


Combination of Specialists (MoE) fashions have gotten important in advancing AI, significantly in pure language processing. MoE architectures differ from conventional dense fashions by selectively activating subsets of specialised knowledgeable networks for every enter. This mechanism permits fashions to extend their capability with out proportionally rising the computational sources required for coaching and inference. Researchers are more and more adopting MoE architectures to enhance the effectivity and accuracy of LLMs with out incurring the excessive price of coaching new fashions from scratch. The idea is designed to optimize the usage of current dense fashions by incorporating extra parameters to spice up efficiency with out extreme computational overhead.
A typical drawback confronted by dense fashions is that they will attain a efficiency plateau, significantly when working with fashions which have already been extensively educated. As soon as a dense mannequin has reached its peak, additional enhancements are sometimes solely achieved by rising its dimension, which requires retraining and consumes vital computational sources. That is the place upcycling pre-trained dense fashions into MoE fashions turns into significantly related. Upcycling goals to develop a mannequin’s capability by incorporating extra specialists who can deal with particular duties, permitting the mannequin to be taught extra with out being solely retrained.
Present strategies for increasing dense fashions into MoE fashions both contain continued coaching of the dense mannequin or ranging from scratch. These approaches are computationally costly and time-consuming. Additionally, earlier makes an attempt to upcycle dense fashions into MoE buildings typically wanted extra readability on the best way to scale the method for billion-parameter fashions. The sparse combination of knowledgeable strategies affords an answer, however its implementation and scaling particulars nonetheless have to be explored.
Researchers from NVIDIA launched an progressive method to upcycling pre-trained dense fashions into sparse MoE fashions, presenting a “digital group” initialization scheme and a weight scaling technique to facilitate this transformation. The examine primarily targeted on the Nemotron-4 mannequin, a 15-billion-parameter massive multilingual language mannequin, and in contrast its efficiency earlier than and after the upcycling course of. Researchers demonstrated that their technique improved mannequin efficiency by using current pre-trained dense checkpoints and changing them into extra environment friendly sparse MoE buildings. Their experiments confirmed that fashions upcycled into MoE architectures outperformed those who continued dense coaching.
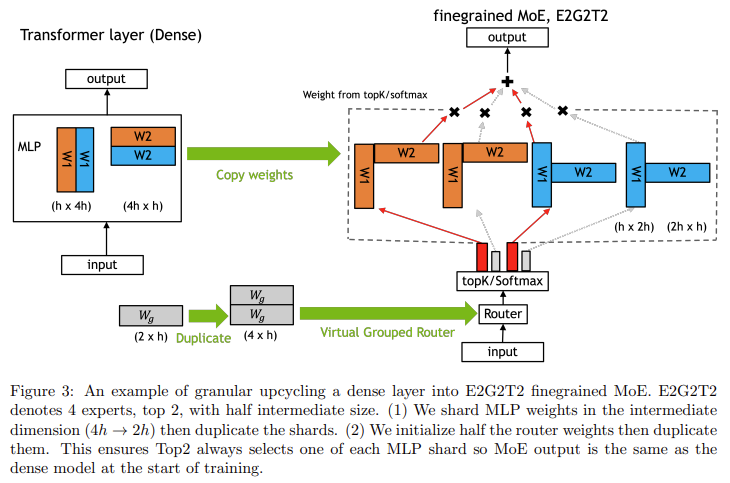
The core of the upcycling course of concerned copying the dense mannequin’s Multi-Layer Perceptron (MLP) weights and utilizing a brand new routing technique often known as softmax-then-topK. This system permits tokens to be routed by a subset of specialists, enhancing the mannequin’s capability by including extra parameters with no corresponding enhance in computational price. Researchers additionally launched weight scaling methods important to sustaining or bettering the mannequin’s accuracy after the conversion. As an illustration, the upcycled Nemotron-4 mannequin processed 1 trillion tokens and achieved a considerably higher rating on the MMLU benchmark (67.6%) in comparison with the 65.3% achieved by the repeatedly educated dense model of the mannequin. The introduction of fine-grained granularity additional helped enhance the accuracy of the upcycled mannequin.
The upcycled Nemotron-4 mannequin achieved a 1.5% higher validation loss and better accuracy than its dense counterpart, demonstrating the effectivity of this new method. Furthermore, the upcycling technique proved computationally environment friendly, permitting fashions to proceed bettering past the plateau sometimes confronted by dense fashions. One of many key findings was that the softmax-then-topK routing persistently outperformed different approaches, reminiscent of topK-then-softmax, which is commonly utilized in dense fashions. This new method allowed the upcycled MoE fashions to raised make the most of the data contained within the knowledgeable layers, resulting in improved efficiency.
The primary takeaway from the analysis is that upcycling dense language fashions into MoE fashions is possible and extremely environment friendly, providing vital enhancements in mannequin efficiency and computational useful resource utilization. Using weight scaling, digital group initialization, and fine-grained MoE architectures presents a transparent path for scaling current dense fashions into extra highly effective techniques. The researchers supplied an in depth recipe for upcycling fashions with billions of parameters, showcasing that their technique might be scaled and utilized successfully throughout completely different architectures.
Key Takeaways and Findings from the analysis:
- The upcycled Nemotron-4 mannequin, which had 15 billion parameters, achieved a 67.6% MMLU rating after processing 1 trillion tokens.
- The strategy launched softmax-then-topK routing, which improved validation loss by 1.5% over continued dense coaching.
- Upcycled fashions confirmed superior efficiency with out extra computational sources in comparison with dense fashions.
- Digital group initialization and weight scaling have been important in making certain the MoE fashions retained or surpassed the accuracy of the unique dense fashions.
- The examine additionally discovered that increased granularity MoEs, mixed with cautious weight scaling, can considerably enhance mannequin accuracy.

In conclusion, this analysis supplies a sensible and environment friendly answer to increasing the capability of pre-trained dense fashions by upcycling into MoE architectures. By leveraging methods like digital group initialization and softmax-then-topK routing, the analysis workforce demonstrated how fashions can proceed to enhance in accuracy with out the price of full retraining.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Knowledge Retrieval Convention (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


