


The development of huge language fashions (LLMs) in pure language processing has considerably improved numerous domains. As extra advanced fashions are developed, evaluating their outputs precisely turns into important. Historically, human evaluations have been the usual strategy for assessing high quality, however this course of is time consuming and must be extra scalable for the speedy tempo of mannequin growth.
Salesforce AI Analysis introduces SFR-Choose, a household of three LLM-based decide fashions, to revolutionize how LLM outputs are evaluated. Constructed utilizing Meta Llama 3 and Mistral NeMO, SFR-Choose is available in three sizes: 8 billion (8B), 12 billion (12B), and 70 billion (70B) parameters. Every mannequin is designed to carry out a number of analysis duties, akin to pairwise comparisons, single scores, and binary classification. These fashions have been developed to help analysis groups in quickly and successfully evaluating new LLMs.
One of many important limitations of utilizing conventional LLMs as judges is their susceptibility to biases and inconsistencies. Many decide fashions, as an illustration, exhibit place bias, the place their judgment is influenced by the order through which responses are introduced. Others might present size bias, favoring longer responses that appear extra full even when shorter ones are extra correct. To handle these points, the SFR-Choose fashions are skilled utilizing Direct Desire Optimization (DPO), permitting the mannequin to study from constructive and detrimental examples. This coaching methodology permits the mannequin to develop a nuanced understanding of analysis duties, lowering biases and making certain constant judgments.
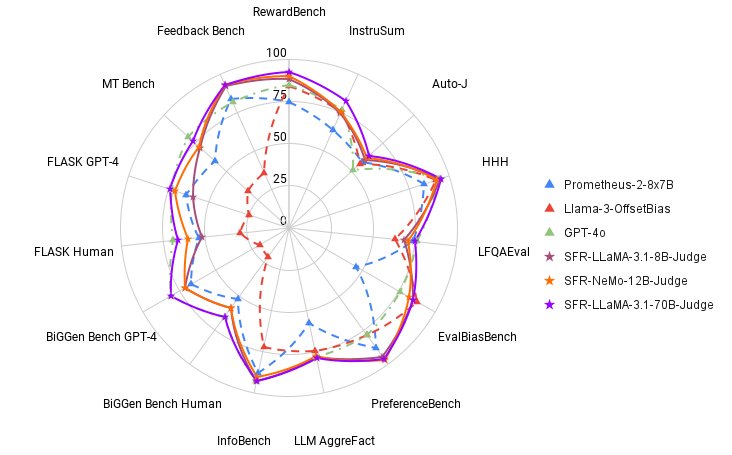
The SFR-Choose fashions have been examined on 13 benchmarks throughout three analysis duties, demonstrating superior efficiency to current decide fashions, together with proprietary fashions like GPT-4o. Notably, SFR-Choose achieved the perfect efficiency on 10 of the 13 benchmarks, setting a brand new customary in LLM-based analysis. For instance, on the RewardBench leaderboard, SFR-Choose attained an accuracy of 92.7%, marking the primary and second instances any generative decide mannequin crossed the 90% threshold. These outcomes spotlight the effectiveness of SFR-Choose not solely as an analysis mannequin but additionally as a reward mannequin able to guiding downstream fashions in reinforcement studying from human suggestions (RLHF) eventualities.
SFR-Choose’s coaching strategy entails three distinct knowledge codecs. The primary, the Chain-of-Thought Critique, helps the mannequin generate structured and detailed analyses of the evaluated responses. This critique enhances the mannequin’s capability to cause about advanced inputs and produce knowledgeable judgments. The second format, Normal Judgment, simplifies evaluations by eradicating the critique offering extra direct suggestions on whether or not the responses meet the required standards. Lastly, Response Deduction permits the mannequin to infer what a high-quality response appears like, reinforcing its judgment capabilities. These three knowledge codecs work in conjunction to strengthen the mannequin’s capability to supply well-rounded and correct evaluations.
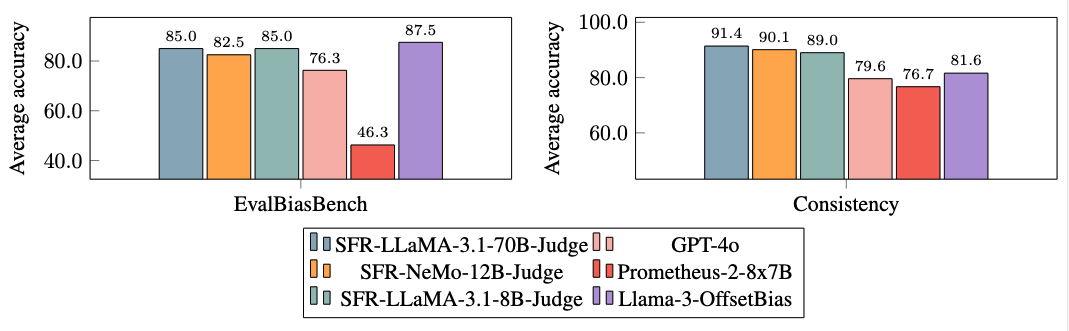
In depth experiments revealed that SFR-Choose fashions are considerably much less biased than competing fashions, as demonstrated by their efficiency on EvalBiasBench, a benchmark designed to check for six forms of bias. The fashions exhibit excessive ranges of pairwise order consistency throughout a number of benchmarks, indicating that their judgments stay secure even when the order of responses is altered. This robustness positions SFR-Choose as a dependable answer for automating the analysis of LLMs, lowering the reliance on human annotators, and offering a scalable different for mannequin evaluation.
Key takeaways from the analysis:
- Excessive Accuracy: SFR-Choose achieved high scores on 10 of 13 benchmarks, together with a 92.7% accuracy on RewardBench, outperforming many state-of-the-art decide fashions.
- Bias Mitigation: The fashions demonstrated decrease ranges of bias, together with size and place bias, in comparison with different decide fashions, as confirmed by their efficiency on EvalBiasBench.
- Versatile Functions: SFR-Choose helps three important analysis duties – pairwise comparisons, single scores, and binary classification, making it adaptable to varied analysis eventualities.
- Structured Explanations: Not like many decide fashions, SFR-Choose is skilled to supply detailed explanations for its judgments, lowering the black-box nature of LLM-based evaluations.
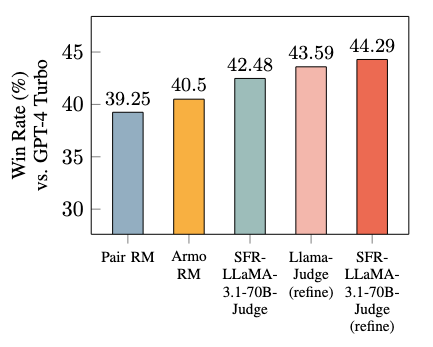
- Efficiency Enhance in Downstream Fashions: The mannequin’s explanations can enhance downstream fashions’ outputs, making it an efficient software for RLHF eventualities.
In conclusion, the introduction of SFR-Choose by Salesforce AI Analysis marks a big leap ahead within the automated analysis of huge language fashions. By leveraging Direct Desire Optimization and a various set of coaching knowledge, the analysis crew has created a household of decide fashions which are each sturdy and dependable. These fashions can study from various examples, present detailed suggestions, and cut back frequent biases, making them invaluable instruments for evaluating and refining generative content material. SFR-Choose units a brand new benchmark in LLM-based analysis and opens the door for additional developments in automated mannequin evaluation.
Try the Paper and Particulars. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report shall be launched in late October/early November 2024. Click on right here to arrange a name!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


