


Textual content classification has change into an important software in numerous functions, together with opinion mining and subject classification. Historically, this process required in depth handbook labeling and a deep understanding of machine studying strategies, presenting important obstacles to entry. The arrival of enormous language fashions (LLMs) like ChatGPT has revolutionized this subject, enabling zero-shot classification with out extra coaching. This breakthrough has led to the widespread adoption of LLMs in political and social sciences. Nevertheless, researchers face challenges when utilizing these fashions for textual content evaluation. Many high-performing LLMs are proprietary and closed, missing transparency of their coaching knowledge and historic variations. This opacity conflicts with open science ideas. Additionally, the substantial computational necessities and utilization prices related to LLMs could make large-scale knowledge labeling prohibitively costly. Consequently, there’s a rising name for researchers to prioritize open-source fashions and supply robust justification when choosing closed techniques.
Pure language inference (NLI) has emerged as a flexible classification framework, providing an alternative choice to generative Giant Language Fashions (LLMs) for textual content evaluation duties. In NLI, a “premise” doc is paired with a “speculation” assertion, and the mannequin determines if the speculation is true based mostly on the premise. This method permits a single NLI-trained mannequin to perform as a common classifier throughout numerous dimensions with out extra coaching. NLI fashions supply important benefits when it comes to effectivity, as they will function with a lot smaller parameter counts in comparison with generative LLMs. As an example, a BERT mannequin with 86 million parameters can carry out NLI duties, whereas the smallest efficient zero-shot generative LLMs require 7-8 billion parameters. This distinction in dimension interprets to considerably diminished computational necessities, making NLI fashions extra accessible for researchers with restricted assets. Nevertheless, NLI classifiers commerce flexibility for effectivity, as they’re much less adept at dealing with advanced, multi-condition classification duties in comparison with their bigger LLM counterparts.
Researchers from the Division of Politics, Princeton College, Pennsylvania State College and Manship College of Mass Communication, Louisiana State College, suggest Political DEBATE (DeBERTa Algorithm for Textual Entailment) fashions, out there in Giant and Base variations, which symbolize a big development in open-source textual content classification for political science. These fashions, with 304 million and 86 million parameters, respectively, are designed to carry out zero-shot and few-shot classification of political textual content with effectivity similar to a lot bigger proprietary fashions. The DEBATE fashions obtain their excessive efficiency by two key methods: domain-specific coaching with fastidiously curated knowledge and the adoption of the NLI classification framework. This method permits using smaller encoder language fashions like BERT for classification duties, dramatically lowering computational necessities in comparison with generative LLMs. The researchers additionally introduce the PolNLI dataset, a complete assortment of over 200,000 labeled political paperwork spanning numerous subfields of political science. Importantly, the workforce commits to versioning each fashions and datasets, making certain replicability and adherence to open science ideas.
The Political DEBATE fashions are skilled on the PolNLI dataset, a complete corpus comprising 201,691 paperwork paired with 852 distinctive entailment hypotheses. This dataset is categorized into 4 important duties: stance detection, subject classification, hate-speech and toxicity detection, and occasion extraction. PolNLI attracts from a various vary of sources, together with social media, information articles, congressional newsletters, laws, and crowd-sourced responses. It additionally incorporates tailored variations of established tutorial datasets, such because the Supreme Court docket Database. Notably, the overwhelming majority of the textual content in PolNLI is human-generated, with solely a small fraction (1,363 paperwork) being LLM-generated. The dataset’s development adopted a rigorous five-step course of: accumulating and vetting datasets, cleansing and getting ready knowledge, validating labels, speculation augmentation, and splitting the information. This meticulous method ensures each high-quality labels and various knowledge sources, offering a strong basis for coaching the DEBATE fashions.
The Political DEBATE fashions are constructed upon the DeBERTa V3 base and enormous fashions, which have been initially fine-tuned for general-purpose NLI classification. This selection was motivated by DeBERTa V3’s superior efficiency on NLI duties amongst transformer fashions of comparable dimension. The pre-training on normal NLI duties facilitates environment friendly switch studying, permitting the fashions to rapidly adapt to political textual content classification. The coaching course of utilized the Transformers library, with progress monitored through the Weights and Biases library. After every epoch, mannequin efficiency was evaluated on a validation set, and checkpoints have been saved. The ultimate mannequin choice concerned each quantitative and qualitative assessments. Quantitatively, metrics similar to coaching loss, validation loss, Matthew’s Correlation Coefficient, F1 rating, and accuracy have been thought of. Qualitatively, the fashions have been examined throughout numerous classification duties and doc sorts to make sure constant efficiency. Along with this, the fashions’ stability was assessed by inspecting their habits on barely modified paperwork and hypotheses, making certain robustness to minor linguistic variations.
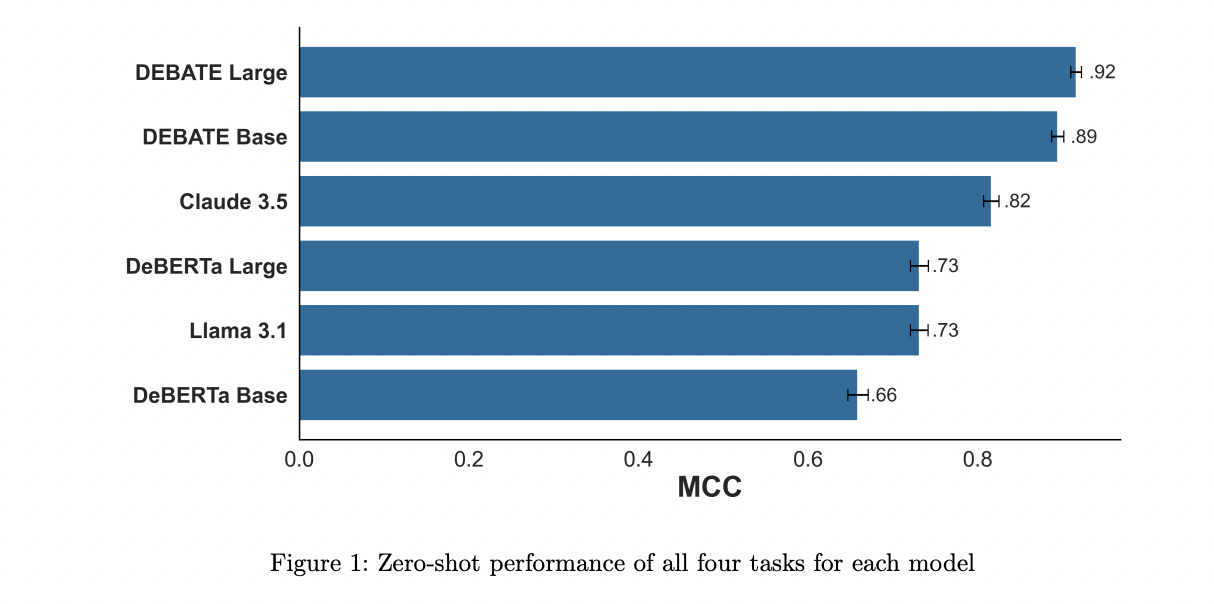
The Political DEBATE fashions have been benchmarked towards 4 different fashions representing numerous choices for zero-shot classification. These included the DeBERTa base and enormous general-purpose NLI classifiers, that are presently the most effective publicly out there NLI classifiers. The open-source Llama 3.1 8B, a smaller generative LLM able to operating on high-end desktop GPUs or built-in GPUs like Apple M sequence chips, was additionally included within the comparability. Additionally, Claude 3.5 Sonnet, a state-of-the-art proprietary LLM, was examined to symbolize the cutting-edge of economic fashions. Notably, GPT-4 was excluded from the benchmark because of its involvement within the validation technique of the ultimate labels. The first efficiency metric used was the Matthews Correlation Coefficient (MCC), chosen for its robustness in binary classification duties in comparison with metrics like F1 and accuracy. MCC, starting from -1 to 1 with larger values indicating higher efficiency, gives a complete measure of mannequin effectiveness throughout numerous classification situations.
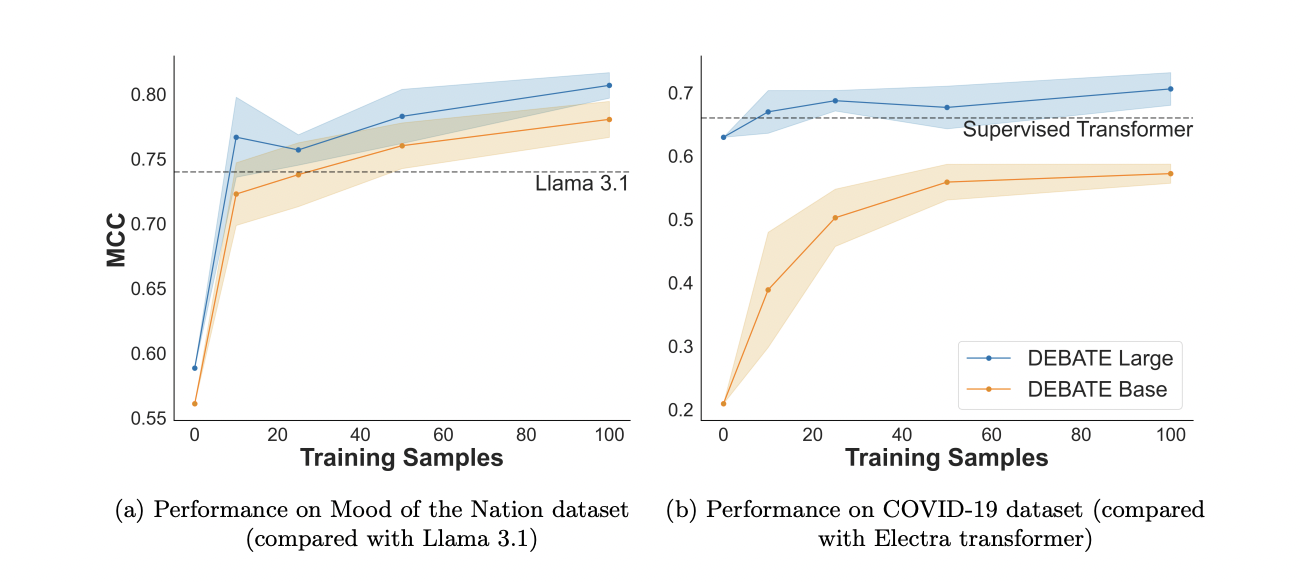
The NLI classification framework allows fashions to rapidly adapt to new classification duties, demonstrating environment friendly few-shot studying capabilities. The Political DEBATE fashions showcase this capability, studying new duties with solely 10-25 randomly sampled paperwork, rivaling or surpassing the efficiency of supervised classifiers and generative language fashions. This functionality was examined utilizing two real-world examples: the Temper of the Nation ballot and a research on COVID-19 tweet classification.
The testing process concerned zero-shot classification adopted by few-shot studying with 10, 25, 50, and 100 randomly sampled paperwork. The method was repeated 10 instances for every pattern dimension to calculate confidence intervals. Importantly, the researchers used default settings with out optimization, emphasizing the fashions’ out-of-the-box usability for few-shot studying situations.
The DEBATE fashions demonstrated spectacular few-shot studying efficiency, attaining outcomes similar to or higher than specialised supervised classifiers and bigger generative fashions. This effectivity extends to computational necessities as nicely. Whereas preliminary coaching on the massive PolNLI dataset might take hours or days with high-end GPUs, few-shot studying could be completed in minutes with out specialised {hardware}, making it extremely accessible for researchers with restricted computational assets.
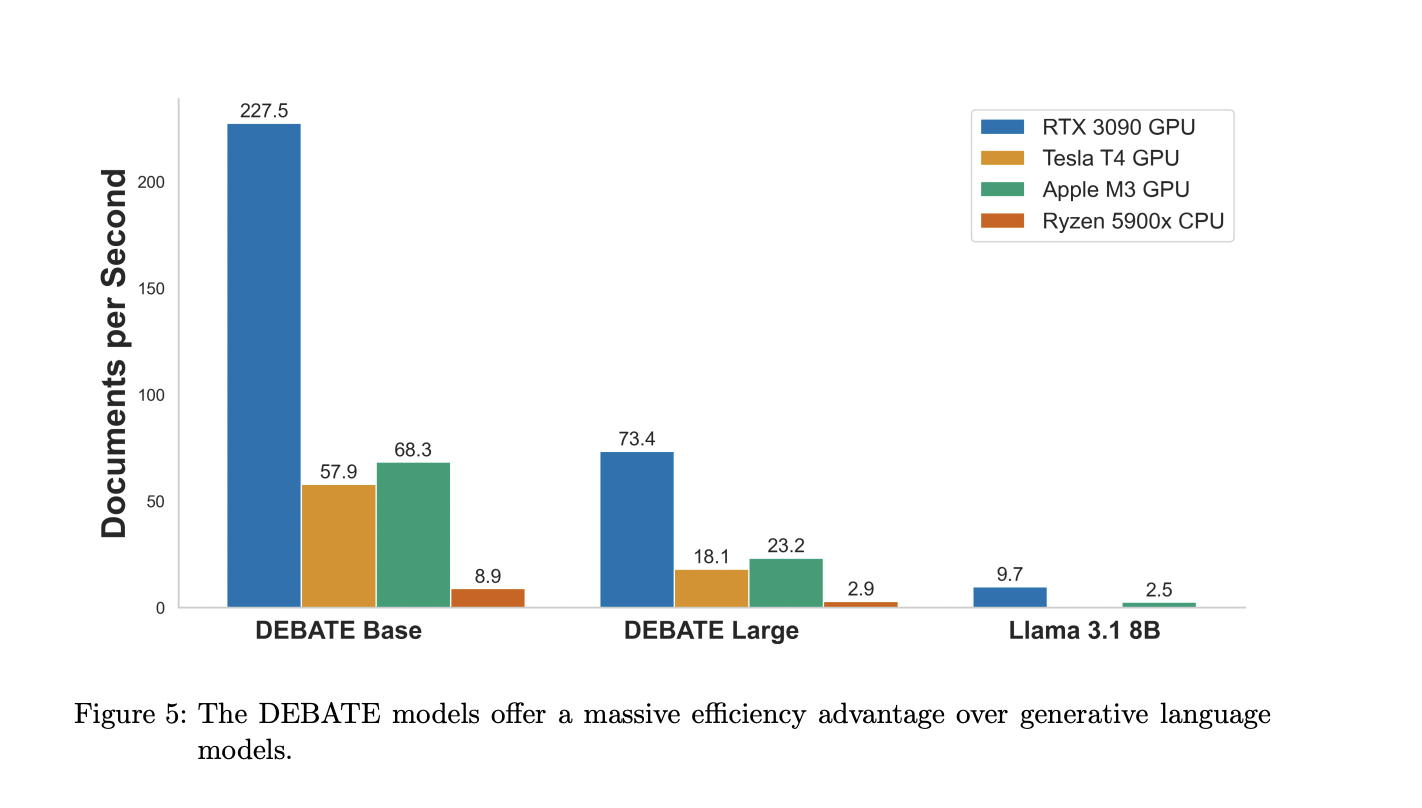
A value-effectiveness evaluation was carried out by operating the DEBATE fashions and Llama 3.1 on numerous {hardware} configurations, utilizing a pattern of 5,000 paperwork from the PolNLI check set. The {hardware} examined included an NVIDIA GeForce RTX 3090 GPU, an NVIDIA Tesla T4 GPU (out there free on Google Colab), a Macbook Professional with an M3 max chip, and an AMD Ryzen 9 5900x CPU.
The outcomes demonstrated that the DEBATE fashions supply important velocity benefits over small generative LLMs like Llama 3.1 8B throughout all examined {hardware}. Whereas high-performance GPUs just like the RTX 3090 offered the most effective velocity, the DEBATE fashions nonetheless carried out effectively on extra accessible {hardware} similar to laptop computer GPUs (M3 max) and free cloud GPUs (Tesla T4).
Key findings embrace:
1. DEBATE fashions persistently outperformed Llama 3.1 8B in processing velocity throughout all {hardware} sorts.
2. Excessive-end GPUs just like the RTX 3090 provided the most effective efficiency for all fashions.
3. Even on extra modest {hardware} just like the M3 max chip or the free Tesla T4 GPU, DEBATE fashions maintained comparatively brisk classification speeds.
4. The effectivity hole between DEBATE fashions and Llama 3.1 was significantly pronounced on consumer-grade {hardware}.
This evaluation highlights the DEBATE fashions’ superior cost-effectiveness and accessibility, making them a viable choice for researchers with various computational assets.
This analysis presents Political DEBATE fashions that reveal important promise as accessible, environment friendly instruments for textual content evaluation throughout stance, subject, hate speech, and occasion classification in political science. For these fashions, the researchers additionally current a complete dataset PolNLI. Their design emphasizes open science ideas, providing a reproducible different to proprietary fashions. Future analysis ought to concentrate on extending these fashions to new duties, similar to entity and relationship identification, and incorporating extra various doc sources. Increasing the PolNLI dataset and additional refining these fashions can improve their generalizability throughout political communication contexts. Collaborative efforts in knowledge sharing and mannequin improvement can drive the creation of domain-adapted language fashions that function useful public assets for researchers in political science.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


