo, and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Rework proofs-of-concept into production-ready AI purposes and brokers’ (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


