

")
The evolution of machine studying has introduced vital developments in language fashions, that are foundational to duties like textual content era and question-answering. Amongst these, transformers and state-space fashions (SSMs) are pivotal, but their effectivity when dealing with lengthy sequences has posed challenges. As sequence size will increase, conventional transformers undergo from quadratic complexity, resulting in prohibitive reminiscence and computational calls for. To handle these points, researchers and organizations have explored different architectures, resembling Mamba, a state-space mannequin with linear complexity that gives scalability and effectivity for long-context duties.
Giant-scale language fashions typically face challenges in managing computational prices, particularly as they scale as much as billions of parameters. As an example, whereas Mamba gives linear complexity benefits, its rising measurement leads to vital power consumption and coaching prices, making deployment tough. These limitations are exacerbated by the excessive useful resource calls for of fashions like GPT-based architectures, that are historically educated and inferred at full precision (e.g., FP16 or BF16). Furthermore, as demand grows for environment friendly, scalable AI, exploring excessive quantization strategies has turn into important to make sure sensible deployment in resource-constrained settings.
Researchers have explored methods resembling pruning, low-bit quantization, and key-value cache optimizations to mitigate these challenges. Quantization, which reduces the bit-width of mannequin weights, has proven promising outcomes by compressing fashions with out substantial efficiency degradation. Nonetheless, most of those efforts concentrate on transformer-based fashions. The conduct of SSMs, significantly Mamba, beneath excessive quantization nonetheless must be explored, creating a spot in creating scalable and environment friendly state-space fashions for real-world purposes.
Researchers from the Mohamed bin Zayed College of Synthetic Intelligence and Carnegie Mellon College launched Bi-Mamba, a 1-bit scalable Mamba structure designed for low-memory, high-efficiency eventualities. This progressive method applies binarization-aware coaching to Mamba’s state-space framework, enabling excessive quantization whereas sustaining aggressive efficiency. Bi-Mamba was developed in mannequin sizes of 780 million, 1.3 billion, and a couple of.7 billion parameters and educated from scratch utilizing an autoregressive distillation loss. The mannequin makes use of high-precision instructor fashions resembling LLaMA2-7B to information coaching, guaranteeing sturdy efficiency.
The structure of Bi-Mamba employs selective binarization of its linear modules whereas retaining different elements at full precision to steadiness effectivity and efficiency. Enter and output projections are binarized utilizing FBI-Linear modules, which combine learnable scaling and shifting elements for optimum weight illustration. This ensures that binarized parameters align carefully with their full-precision counterparts. The mannequin’s coaching utilized 32 NVIDIA A100 GPUs to course of giant datasets, together with 1.26 trillion tokens from sources like RefinedWeb and StarCoder.
Intensive experiments demonstrated Bi-Mamba’s aggressive edge over present fashions. On datasets like Wiki2, PTB, and C4, Bi-Mamba achieved perplexity scores of 14.2, 34.4, and 15.0, considerably outperforming options like GPTQ and Bi-LLM, which exhibited perplexities as much as 10× increased. Additionally, Bi-Mamba achieved zero-shot accuracies of 44.5% for the 780M mannequin, 49.3% for the two.7B mannequin, and 46.7% for the 1.3B variant on downstream duties resembling BoolQ and HellaSwag. This demonstrated its robustness throughout varied duties and datasets whereas sustaining energy-efficient efficiency.
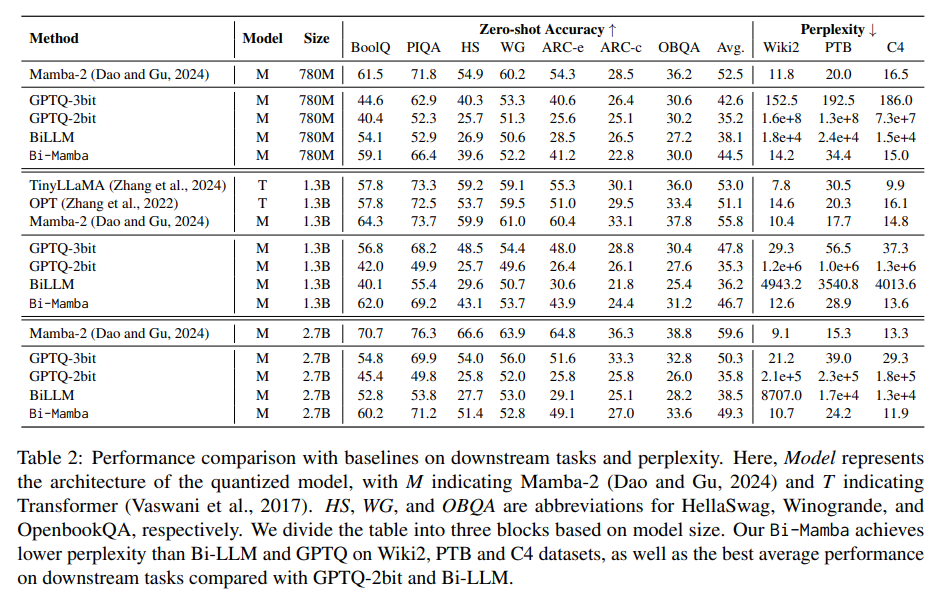
The research’s findings spotlight a number of key takeaways:
- Effectivity Features: Bi-Mamba achieves over 80% storage compression in comparison with full-precision fashions, decreasing storage measurement from 5.03GB to 0.55GB for the two.7B mannequin.
- Efficiency Consistency: The mannequin retains comparable efficiency to full-precision counterparts with considerably diminished reminiscence necessities.
- Scalability: Bi-Mamba’s structure permits efficient coaching throughout a number of mannequin sizes, with aggressive outcomes even for the most important variants.
- Robustness in Binarization: By selectively binarizing linear modules, Bi-Mamba avoids the efficiency degradation sometimes related to naive binarization strategies.

In conclusion, Bi-Mamba represents a big step ahead in addressing the twin challenges of scalability and effectivity in giant language fashions. By leveraging binarization-aware coaching and specializing in key architectural optimizations, the researchers demonstrated that state-space fashions may obtain excessive efficiency beneath excessive quantization. This innovation enhances power effectivity, reduces useful resource consumption, and units the stage for future developments in low-bit AI methods, opening avenues for deploying large-scale fashions in sensible, resource-limited environments. Bi-Mamba’s sturdy outcomes underscore its potential as a transformative method for extra sustainable and environment friendly AI applied sciences.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Digital GenAI Convention ft. Meta, Mistral, Salesforce, Harvey AI & extra. Be a part of us on Dec eleventh for this free digital occasion to study what it takes to construct large with small fashions from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and extra.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

