

 for Enhanced Lengthy-Context Query Answering with Massive Language Fashions (LLMs)")
Retrieval-augmented era (RAG), a method that enhances the effectivity of huge language fashions (LLMs) in dealing with intensive quantities of textual content, is crucial in pure language processing, significantly in functions akin to question-answering, the place sustaining the context of knowledge is essential for producing correct responses. As language fashions evolve, researchers attempt to push the boundaries by bettering how these fashions course of and retrieve related info from large-scale textual information.
One fundamental downside with current LLMs is their issue in managing lengthy contexts. Because the context size will increase, the fashions need assistance to keep up a transparent give attention to related info, which might result in a major drop within the high quality of their solutions. This difficulty is especially pronounced in question-answering duties, the place precision is paramount. The fashions are inclined to get overwhelmed by the sheer quantity of knowledge, which might trigger them to retrieve irrelevant information, diluting the solutions’ accuracy.
In current developments, LLMs like GPT-4 and Gemini have been designed to deal with for much longer textual content sequences, with some fashions supporting as much as 1 million tokens in context. Nonetheless, these developments include their very own set of challenges. Whereas long-context LLMs can theoretically deal with bigger inputs, they usually introduce pointless or irrelevant chunks of knowledge into the method, leading to a decrease precision charge. Thus, researchers are nonetheless looking for higher options to successfully handle lengthy contexts whereas sustaining reply high quality and effectively utilizing computational assets.
Researchers from NVIDIA, primarily based in Santa Clara, California, proposed an order-preserve retrieval-augmented era (OP-RAG) strategy to deal with these challenges. OP-RAG provides a considerable enchancment over the normal RAG strategies by preserving the order of the textual content chunks retrieved for processing. In contrast to current RAG programs, which prioritize chunks primarily based on relevance scores, the OP-RAG mechanism retains the unique sequence of the textual content, making certain that context and coherence are maintained all through the retrieval course of. This development permits for a extra structured retrieval of related info, avoiding the pitfalls of conventional RAG programs that may retrieve extremely related however out-of-context information.
The OP-RAG technique introduces an progressive mechanism that restructures how info is processed. First, the large-scale textual content is cut up into smaller, sequential chunks. These chunks are then evaluated primarily based on their relevance to the question. As an alternative of rating them solely by relevance, OP-RAG ensures that the chunks are stored of their authentic order as they appeared within the supply doc. This sequential preservation helps the mannequin give attention to retrieving probably the most contextually related information with out introducing irrelevant distractions. The researchers demonstrated that this strategy considerably enhances reply era high quality, significantly in long-context situations, the place sustaining coherence is important.
The efficiency of the OP-RAG technique was totally examined in opposition to different main fashions. The researchers from NVIDIA carried out experiments utilizing public datasets, such because the EN.QA and EN.MC benchmarks from ∞Bench. Their outcomes confirmed a marked enchancment in each precision and effectivity in comparison with conventional long-context LLMs with out RAG. For instance, within the EN.QA dataset, which incorporates a median of 150,374 phrases per context, OP-RAG achieved a peak F1 rating of 47.25 when utilizing 48K tokens as enter, a major enchancment over fashions like GPT-4O. Equally, on the EN.MC dataset, OP-RAG outperformed different fashions by a substantial margin, reaching an accuracy of 88.65 with solely 24K tokens, whereas the normal Llama3.1 mannequin with out RAG may solely attain 71.62 accuracy utilizing 117K tokens.
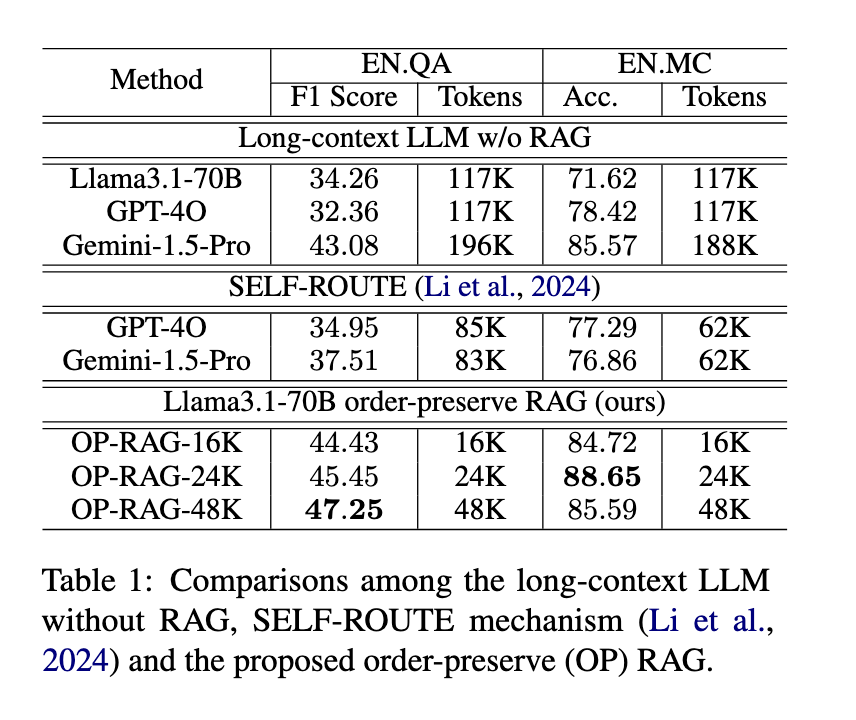
Additional comparisons confirmed that OP-RAG improved the standard of the generated solutions and dramatically decreased the variety of tokens wanted, making the mannequin extra environment friendly. Conventional long-context LLMs, akin to GPT-4O and Gemini-1.5-Professional, required almost double the variety of tokens in comparison with OP-RAG to realize decrease efficiency scores. This effectivity is especially beneficial in real-world functions, the place computational prices and useful resource allocation are crucial components in deploying large-scale language fashions.
In conclusion, OP-RAG presents a major breakthrough within the subject of retrieval-augmented era, providing an answer to the restrictions of long-context LLMs. By preserving the order of the retrieved textual content chunks, the strategy permits for extra coherent and contextually related reply era, even in large-scale question-answering duties. The researchers at NVIDIA have proven that this progressive strategy outperforms current strategies when it comes to high quality and effectivity, making it a promising answer for future developments in pure language processing.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


