


In deep studying, neural community optimization has lengthy been an important space of focus. Coaching massive fashions like transformers and convolutional networks requires important computational sources and time. Researchers have been exploring superior optimization strategies to make this course of extra environment friendly. Historically, adaptive optimizers equivalent to Adam have been used to hurry coaching by adjusting community parameters by way of gradient descent. Nevertheless, these strategies nonetheless require many iterations, and whereas they’re extremely efficient in fine-tuning parameters, the general course of stays time-consuming for large-scale fashions. Optimizing the coaching course of is crucial for deploying AI purposes extra rapidly and effectively.
One of many central challenges on this subject is the prolonged time wanted to coach advanced neural networks. Though optimizers like Adam carry out parameter updates iteratively to attenuate errors regularly, the sheer dimension of fashions, particularly in duties like pure language processing (NLP) and pc imaginative and prescient, results in lengthy coaching cycles. This delay slows down the event and deployment of AI applied sciences in real-world settings the place fast turnaround is crucial. The computational calls for enhance considerably as fashions develop, necessitating options that optimize efficiency and cut back coaching time with out sacrificing accuracy or stability.
The present strategies to deal with these challenges embody the extensively used Adam Optimizer and Studying to Optimize (L2O). Adam, an adaptive technique, adjusts parameters primarily based on their previous gradients, lowering oscillations and bettering convergence. L2O, however, trains a neural community to optimize different networks, which accelerates coaching. Whereas each strategies have been revolutionary, they arrive with their limitations. Whereas efficient, Adam’s step-by-step nature nonetheless leaves room for enchancment in pace. L2O, regardless of providing quicker optimization cycles, could be computationally costly and unstable, requiring frequent updates and cautious tuning to keep away from destabilizing the coaching course of.
Researchers from Samsung’s SAIT AI Lab, Concordia College, Université de Montréal, and Mila have launched a novel method often known as Neuron Interplay and Nowcasting (NINO) networks. This technique goals to considerably cut back coaching time by predicting the long run state of community parameters. Fairly than making use of an optimization step at each iteration, as with conventional strategies, NINO employs a learnable operate to foretell future parameter updates periodically. By integrating neural graphs—which seize the relationships and interactions between neurons inside layers—NINO could make uncommon but extremely correct predictions. This periodic method reduces the computational load whereas sustaining accuracy, significantly in advanced architectures like transformers.
On the core of the NINO methodology lies its capability to leverage neuron connectivity by way of graph neural networks (GNNs). Conventional optimizers like Adam deal with parameter updates independently with out contemplating the interactions between neurons. NINO, nevertheless, makes use of neural graphs to mannequin these interactions, making predictions about future community parameters in a method that displays the community’s inherent construction. The researchers constructed on the Weight Nowcaster Networks (WNN) technique however improved it by incorporating neuron interplay modeling. They conditioned NINO to foretell parameter modifications for the close to and distant future. This adaptability permits NINO to be utilized at completely different levels of coaching with out requiring fixed retraining, making it appropriate for varied neural architectures, together with imaginative and prescient and language duties. The mannequin can effectively learn the way community parameters evolve through the use of supervised studying from coaching trajectories throughout a number of duties, enabling quicker convergence.
The NINO community considerably outperformed current strategies in varied experiments, significantly in imaginative and prescient and language duties. As an illustration, when examined on a number of datasets, together with CIFAR-10, FashionMNIST, and language modeling duties, NINO lowered the variety of optimization steps by as a lot as 50%. In a single experiment on a language job, the baseline Adam optimizer required 23,500 steps to achieve the goal perplexity, whereas NINO achieved the identical efficiency in simply 11,500 steps. Equally, in a imaginative and prescient job with convolutional neural networks, NINO lowered the steps from 8,606 to 4,582, representing a 46.8% discount in coaching time. This discount interprets into quicker coaching and important financial savings in computational sources. The researchers demonstrated that NINO performs effectively not solely on in-distribution duties, the place the mannequin has been educated but additionally on out-of-distribution duties, the place it generalizes higher than current strategies like WNN and L2O.
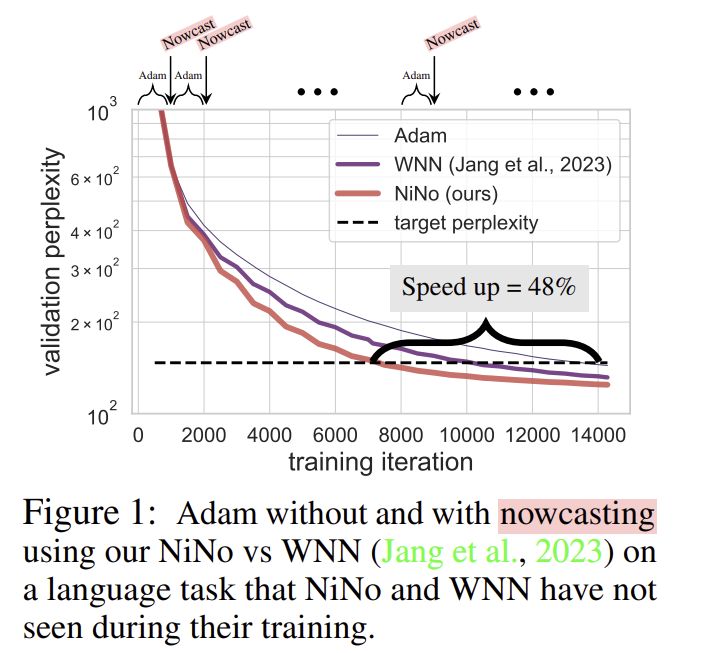
NINO’s efficiency enhancements are significantly noteworthy in duties involving massive neural networks. The researchers examined the mannequin on transformers with 6 layers and 384 hidden models, considerably bigger than these seen throughout coaching. Regardless of these challenges, NINO achieved a 40% discount in coaching time, demonstrating its scalability. The strategy’s capability to generalize throughout completely different architectures and datasets with out retraining makes it an interesting answer for dashing up coaching in various AI purposes.
In conclusion, the analysis staff’s introduction of NINO represents a big development in neural community optimization. By leveraging neural graphs and GNNs to mannequin neuron interactions, NINO gives a sturdy and scalable answer that addresses the crucial challenge of lengthy coaching instances. The outcomes spotlight that this technique can considerably cut back the variety of optimization steps whereas sustaining or bettering efficiency. This development accelerates the coaching course of and opens the door for quicker AI mannequin deployment throughout varied domains.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


