


Weight decay and ℓ2 regularization are essential in machine studying, particularly in limiting community capability and decreasing irrelevant weight parts. These methods align with Occam’s razor rules and are central to discussions on generalization bounds. Nevertheless, current research have questioned the correlation between norm-based measures and generalization in deep networks. Though weight decay is extensively utilized in state-of-the-art deep networks like GPT-3, CLIP, and PALM, its impact remains to be not absolutely understood. The emergence of latest architectures like transformers and practically one-epoch language modeling has additional difficult the applicability of classical outcomes to fashionable deep-learning settings.
Efforts to grasp and make the most of weight decay have considerably progressed over time. Latest research have highlighted the distinct results of weight decay and ℓ2 regularization, particularly for optimizers like Adam. It additionally highlights weight decay’s affect on optimization dynamics, together with its impression on efficient studying charges in scale-invariant networks. Different strategies embody its position in regularizing the enter Jacobian and creating particular dampening results in sure optimizers. Furthermore, a current investigation accommodates the connection between weight decay, coaching length, and generalization efficiency. Whereas weight decay has been proven to enhance check accuracy, the enhancements are sometimes modest, suggesting that implicit regularization performs a big position in deep studying.
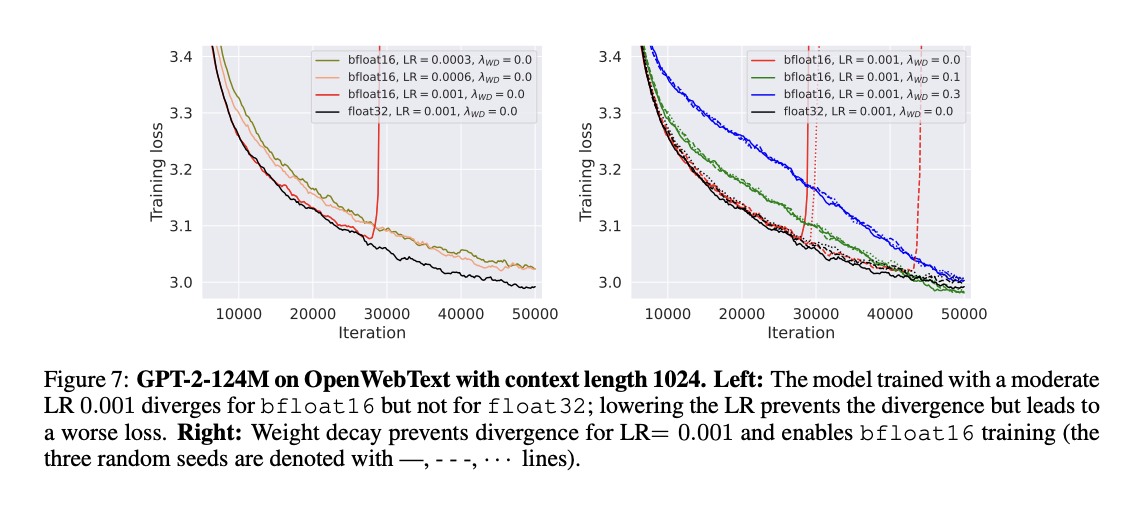
Researchers from the Concept of Machine Studying Lab at EPFL have proposed a brand new perspective on the position of weight decay in fashionable deep studying. Their work challenges the normal view of weight decay as primarily a regularization method, as studied in classical studying concept. They’ve proven that weight decay considerably modifies optimization dynamics in overparameterized and underparameterized networks. Furthermore, weight decay prevents sudden lack of divergences in bfloat16 mixed-precision coaching, an important facet of LLM coaching. It applies throughout varied architectures, from ResNets to LLMs, indicating that the first benefit of weight decay lies in its capacity to affect coaching dynamics somewhat than appearing as an specific regularizer.
The experiments are carried out by coaching GPT-2 fashions on OpenWebText utilizing the NanoGPT repository. A 124M parameter mannequin (GPT-2-Small) educated for 50,000 iterations is used, with modifications to make sure practicality inside educational constraints. It’s discovered that coaching and validation losses stay intently aligned throughout totally different weight decay values. The researchers suggest two major mechanisms for weight decay in LLMs:
- Improved optimization, as noticed in earlier research.
- Prevention of loss divergences when utilizing bfloat16 precision.
These findings distinction with data-limited environments the place generalization is the important thing focus, highlighting the significance of optimization velocity and coaching stability in LLM coaching.
Experimental outcomes reveal an important impact of weight decay in enabling steady bfloat16 mixed-precision coaching for LLMs. Bfloat16 coaching accelerates the method and reduces GPU reminiscence utilization, enabling the coaching of bigger fashions and greater batch sizes. Nevertheless, even the extra steady bfloat16 can exhibit late-training spikes that hurt mannequin efficiency. It is usually discovered that weight decay prevents these divergences. Whereas float16 coaching is understood to come across points with reasonably massive values exceeding 65,519, it poses a distinct problem, and its restricted precision can result in issues when including community parts with various scales. Weight decay successfully solves these precision-related points by stopping extreme weight progress.
On this paper, researchers offered a brand new perspective on the position of weight decay in fashionable deep studying. They concluded that weight decay exhibits three distinct results in deep studying:
- Offering regularization when mixed with stochastic noise.
- Enhancing optimization of coaching loss
- Making certain stability in low-precision coaching.
Researchers are difficult the normal concept that weight decay primarily acts as an specific regularizer. As an alternative, they argue that its widespread use in fashionable deep studying is because of its capability to create helpful modifications in optimization dynamics. This viewpoint gives a unified rationalization for the success of weight decay throughout totally different architectures and coaching settings, starting from imaginative and prescient duties with ResNets to LLMs. Future approaches embody mannequin coaching and hyperparameter tuning within the deep studying subject.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report shall be launched in late October/early November 2024. Click on right here to arrange a name!

Sajjad Ansari is a closing 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.


