


The environment friendly coaching of imaginative and prescient fashions continues to be a significant problem in AI as a result of Transformer-based fashions undergo from computational bottlenecks as a result of quadratic complexity of self-attention mechanisms. Additionally, the ViTs, though extraordinarily promising outcomes on arduous imaginative and prescient duties, require in depth computational and reminiscence sources, making them unimaginable to make use of below real-time or resource-constrained situations. Not too long ago, SSMs have gained extra curiosity attributable to their scalability relating to dealing with long-sequence information. Nonetheless, even state-of-the-art SSM-based fashions resembling Imaginative and prescient Mamba require very excessive reminiscence and computation coaching prices. Effectively overcoming these limitations will drastically develop the appliance of AI imaginative and prescient fashions inside areas that demand a fragile steadiness between accuracy and computational effectivity, resembling in autonomous techniques or medical imaging.
The present work to reinforce the effectivity within the imaginative and prescient fashions is being carried out primarily for the ViTs, with two such classical methods. Token pruning is carried out to take away a number of tokens that carry much less info, whereas token merging is carried out to mix the tokens retaining the essence with lowered complexity. Though these strategies enhance the computational effectivity of Transformer fashions, they carry out much less successfully for SSMs, which must maintain long-range dependencies with out sacrificing the effectivity of processing sequential information. Moreover that, most conventional token fusion methods carry out uniform fusion over all layers, which causes noticeable accuracy loss and will degrade the efficiency of SSM-based imaginative and prescient fashions in crucial purposes. Due to this fact, these strategies failed to supply the fashions with a fascinating steadiness between accuracy and effectivity, resembling Vim.
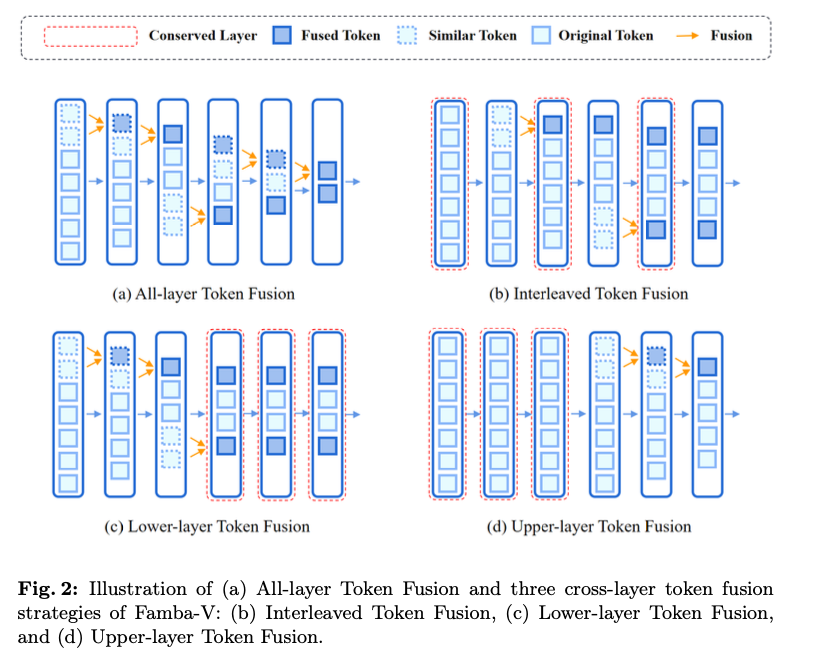
Researchers from Ohio State College introduce Famba-V, a focused, cross-layer token fusion technique for Imaginative and prescient Mamba, which overcomes limitations by selectively making use of token fusion throughout particular layers primarily based on their contribution to effectivity and accuracy. Token merging and detection of comparable tokens in Famba-V depend on cosine similarity. Three fusion methods are adopted: Interleaved, Decrease-layer, and Higher-layer Token Fusion. These methods goal completely different layers of the Vim mannequin in pursuit of the optimum trade-off between useful resource effectivity and efficiency. As an illustration, the Interleaved technique applies fusion to each different layer. On this case, after a comparatively small loss in accuracy, some effectivity positive factors are gained. One other, the Higher-layer technique, will cut back interference with the preliminary layers of information processing. This structure provides the perfect efficiency for Famba-V, whereas it has large computational and reminiscence effectivity appropriate for resource-limited purposes.
CIFAR-100 dataset benchmarking was achieved by Vim-Ti and Vim-S variants of Vim structure, having 7 million and 26 million parameters respectively. That is achieved in Famba-V by measuring the token similarity in every chosen layer, averaging them out for comparable token pairs. Each technique was designed to have roughly equal numbers of lowered tokens throughout completely different methods in order that comparisons are honest. Experiments have been achieved on the NVIDIA A100 GPU, and a typical coaching configuration with some normal augmentation-random cropping and label smoothing with mix-up was conducive to robustness in outcomes. By offering varied fusion methods, Famba-V allows the person to decide on an acceptable trade-off between accuracy and effectivity relating to their calls for on computation.
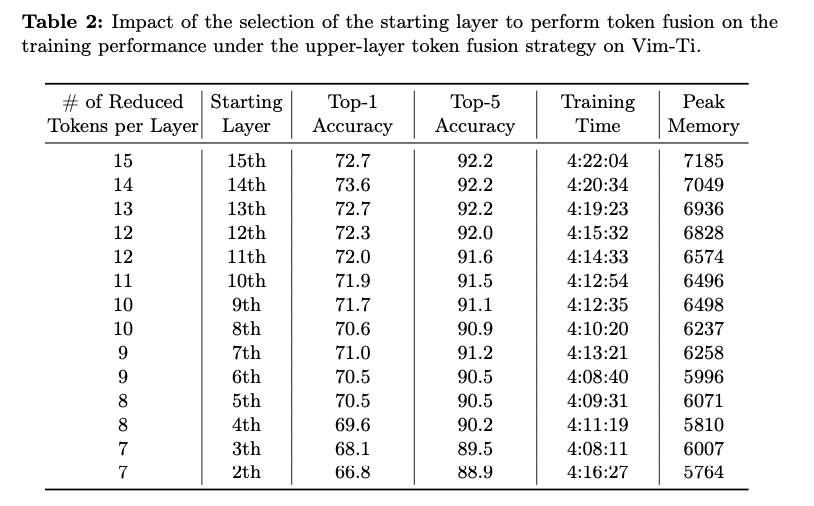
The appliance of Famba-V to CIFAR-100 has proven an efficient steadiness between effectivity and accuracy throughout the fashions of Vim: for all variants of the fashions of Vim, coaching time and reminiscence utilization have been drastically lowered, whereas sustaining accuracy values close to the mannequin variants that aren’t token-fused. The token fusion technique on the Higher-layer on Vim-S maintained a Prime-1 accuracy of 75.2%, which is a minimal discount from the non-fused baseline of 76.9%, but considerably economizes on reminiscence utilization, thus exhibiting the massive potential of the technique in sustaining mannequin integrity with a lot better effectivity. Likewise, the Interleaved fusion technique on Vim-Ti achieved a Prime-1 accuracy of 67.0% and lowered coaching time to lower than 4 hours, as soon as extra demonstrating the flexibility of Famba-V to tailor its configuration to greatest exploit given sources. This ease in adapting to computational constraints with excellent efficiency makes Famba-V sensible for such purposes that require effectivity with reliability in such resource-constrained settings.
In conclusion, Famba-V’s cross-layer token fusion framework presents a considerable development in coaching effectivity for Imaginative and prescient Mamba fashions. Famba-V achieves a versatile steadiness between accuracy and effectivity by implementing three cross-layer methods: Interleaved, Decrease-layer, and Higher-layer Fusion. It notably reduces coaching time and reminiscence consumption on CIFAR-100 with out sacrificing mannequin robustness. The adaptability in design makes Famba-V of explicit worth for real-world imaginative and prescient duties; therefore, extending the appliance of SSM-based fashions in resource-constrained environments. As well as, additional research could be carried out to see how Famba-V could be built-in with different methods to reinforce the effectivity of discovering an excellent higher optimization of SSM-based fashions for imaginative and prescient duties.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Effective-Tuned Fashions: Predibase Inference Engine (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


