

: Advancing Actual-Time Audio Technology")
Autoregressive fashions are used to generate sequences of discrete tokens. The following token is conditioned by the previous tokens in a given sequence within the method. Latest analysis confirmed that producing sequences of steady embeddings autoregressively can also be possible. Nonetheless, such Steady Autoregressive Fashions (CAMs) generate these embeddings equally sequentially, however they face challenges comparable to a decline in era high quality over prolonged sequences. This decline happens due to error accumulation throughout the inference course of, the place small prediction errors compound because the sequence size will increase, leading to degraded output.
Conventional fashions for autoregressive picture and audio era relied on discretizing information into tokens utilizing VQ-VAEs to allow fashions to work inside a discrete likelihood area. Such an method introduces important drawbacks, together with further losses when coaching VAEs and added complexity. Though steady embeddings are extra environment friendly, they have a tendency to build up errors throughout inference, inflicting distribution shifts and decreasing the generated output’s high quality. Latest makes an attempt to bypass quantization by coaching on steady embeddings have failed to provide convincing outcomes resulting from cumbersome non-sequential masking and fine-tuning strategies impair effectivity and limit additional utilization throughout the analysis group.
To resolve this, a bunch of researchers from Queen Mary College and Sony Laptop Science Laboratories performed detailed analysis and proposed a technique to counteract error accumulation and prepare purely autoregressive fashions on ordered sequences of steady embeddings with out including complexity. To beat the drawbacks of normal AMs, CAM launched a noise augmentation technique throughout coaching to simulate the errors that happen throughout inference. This technique mixed the strengths of Rectified Move (RF) and AMs for steady embeddings.
The primary idea behind the CAM proposed was injecting noise within the sequence throughout coaching to simulate error-prone inference situations. It then utilized iterative reverse diffusion to generate sequences autoregressively, progressively bettering predictions whereas correcting errors. CAM was pre-trained to be sturdy for error accumulation throughout the era of longer sequences by means of coaching with noisy sequences. This course of improved the final high quality of the generated sequences, particularly for duties comparable to music era, for which the standard of every predicted factor proved essential to the general output.
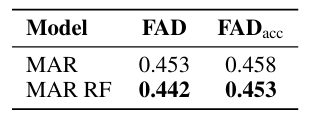
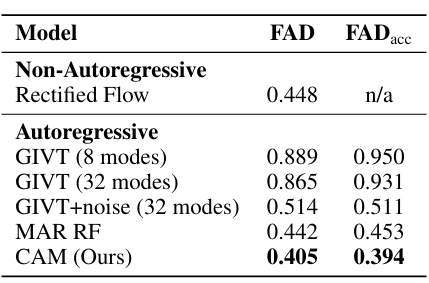
The strategy was examined on a music dataset and in contrast with the experiment’s autoregressive and non-autoregressive baselines. The researchers used a dataset of about 20,000 single-instrument recordings with 48 kHz stereo audio for coaching and analysis. They processed the info with Music2Latent to create steady latent embeddings with a 12 Hz sampling price. Based mostly on a transformer with 16 layers and 150 million parameters, CAM was skilled utilizing AdamW for 400k iterations. CAM carried out higher than the opposite fashions, with FAD of 0.405 and FADacc of 0.394, in comparison with baselines like GIVT or MAR. CAM supplied higher high quality fundamentals for reconstructing the sound spectrum and avoiding the error buildup in lengthy sequences; the noise augmentation method additionally helped to reinforce the GIVT scores.
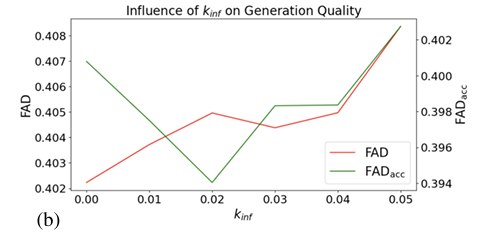
In abstract, the proposed technique trains purely autoregressive fashions on steady embeddings that immediately tackle the error accumulation drawback. A noise injection approach calibrated rigorously at inference time additional reduces error accumulation. This technique opens the trail for real-time and interactive audio functions that profit from the effectivity and sequential nature of autoregressive fashions and can be utilized as a baseline for additional analysis within the area!
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Remodel proofs-of-concept into production-ready AI functions and brokers’ (Promoted)
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and remedy challenges.


