


The rising reliance on massive language fashions for coding help poses a major drawback: how finest to evaluate real-world affect on programmer productiveness? Present approaches, equivalent to static bench-marking based mostly on datasets equivalent to HumanEval, measure the correctness of the code however can not seize the dynamic, human-in-the-loop interplay of actual programming exercise. With LLMs more and more being built-in into coding environments and deployed in real-time, counsel, or chat settings, it’s now time to rethink measuring not solely the flexibility of LLMs to finish duties but additionally their affect on human productiveness. A much-needed contribution towards the event of an analysis framework that’s extra pragmatic could be to make sure that these LLMs truly enhance true coding productiveness exterior the lab.
Though loads of LLMs are designed for programming duties, the analysis of many of those LLMs stays largely dependent upon static benchmarks equivalent to HumanEval and MBPP, during which fashions are judged not based mostly on how nicely they will help human programmers however based mostly on the correctness of code generated by themselves. Whereas accuracy is important to quantitatively measure benchmarks, sensible facets in real-world eventualities are typically uncared for. All kinds of programmers regularly have interaction LLMs and modify their work in an iterative method in real-world sensible settings. None of those conventional approaches seize key metrics, equivalent to how a lot time programmers spend coding, how steadily programmers settle for LLM ideas or the diploma to which LLMs truly assist resolve complicated issues. The hole between theoretical rankings and sensible usefulness casts a query on the generalisability of those strategies since they can’t symbolize precise LLM use, and the precise productiveness acquire is tough to measure.
Researchers from MIT, Carnegie Mellon College, IBM Analysis, UC Berkeley, and Microsoft developed RealHumanEval, a groundbreaking platform designed for human-centric analysis of LLMs in programming. It permits real-time analysis of LLMs through two modes of interplay: ideas over autocomplete or through chat-based help. Detailed person interplay logs are recorded on the platform for code ideas accepted and the time taken to finish a activity. Actual-human Eval is past any static benchmarks by specializing in human productiveness metrics that give so significantly better comprehension of how nicely LLMs carry out as soon as built-in with real-world coding workflows. This helps to bridge the hole between theoretical efficiency and observe, offering perception into methods during which LLMs assist or hinder the coding course of.
RealHumanEval permits customers to work together each via autocomplete and thru chat, recording a number of facets of those interactions. The present analysis examined seven completely different LLMs, together with fashions from the GPT and CodeLlama households on a set of 17 coding duties with various complexity. The system logged an excessive amount of productiveness metrics: completion time per activity, variety of accomplished duties, and the way usually a person accepted a recommended LLM code. For this experiment, 243 members took half, and all of the collected knowledge was analyzed to see how completely different LLMs contributed to way more effectivity in coding. It discusses these intimately, and it offers the outcomes of analyzing the interactions to supply perception into the effectiveness of LLMs within the wild coding atmosphere and provides detailed nuances of human-LLM collaboration.
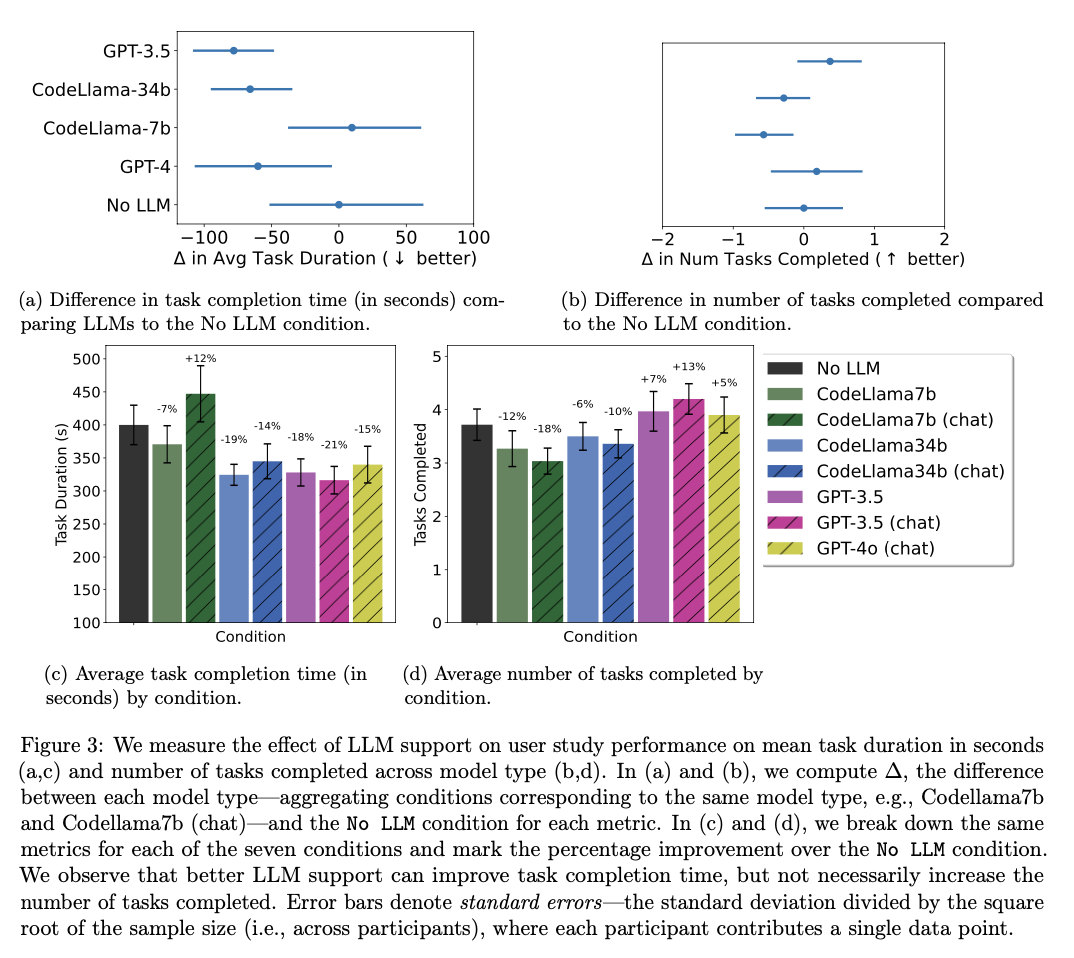
RealHumanEval testing of LLMs demonstrated that the higher-performing fashions on benchmarks yield important good points in coding productiveness, above all by saving time. For instance, than the earlier fashions, GPT-3.5 and CodeLlama-34b accomplished duties 19% and 15% quicker, respectively, for programmers. At different occasions, the acquire on productiveness measures can’t be acknowledged as uniform for all fashions into consideration. A working example is that there’s inadequate constructive proof relating to CodeLlama-7b. Additionally, though the time taken to finish the duties has been diminished, the no. of duties accomplished didn’t have a lot change, that means LLMs will pace up the completion of particular person duties however by and enormous they don’t essentially increment the overall no. of duties completed in a given time-frame. Once more, code suggestion acceptance was completely different for varied fashions; GPT-3.5 had extra in the best way of the customers’ acceptance than the remaining. These outcomes put to mild that whereas LLMs can doubtlessly foster productiveness, in precise energy to spice up output, that is extremely contextual.
In conclusion, RealHumanEval is a landmark testbed for LLMs in programming as a result of it focuses on human-centered productiveness metrics fairly than conventional static benchmarks and due to this fact gives a much-needed complementary view of how nicely LLMs help real-world programmers. RealHumanEval permits deep perception into effectivity good points and person interplay patterns that assist convey the strengths and limitations of LLMs when utilized in coding environments. Such could be a contribution to this line of inquiry for future analysis and improvement towards AI-assisted programming by offering precious insights into optimizing such instruments for sensible use.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Fantastic-Tuned Fashions: Predibase Inference Engine (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.


