


Nvidia unveiled its newest giant language mannequin (LLM) providing, the Llama-3.1-Nemotron-51B. Primarily based on Meta’s Llama-3.1-70B, this mannequin has been fine-tuned utilizing superior Neural Structure Search (NAS) methods, leading to a breakthrough in each efficiency and effectivity. Designed to suit on a single Nvidia H100 GPU, the mannequin considerably reduces reminiscence consumption, computational complexity, and prices related to working such giant fashions. It marks an vital milestone in Nvidia’s ongoing efforts to optimize large-scale AI fashions for real-world purposes.
The Origins of Llama-3.1-Nemotron-51B
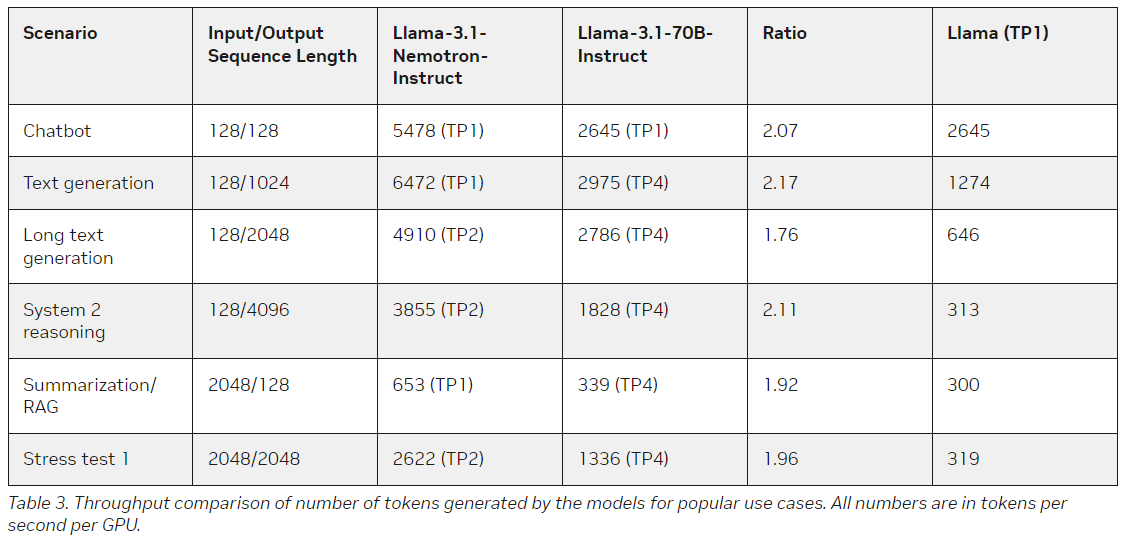
The Llama-3.1-Nemotron-51B is a spinoff of Meta’s Llama-3.1-70B, launched in July 2024. Whereas Meta’s mannequin had already set the bar excessive in efficiency, Nvidia sought to push the envelope additional by specializing in effectivity. By using NAS, Nvidia’s researchers have created a mannequin that provides comparable, if not higher, efficiency and considerably reduces useful resource calls for. Concerning uncooked computational energy, the Llama-3.1-Nemotron-51B provides 2.2x quicker inference than its predecessor whereas sustaining a comparable stage of accuracy.
Breakthroughs in Effectivity and Efficiency
One of many key challenges in LLM growth is balancing accuracy with computational effectivity. Many large-scale fashions ship state-of-the-art outcomes however at the price of large {hardware} and vitality assets, which limits their applicability. Nvidia’s new mannequin strikes a fragile steadiness between these two competing components.
The Llama-3.1-Nemotron-51B achieves a powerful accuracy-efficiency tradeoff, lowering the reminiscence bandwidth, reducing the variety of floating-point operations per second (FLOPs), and reducing the general reminiscence footprint with out compromising the mannequin’s potential to carry out advanced duties like reasoning, summarization, and language era. Nvidia has compressed the mannequin to the purpose the place it might probably run bigger workloads on a single H100 GPU than ever earlier than, opening up many new potentialities for builders and companies alike.
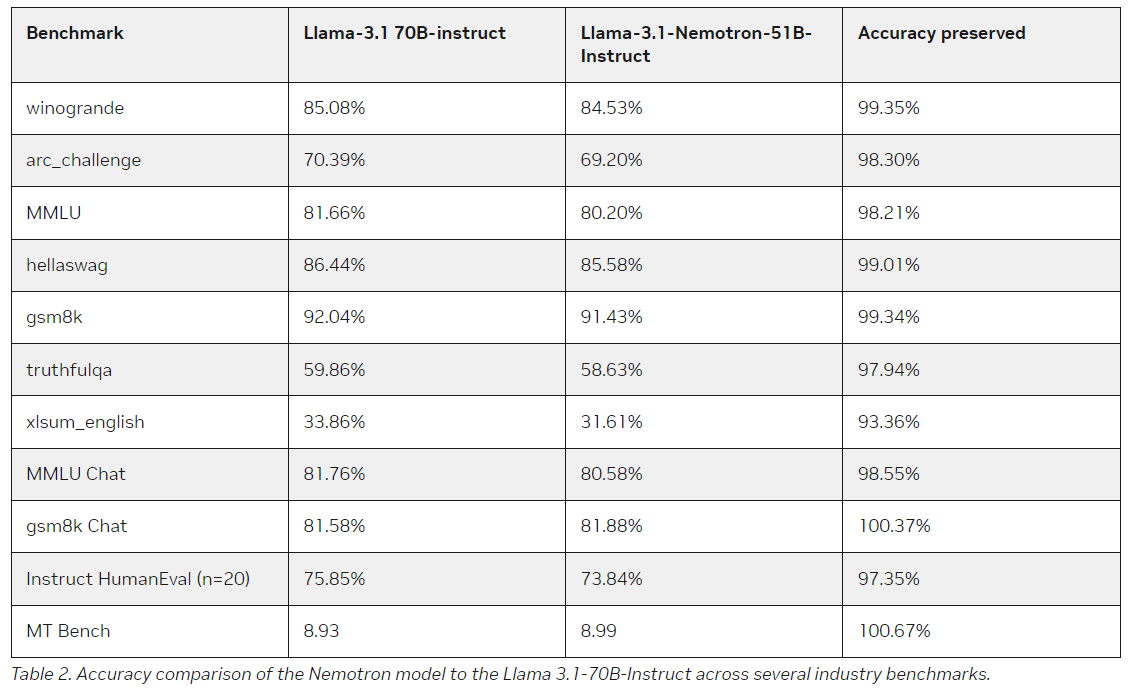
Improved Workload Administration and Price Effectivity
A standout characteristic of the Llama-3.1-Nemotron-51B is its potential to handle bigger workloads on a single GPU. This mannequin permits builders to deploy high-performance LLMs in more cost effective environments, working duties that will have beforehand required a number of GPUs on only one H100 unit.
For instance, the mannequin can deal with 4x bigger workloads throughout inference than the reference Llama-3.1-70B. It additionally permits for quicker throughput, with Nvidia reporting 1.44x higher efficiency in key areas than different fashions. The effectivity of Llama-3.1-Nemotron-51B stems from an progressive strategy to structure, which focuses on lowering redundancy in computational processes whereas nonetheless preserving the mannequin’s potential to execute advanced linguistic duties with excessive accuracy.
Structure Optimization: The Key to Success
The Llama-3.1-Nemotron-51B owes a lot of its success to a novel strategy to structure optimization. Historically, LLMs are constructed utilizing equivalent blocks, that are repeated all through the mannequin. Whereas this simplifies the development course of, it introduces inefficiencies, notably relating to reminiscence and computational prices.
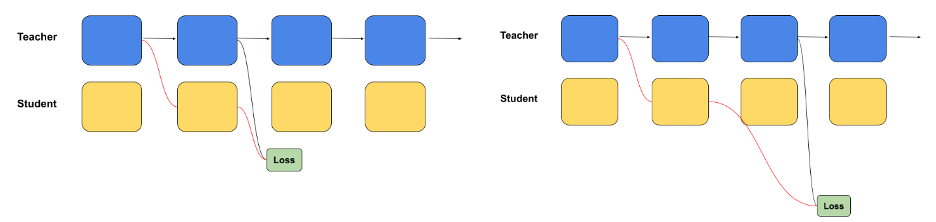
Nvidia addressed these points by using NAS methods that optimize the mannequin for inference. The group has used a block-distillation course of, the place smaller, extra environment friendly scholar fashions are skilled to imitate the performance of the bigger instructor mannequin. By refining these scholar fashions and evaluating their efficiency, Nvidia has produced a model of Llama-3.1 that delivers comparable ranges of accuracy whereas drastically lowering useful resource necessities.
The block-distillation course of permits Nvidia to discover completely different mixtures of consideration and feed-forward networks (FFNs) inside the mannequin, creating various configurations that prioritize both pace or accuracy, relying on the duty’s particular necessities. This flexibility makes Llama-3.1-Nemotron-51B a strong device for varied industries that have to deploy AI at scale, whether or not in cloud environments, information facilities, and even edge computing setups.
The Puzzle Algorithm and Information Distillation
The Puzzle algorithm is one other vital element that units Llama-3.1-Nemotron-51B aside from different fashions. This algorithm scores every potential block inside the mannequin and determines which configurations will yield the very best tradeoff between pace and accuracy. Through the use of data distillation methods, Nvidia has narrowed the accuracy hole between the reference mannequin (Llama-3.1-70B) and the Nemotron-51B, all whereas considerably lowering coaching prices.
By means of this course of, Nvidia has created a mannequin that operates on the environment friendly frontier of AI mannequin growth, pushing the boundaries of what will be achieved with a single GPU. By guaranteeing that every block inside the mannequin is as environment friendly as doable, Nvidia has created a mannequin that outperforms a lot of its friends in accuracy and throughput.
Nvidia’s Dedication to Price-Efficient AI Options
Price has at all times been a big barrier to the large adoption of enormous language fashions. Whereas these fashions’ efficiency is plain, their inference prices have restricted their use to solely essentially the most resource-rich organizations. Nvidia’s Llama-3.1-Nemotron-51B addresses this problem head-on, providing a mannequin that performs at a excessive stage whereas aiming for price effectivity.
The mannequin’s lowered reminiscence and computational necessities make it much more accessible to smaller organizations and builders who may not have the assets to run bigger fashions. Nvidia has additionally streamlined the deployment course of, packaging the mannequin as a part of its Nvidia Inference Microservice (NIM), which makes use of TensorRT-LLM engines for high-throughput inference. This method is designed to be simply deployable in varied settings, from cloud environments to edge gadgets, and may scale with demand.
Future Purposes and Implications
The discharge of Llama-3.1-Nemotron-51B has far-reaching implications for the way forward for generative AI and LLMs. By making high-performance fashions extra accessible and cost-effective, Nvidia has opened the door for a broader vary of industries to reap the benefits of these applied sciences. The lowered price of inference additionally signifies that LLMs can now be deployed in areas beforehand too costly to justify, akin to real-time purposes, customer support chatbots, and extra.
The flexibleness of the NAS strategy used within the mannequin’s growth signifies that Nvidia can proceed to refine and optimize the structure for various {hardware} setups and use instances. Whether or not a developer wants a mannequin optimized for pace or accuracy, Nvidia’s Llama-3.1-Nemotron-51B offers a basis that may be tailored to fulfill varied necessities.
Conclusion
Nvidia’s Llama-3.1-Nemotron-51B is a game-changing launch on this planet of AI. By specializing in efficiency and effectivity, Nvidia has created a mannequin that not solely rivals the very best within the business but in addition units a brand new normal for cost-effectiveness and accessibility. Utilizing NAS and block-distillation methods has allowed Nvidia to interrupt by the standard limitations of LLMs, making it doable to deploy these fashions on a single GPU whereas sustaining excessive accuracy. As generative AI continues to evolve, fashions like Llama-3.1-Nemotron-51B will play an important function in shaping the business’s future, enabling extra organizations to leverage the ability of AI of their on a regular basis operations. Whether or not for large-scale information processing, real-time language era, or superior reasoning duties, Nvidia’s newest providing guarantees to be a useful device for builders and companies.
Try the Mannequin and Weblog. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.
")

