


Understanding multi-page paperwork and information movies is a standard activity in human each day life. To deal with such situations, Multimodal Giant Language Fashions (MLLMs) must be geared up with the flexibility to know a number of photos with wealthy visually-situated textual content info. Nonetheless, comprehending doc photos is more difficult than pure photos, because it requires a extra fine-grained notion to acknowledge all texts. Present approaches both add a high-resolution encoder or crop high-resolution photos into low-resolution sub-images, each of which have limitations.
Earlier researchers have tried to resolve the problem of understanding doc photos utilizing varied methods. Some works proposed including a high-resolution encoder to higher seize the fine-grained textual content info in doc photos. Others selected to crop high-resolution photos into low-resolution sub-images and let the Giant Language Mannequin perceive their relationship.
Whereas these approaches have achieved promising efficiency, they undergo from a standard problem – the massive variety of visible tokens required to characterize a single doc picture. For instance, the InternVL 2 mannequin prices a mean of 3k visible tokens on the single-page doc understanding benchmark DocVQA. Such lengthy visible token sequences not solely lead to lengthy inference instances but additionally occupy a major quantity of GPU reminiscence, vastly limiting their software in situations that contain understanding full paperwork or movies.
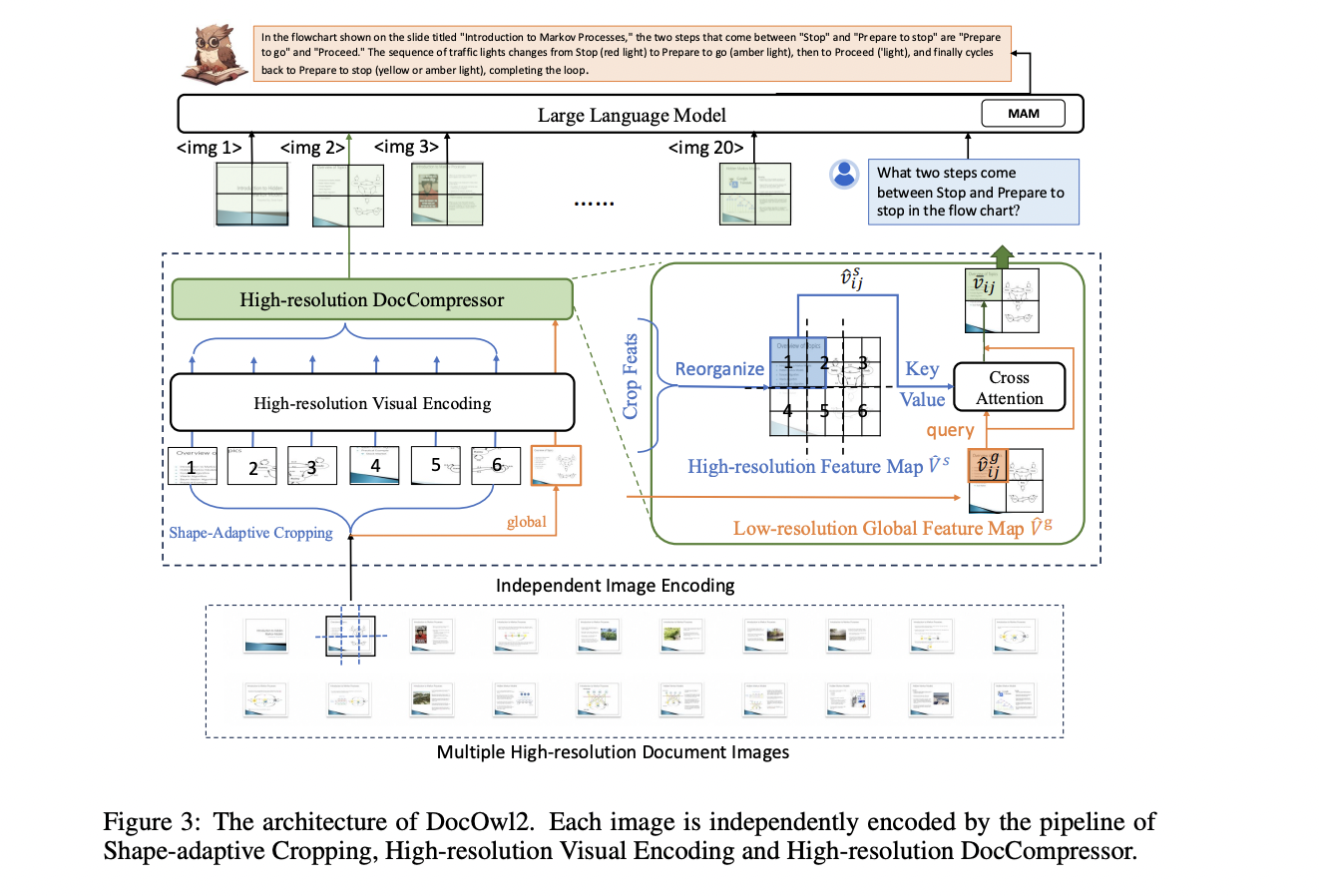
Researchers from Alibaba Group and Renmin College of China have proposed a strong compressing structure referred to as Excessive-resolution DocCompressor. This methodology makes use of the visible options of a world low-resolution picture because the compressing steering (question), as the worldwide characteristic map can successfully seize the general format info of the doc.
As a substitute of attending to all high-resolution options, the Excessive-resolution DocCompressor collects a bunch of high-resolution options with an identical relative positions within the uncooked picture because the compressing objects for every question from the worldwide characteristic map. This layout-aware strategy helps to higher summarize the textual content info inside a selected format area.
As well as, the researchers argue that compressing visible options after the vision-to-text module of the Multimodal Giant Language Mannequin can higher preserve the textual semantics within the doc photos, as that is analogous to summarizing texts in Pure Language Processing.
The DocOwl2 mannequin makes use of a Form-adaptive Cropping Module and a low-resolution imaginative and prescient encoder to encode high-resolution doc photos. The Form-adaptive Cropping Module cuts the uncooked picture into a number of low-resolution sub-images, and the low-resolution imaginative and prescient encoder is used to encode each the sub-images and the worldwide picture. The mannequin then makes use of a vision-to-text module referred to as H-Reducer to ensemble the horizontal visible options and align the dimension of the imaginative and prescient options with the Giant Language Mannequin. Along with that, DocOwl2 features a high-resolution compressor, which is the important thing element of the Excessive-resolution DocCompressor. This compressor makes use of the visible options of the worldwide low-resolution picture because the question and collects a bunch of high-resolution options with an identical relative positions within the uncooked picture because the compressing objects for every question. This layout-aware strategy helps to higher summarize the textual content info inside a selected format area. Lastly, the compressed visible tokens of a number of photos or pages are concatenated with textual content directions and enter to a Giant Language Mannequin for multimodal understanding.
The researchers in contrast the DocOwl2 mannequin with state-of-the-art Multimodal Giant Language Fashions on 10 single-image doc understanding benchmarks, 2 multi-page doc understanding benchmarks, and 1 text-rich video understanding benchmark. They thought of each the question-answering efficiency (measured by ANLS) and the First Token Latency (in seconds) to guage the effectiveness of their mannequin. For the single-image doc understanding activity, the researchers divided the baselines into three teams: (a) fashions with out Giant Language Fashions as decoders, (b) Multimodal LLMs with a mean of over 1,000 visible tokens per doc picture, and (c) Multimodal LLMs with lower than 1,000 visible tokens.
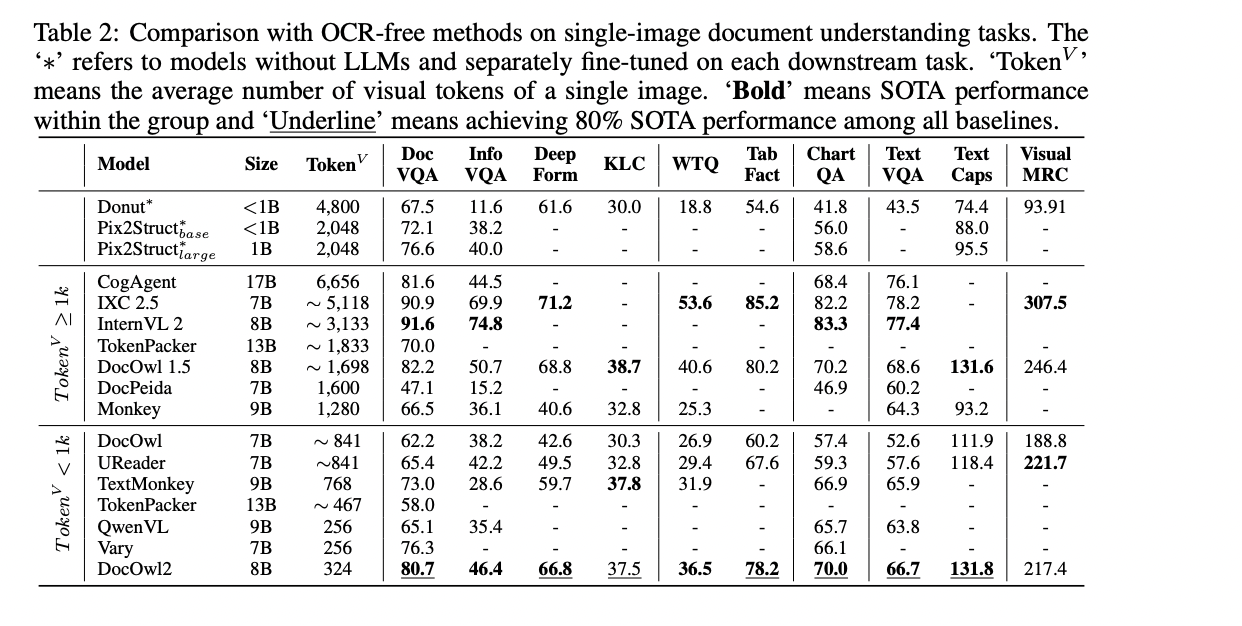
The outcomes present that though the fashions particularly fine-tuned on every downstream dataset carried out effectively, the Multimodal LLMs demonstrated the potential for generalized OCR-free doc understanding. In comparison with different Multimodal LLMs with lower than 1,000 visible tokens, the DocOwl2 mannequin achieved higher or comparable efficiency on the ten benchmarks. Notably, with fewer visible tokens, DocOwl2 outperformed fashions like TextMonkey and TokenPacker, which additionally aimed to compress visible tokens, demonstrating the effectiveness of the Excessive-resolution DocCompressor.
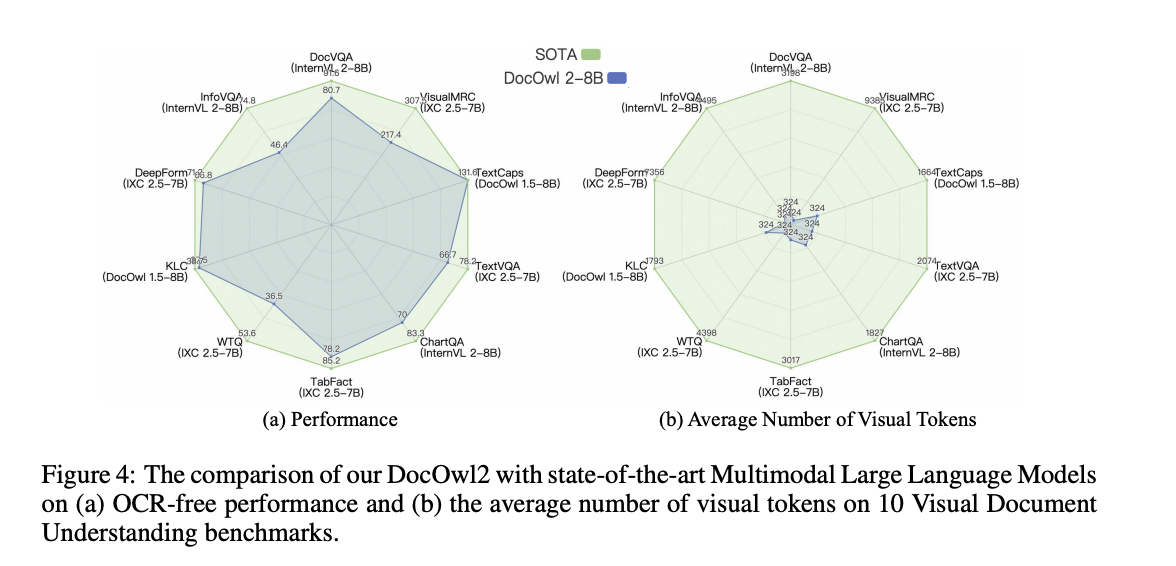
Additionally, when in comparison with state-of-the-art Multimodal LLMs with over 1,000 visible tokens, the DocOwl2 mannequin achieved over 80% of their efficiency whereas utilizing lower than 20% of the visible tokens. For the multi-page doc understanding and text-rich video understanding duties, the DocOwl2 mannequin additionally demonstrated superior efficiency and considerably decrease First Token Latency in comparison with different Multimodal LLMs that may be fed greater than 10 photos below a single A100-80G GPU.
This research presents mPLUG-DocOwl2, a Multimodal Giant Language Mannequin able to environment friendly OCR-free Multi-page Doc Understanding. The strong Excessive-resolution DocCompressor structure compresses every high-resolution doc picture into simply 324 tokens utilizing cross-attention with world visible options as steering. On single-image benchmarks, DocOwl2 outperforms current compressing strategies and matches state-of-the-art MLLMs whereas utilizing fewer visible tokens. It additionally achieves OCR-free state-of-the-art efficiency on multi-page doc and text-rich video understanding duties with a lot decrease latency. The researchers emphasize that utilizing 1000’s of visible tokens per doc web page is commonly redundant and a waste of computational sources. They hope that DocOwl2 will deliver consideration to balancing environment friendly picture illustration and high-performance doc understanding.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


