


Graph neural networks (GNNs) have emerged as highly effective instruments for capturing advanced interactions in real-world entities and discovering purposes throughout varied enterprise domains. These networks excel at producing efficient graph entity embeddings by encoding each node options and structural insights, making them invaluable for quite a few downstream duties. GNNs have succeeded in node-level monetary fraud detection, link-level advice methods, and graph-level bioinformatics purposes. Nevertheless, the widespread adoption of GNNs faces important challenges. Privateness laws, intensifying enterprise competitors, and scalability points in billion-level graph studying have raised issues about direct knowledge sharing. These components complicate centralized knowledge storage and mannequin coaching on a single machine, necessitating new approaches to harness the ability of GNNs whereas addressing these urgent issues.
Federated Graph Studying (FGL) has been proposed as an answer to allow collaborative GNN coaching throughout a number of native methods whereas addressing privateness and scalability issues. Nevertheless, current FGL benchmarks, corresponding to FS-G and FedGraphNN, have important limitations. These benchmarks are restricted to a slender vary of utility domains, primarily specializing in quotation networks and advice methods. Additionally they lack the inclusion of current state-of-the-art FGL strategies, notably these developed in 2023 and 2024. Additionally, present benchmarks fall brief in simulating federated knowledge methods that account for graph properties, offering insufficient help for varied graph-based downstream duties, and providing restricted analysis views.
The absence of a complete benchmark for honest comparability hinders the event of FGL, regardless of rising analysis curiosity. The sphere faces challenges in addressing the variety of graph-based downstream duties (node, hyperlink, and graph ranges), accommodating distinctive graph traits (characteristic, label, and topology), and managing the complexity of FGL analysis (effectiveness, robustness, and effectivity). These components collectively impede a radical understanding of the present FGL panorama, highlighting the pressing want for a standardized and complete benchmark to drive progress on this promising subject.
Researchers from the Beijing Institute of Know-how, Solar Yat-sen College, Peking College, and Beijing Jiaotong College current OpenFGL, a complete benchmark proposed to handle the constraints of current FGL frameworks. This progressive platform integrates two generally used FGL situations, 38 datasets spanning 16 utility domains, 8 graph-specific distributed knowledge simulation methods, 18 state-of-the-art algorithms, and 5 graph-based downstream duties. OpenFGL implements these elements with a unified API, facilitating honest comparisons and future improvement in a user-friendly method. The benchmark supplies a radical analysis of current FGL algorithms, providing helpful insights into effectiveness, robustness, and effectivity. OpenFGL emphasizes quantifying statistics in distributed graphs to formally outline graph-based federated heterogeneity and highlights the potential of personalised, multi-client collaboration and privacy-preserving strategies. Additionally, it encourages FGL builders to prioritize algorithmic scalability and suggest progressive federated collaborative paradigms to enhance effectivity, particularly for industry-scale datasets.
Downside formulation
OpenFGL benchmark focuses on two consultant situations in federated graph studying (FGL): Graph-FL and Subgraph-FL. In Graph-FL, every consumer considers complete graphs as knowledge samples, whereas in Subgraph-FL, nodes inside a subgraph are handled as samples. The FGL system contains Okay shoppers, with every consumer ok managing a personal dataset D(ok) containing graph samples G(ok)_i. The variety of samples, NT, varies based mostly on the state of affairs: in Graph-FL, it represents the variety of graph samples, whereas in Subgraph-FL, NT is at all times 1.
The coaching course of in OpenFGL follows a four-step communication spherical, illustrated utilizing the FedAvg algorithm:
1. Obtain Message: Shoppers initialize native fashions with the server’s mannequin.
2. Native Replace: Shoppers prepare on personal knowledge to optimize task-specific targets.
3. Add Message: Shoppers ship up to date fashions and pattern counts to the server.
4. World Aggregation: The server combines consumer fashions weighted by pattern counts.
This structure allows collaborative studying throughout distributed graph knowledge whereas sustaining knowledge privateness and addressing the challenges of federated studying in graph-based situations.
OpenFGL focuses on two prevalent FGL situations: Graph-FL and Subgraph-FL. In Graph-FL, shoppers deal with complete graphs as knowledge samples, collaborating to develop highly effective fashions whereas sustaining knowledge privateness. This state of affairs is especially related in AI4Science purposes like drug discovery. Subgraph-FL, however, addresses real-world purposes corresponding to node-level fraud detection in finance and link-level advice methods. On this state of affairs, shoppers contemplate their knowledge as subgraphs of a bigger world graph, utilizing nodes and edges as coaching samples.
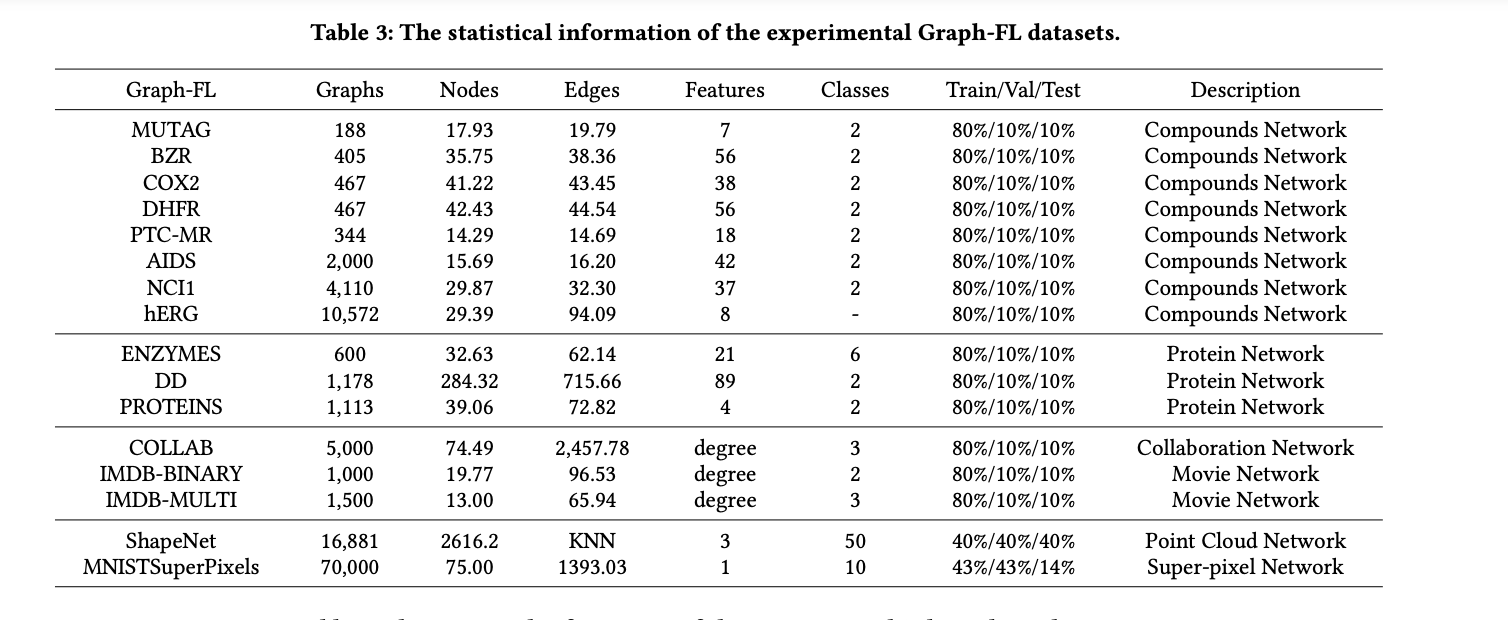
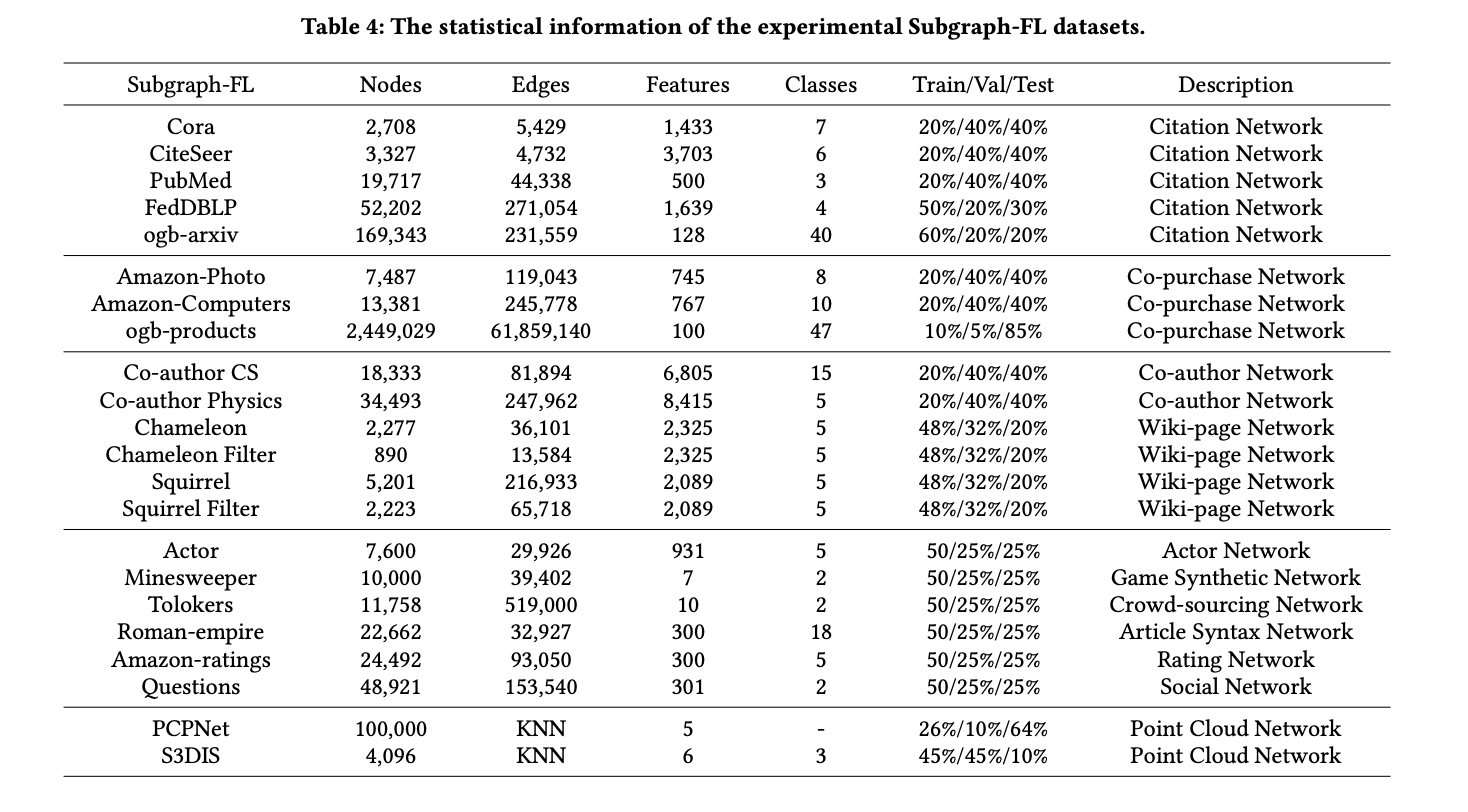
The benchmark incorporates a various assortment of public datasets from varied domains to guage FGL algorithms comprehensively. For Graph-FL, experiments are carried out on compound networks, protein networks, collaboration networks, film networks, super-pixel networks, and level cloud networks. Subgraph-FL experiments make the most of quotation networks, co-purchase networks, co-author networks, wiki-page networks, actor networks, recreation artificial networks, crowd-sourcing networks, article syntax networks, ranking networks, social networks, and level cloud networks.
OpenFGL introduces eight federated knowledge simulation methods to handle the problem of buying distributed graphs. These methods embody Characteristic Distribution Skew, Label Distribution Skew, Cross-Area Knowledge Skew, Topology Shift (for Graph-FL), and varied community-based splits for Subgraph-FL. These approaches simulate practical federated situations whereas sustaining controllable heterogeneity throughout shoppers, enabling a radical analysis of FGL algorithms’ adaptability and robustness.
OpenFGL integrates a various vary of GNN backbones to supply a broad spectrum of graph studying paradigms on the consumer facet. Graph-FL, implements varied well-designed polling methods based mostly on the Graph Isomorphism Community (GIN), together with TopKPooling, SAGPooling, EdgePooling, and PANPooling, together with weight-free MeanPooling. For Subgraph-FL, OpenFGL consists of prevalent fashions corresponding to GCN, GAT, GraphSAGE, SGC, and GCNII.
The benchmark incorporates a complete set of federated studying algorithms, starting from conventional laptop vision-based strategies to specialised FGL algorithms. These embody FedAvg, FedProx, Scaffold, MOON, FedDC, FedProto, FedNH, and FedTGP from CV-based FL, in addition to GCFL+ and FedStar for Graph-FL, and FedSage+, Fed-PUB, FedGTA, FGSSL, FedGL, AdaFGL, FGGP, FedDEP, and FedTAD for Subgraph-FL.
OpenFGL advocates for in-depth knowledge evaluation to grasp FGL heterogeneity, specializing in Characteristic KL Divergence, Label Distribution (together with homophily metrics), and Topology Statistics. The benchmark evaluates effectiveness utilizing varied metrics for various duties, corresponding to Accuracy and F1 rating for classification, MSE for regression, AP and AUC-ROC for hyperlink prediction, and clustering accuracy for node clustering.
To evaluate robustness, OpenFGL examines FGL algorithms underneath varied difficult situations, together with knowledge noise, sparsity, restricted consumer communication, generalization to advanced purposes, and privateness preservation utilizing Differential Privateness. Effectivity analysis considers each theoretical algorithm complexity and sensible elements like communication value and operating time.
OpenFGL conducts a complete investigation of FGL algorithms, addressing key questions associated to effectiveness, robustness, and effectivity. The examine goals to supply insights into the next areas:
Effectiveness:
1. Some great benefits of federated collaboration in comparison with native coaching.
2. Efficiency comparability between FGL algorithms and federated implementations of GNNs in Graph-FL and Subgraph-FL situations.
Robustness:
3. Algorithm efficiency underneath native noise and sparsity situations affecting options, labels, and edges.
4. Influence of low consumer participation charges on FGL algorithm efficiency.
5. Generalization capabilities of FGL algorithms throughout varied graph-specific distributed situations.
6. Assist for differential privateness (DP) safety in FGL algorithms.
Effectivity:
7. Theoretical algorithm complexity of FGL strategies.
8. Sensible operating effectivity of FGL algorithms.
These questions are designed to supply a complete analysis of FGL algorithms, masking their efficiency, adaptability to difficult situations, and computational effectivity. The outcomes of this intensive evaluation supply helpful insights for researchers and practitioners within the subject of federated graph studying, guiding future developments and purposes of those algorithms in real-world situations.
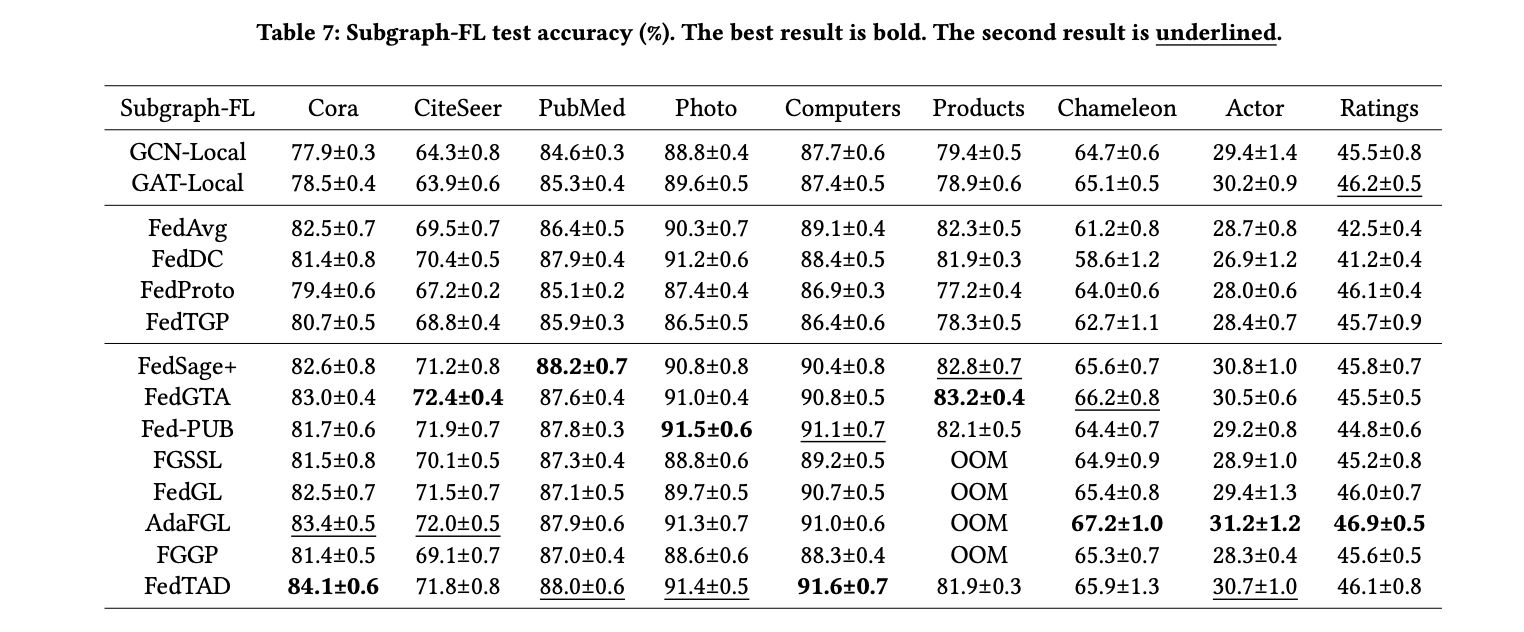
The OpenFGL benchmark examine revealed important insights into the effectiveness of FGL algorithms throughout Graph-FL and Subgraph-FL situations. Within the Graph-FL state of affairs, researchers discovered that federated collaboration yielded extra substantial advantages for larger-scale datasets, using ample knowledge sources. Nevertheless, current Graph-FL algorithms confirmed room for enchancment, notably in single-source domains and situations with restricted knowledge semantics. The Subgraph-FL state of affairs demonstrated extra superior improvement, with quite a few state-of-the-art baselines accessible. The examine highlighted that the optimistic affect of federated collaboration depends upon uniform distribution of node options, labels, and topology throughout shoppers. Additionally, FedTAD and AdaFGL emerged as prime performers in most Subgraph-FL instances. The analysis emphasised the necessity for Subgraph-FL algorithms to handle real-world deployment complexities, particularly in large-scale situations and graph-specific federated heterogeneity challenges.
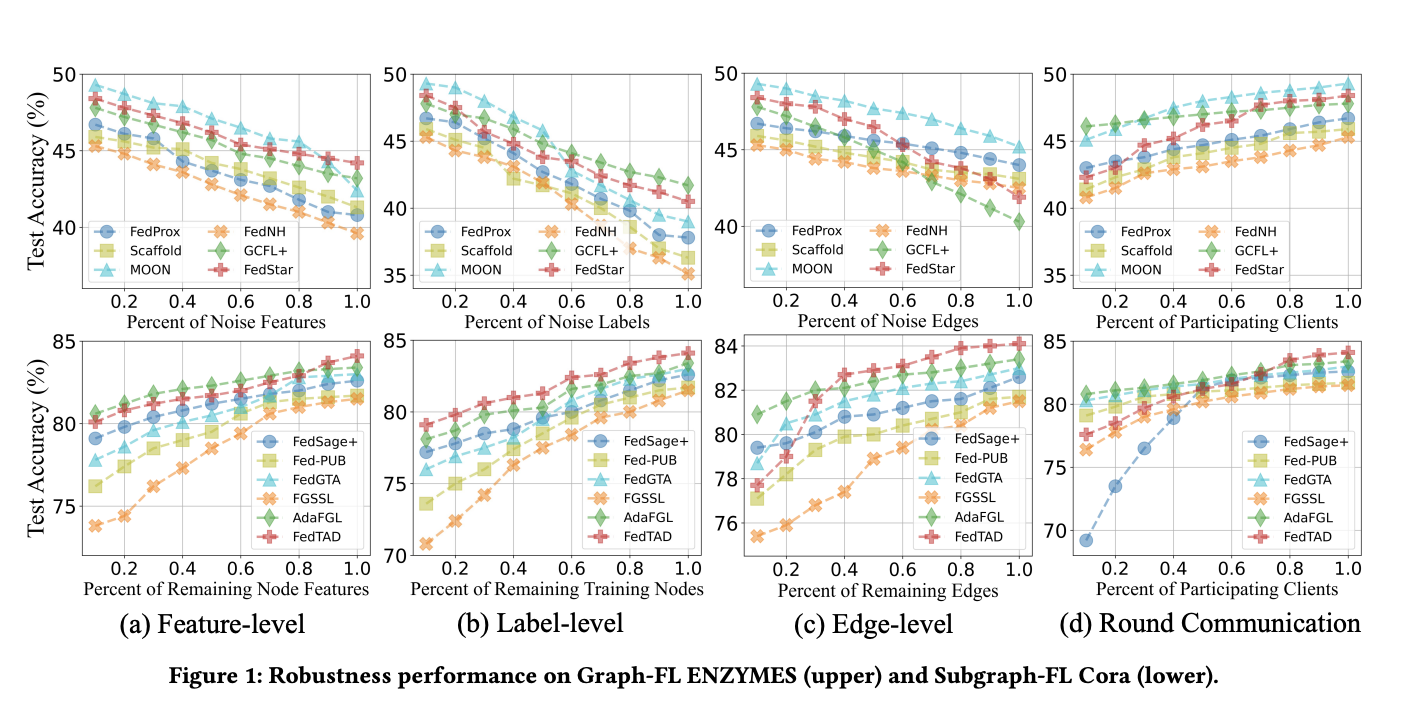
The OpenFGL benchmark additionally carried out a complete robustness evaluation of FGL algorithms, analyzing their efficiency underneath varied difficult situations. In native noise situations, FGL algorithms confirmed excessive sensitivity to edge noise in comparison with topology-agnostic FL algorithms, whereas demonstrating superior robustness underneath characteristic and label noise. The examine revealed that personalised methods are essential for addressing noise situations, although they fall barely brief in dealing with edge noise.

For native sparsity, algorithms leveraging multi-client collaboration, corresponding to FedSage+, AdaFGL, and FedTAD, demonstrated higher robustness, notably when mixed with topology mining strategies. In low consumer participation situations, FGL algorithms that rely much less on server messages and deal with well-designed native coaching mechanisms or custom-made world messages for every consumer carried out higher.
The generalization capabilities of FGL algorithms diversified throughout completely different knowledge simulations, with client-specific designs displaying potential drawbacks in situations aiming for generalization. The examine additionally examined privateness preservation utilizing DP, revealing a trade-off between predictive efficiency and privateness safety. Total, the robustness evaluation highlighted the significance of multi-client collaboration, personalised methods, and cautious consideration of privacy-preserving strategies in FGL algorithm design.
OpenFGL benchmark carried out a radical evaluation of the theoretical algorithm complexity for varied FL and FGL algorithms. This evaluation lined consumer reminiscence, server reminiscence, inference reminiscence, consumer time, server time, and inference time complexities. The examine revealed that the dominating complexity time period for many algorithms is O(Lmf) or O(kmf), the place L is the variety of layers, ok is the variety of characteristic propagation steps, m is the variety of edges, and f is the characteristic dimension.
Key findings from the complexity evaluation embody:
- Scalability stays a problem for FGL algorithms, particularly in billion-level situations, regardless of the distributed paradigm.
- Many current FGL approaches deal with well-designed client-side updates, introducing further computational overhead for native coaching. Examples embody contrastive studying (CL) and ensemble studying strategies.
- Some strategies, like FedSage+, Fed-PUB, and FedGTA, change further data throughout communication, resulting in various time-space complexities based mostly on their particular designs.
- Server-side optimization methods, corresponding to these employed by FedGL and FedTAD, present potential for enhancing federated coaching however might incur further computational prices.
- Prototype-based FL strategies (e.g., FedProto, FedNH, FedTGP) cut back communication complexity by exchanging class-specific embeddings as a substitute of full mannequin weights.
The OpenFGL benchmark additionally carried out an effectivity analysis of FGL algorithms, specializing in sensible elements corresponding to communication prices and operating time. The examine revealed a number of key findings:
- Prototype-based strategies, together with FedProto, FedTGP, and FGGP, demonstrated important benefits in lowering communication prices. These algorithms transmit prototype representations as a substitute of full mannequin weights, resulting in extra environment friendly knowledge switch. Nevertheless, they usually require further computation on both the consumer or server facet to keep up efficiency, which might negate their time effectivity benefits.
- Cross-client collaborative strategies, corresponding to FedGL and FedSage+, confronted challenges in deployment effectivity. The added delays ensuing from inter-client communication and synchronization diminished their total efficiency by way of operating time.
- Decoupled approaches, exemplified by AdaFGL, confirmed important effectivity benefits. These strategies goal to maximise native computational capability whereas minimizing communication prices, putting a stability between efficiency and effectivity.
Primarily based on these observations, the examine concluded that FGL algorithms leveraging prototypes and decoupled strategies (i.e., multi-client collaboration adopted by native updates) display substantial potential for purposes with stringent effectivity necessities. This perception highlights the significance of balancing communication effectivity with computational load distribution within the design of FGL algorithms for real-world deployments.
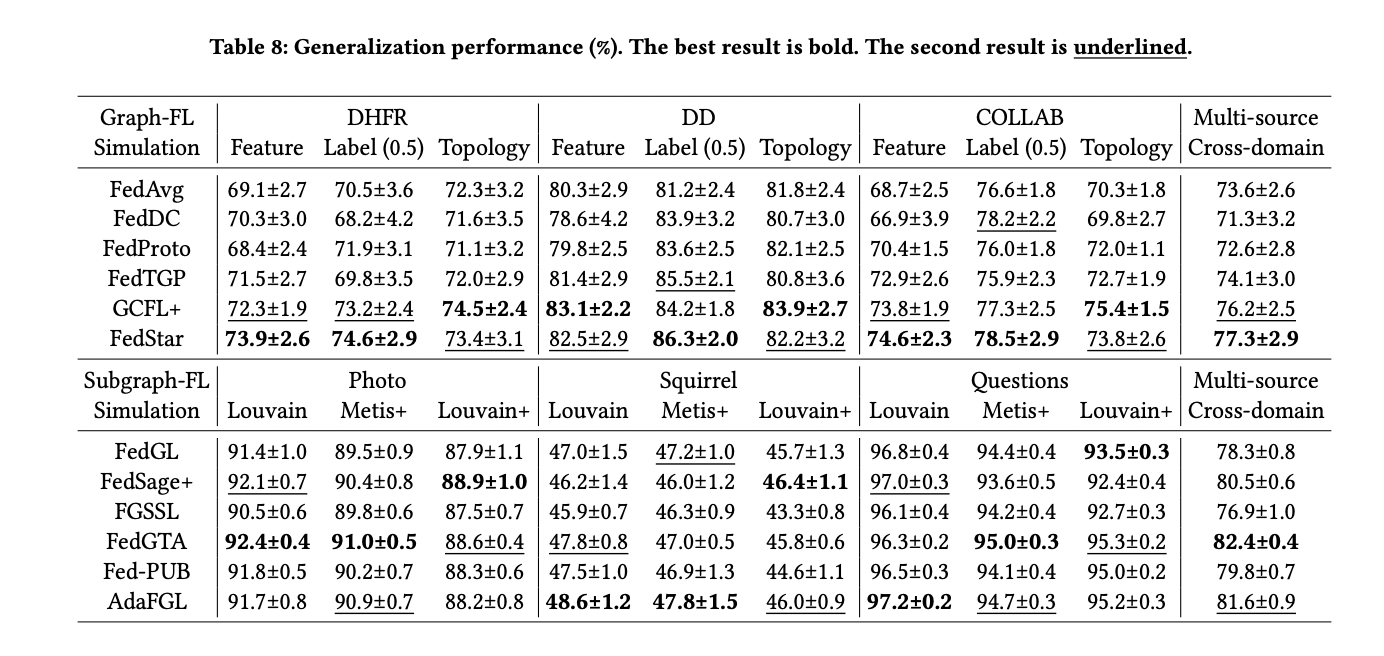
OpenFGL benchmark carried out a complete analysis of FGL algorithms, specializing in their effectiveness, robustness, and effectivity throughout varied situations. Within the Graph-FL state of affairs, federated collaboration demonstrated important advantages, notably for larger-scale datasets with ample knowledge sources. Nevertheless, current Graph-FL algorithms confirmed room for enchancment in single-source domains and situations with restricted knowledge semantics. The Subgraph-FL state of affairs exhibited extra superior improvement, with quite a few state-of-the-art baselines accessible. The examine revealed that the optimistic affect of federated collaboration depends upon the uniform distribution of node options, labels, and topology throughout shoppers. Additionally, FedTAD and AdaFGL emerged as prime performers in most Subgraph-FL instances, highlighting the potential of those algorithms for real-world purposes.

The effectivity analysis of FGL algorithms revealed important insights into their sensible efficiency. Prototype-based strategies like FedProto, FedTGP, and FGGP demonstrated notable benefits in lowering communication prices by transmitting prototype representations as a substitute of full mannequin weights. Nevertheless, these strategies usually required further computation on both the consumer or server facet to keep up efficiency, which negated their time effectivity benefits. Cross-client collaborative approaches, corresponding to FedGL and FedSage+, confronted challenges in deployment effectivity on account of added delays from inter-client communication and synchronization. In distinction, decoupled approaches like AdaFGL confirmed important effectivity benefits by maximizing native computational capability whereas minimizing communication prices. These findings counsel that FGL algorithms leveraging prototypes and decoupled strategies have substantial potential for purposes with stringent effectivity necessities.
This examine presents OpenFGL benchmark offering a complete analysis of FGL algorithms, revealing each promising developments and important challenges in real-world deployments. The examine highlighted a number of key areas for future analysis and improvement in FGL. Quantifying distributed graphs and addressing FGL heterogeneity is essential for enhancing effectiveness. The advanced interaction of node options, labels, and topology in graph knowledge necessitates extra subtle strategies for describing and dealing with graph-based heterogeneity challenges. Customized FGL strategies and multi-client collaboration emerge as promising approaches to reinforce robustness, notably in situations involving client-specific noise, low participation charges, and knowledge sparsity. Privateness preservation stays a essential concern, with present FGL algorithms probably compromising privateness in pursuit of efficiency. Future analysis ought to deal with creating algorithms with stricter privateness necessities and exploring superior privacy-preserving applied sciences. Lastly, to handle effectivity challenges, decoupled and scalable FGL approaches are wanted to deal with large-scale datasets and cut back communication delays. The sphere of FGL continues to be evolving, with quite a few analysis alternatives throughout varied graph varieties and studying paradigms. Continued enhancements to benchmarks like OpenFGL might be important in supporting future analysis prospects and advancing the state-of-the-art in federated graph studying.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be part of our Telegram Channel.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


