


Massive language fashions (LLMs) have gained important consideration in machine studying, shifting the main focus from optimizing generalization on small datasets to decreasing approximation error on huge textual content corpora. This paradigm shift presents researchers with new challenges in mannequin improvement and coaching methodologies. The first goal has advanced from stopping overfitting by means of regularization strategies to successfully scaling up fashions to devour huge quantities of information. Researchers now face the problem of balancing computational constraints with the necessity for improved efficiency on downstream duties. This shift necessitates a reevaluation of conventional approaches and the event of sturdy methods to harness the facility of large-scale language pretraining whereas addressing the restrictions imposed by accessible computing assets.
The shift from a generalization-centric paradigm to a scaling-centric paradigm in machine studying has necessitated reevaluating conventional approaches. Google DeepMind researchers have recognized key variations between these paradigms, specializing in minimizing approximation error by means of scaling moderately than decreasing generalization error by means of regularization. This shift challenges typical knowledge, as practices that have been efficient within the generalization-centric paradigm might not yield optimum leads to the scaling-centric method. The phenomenon of “scaling regulation crossover” additional complicates issues, as strategies that improve efficiency at smaller scales might not translate successfully to bigger ones. To mitigate these challenges, researchers suggest creating new rules and methodologies to information scaling efforts and successfully examine fashions at unprecedented scales the place conducting a number of experiments is commonly infeasible.
Machine studying goals to develop features able to making correct predictions on unseen knowledge by understanding the underlying construction of the information. This course of includes minimizing the check loss on unseen knowledge whereas studying from a coaching set. The check error could be decomposed into the generalization hole and the approximation error (coaching error).
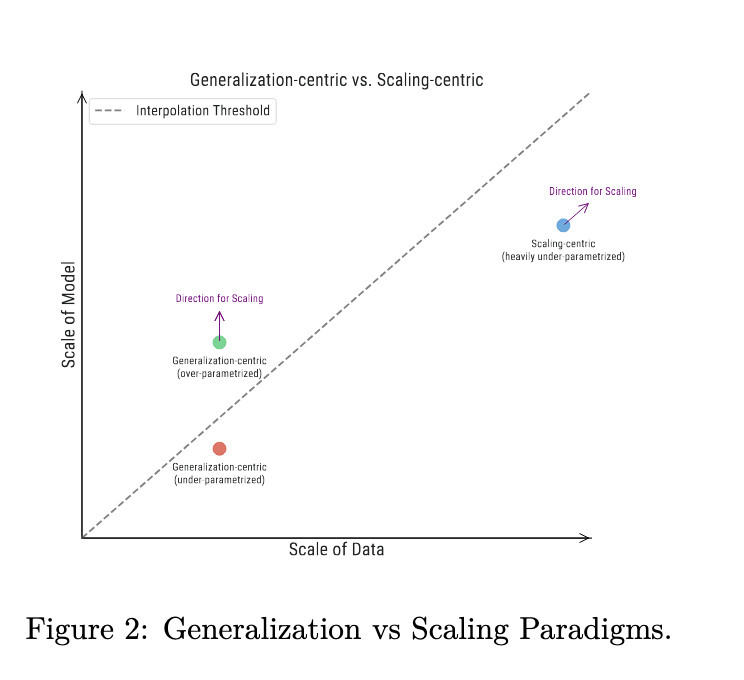
Two distinct paradigms have emerged in machine studying, differentiated by the relative and absolute scales of information and fashions:
1. The generalization-centric paradigm, which operates with comparatively small knowledge scales, is additional divided into two sub-paradigms:
a) The classical bias-variance trade-off regime, the place mannequin capability is deliberately constrained.
b) The fashionable over-parameterized regime, the place mannequin scale considerably surpasses knowledge scale.
2. The scaling-centric paradigm, characterised by massive knowledge and mannequin scales, with knowledge scale exceeding mannequin scale.
These paradigms current completely different challenges and require distinct approaches to optimize mannequin efficiency and obtain desired outcomes.
The proposed technique employs a decoder-only transformer structure skilled on the C4 dataset, using the NanoDO codebase. Key architectural options embody Rotary Positional Embedding, QK-Norm for consideration computation, and untied head and embedding weights. The mannequin makes use of Gelu activation with F = 4D, the place D is the mannequin dimension and F is the hidden dimension of the MLP. Consideration heads are configured with a head dimension of 64, and the sequence size is ready to 512.
The mannequin’s vocabulary dimension is 32,101, and the overall parameter rely is roughly 12D²L, the place L is the variety of transformer layers. Most fashions are skilled to Chinchilla optimality, utilizing 20 × (12D²L + DV) tokens. Compute necessities are estimated utilizing the system F = 6ND, the place F represents the variety of floating-point operations.
For optimization, the tactic employs AdamW with β1 = 0.9, β2 = 0.95, ϵ = 1e-20, and a coupled weight decay λ = 0.1. This mixture of architectural selections and optimization methods goals to boost the mannequin’s efficiency within the scaling-centric paradigm.
Within the scaling-centric paradigm, conventional regularization strategies are being reevaluated for his or her effectiveness. Three standard regularization strategies generally used within the generalization-centric paradigm are express L2 regularization and the implicit regularization results of huge studying charges and small batch sizes. These strategies have been instrumental in mitigating overfitting and decreasing the hole between coaching and check losses in smaller-scale fashions.
Nevertheless, within the context of huge language fashions and the scaling-centric paradigm, the need of those regularization strategies is being questioned. As fashions function in a regime the place overfitting is much less of a priority as a result of huge quantity of coaching knowledge, the standard advantages of regularization might now not apply. This shift prompts researchers to rethink the function of regularization in mannequin coaching and to discover different approaches which may be extra appropriate for the scaling-centric paradigm.
The scaling-centric paradigm presents distinctive challenges in mannequin comparability as conventional validation set approaches develop into impractical at huge scales. The phenomenon of scaling regulation crossover additional complicates issues, as efficiency rankings noticed at smaller scales might not maintain true for bigger fashions. This raises the crucial query of the right way to successfully examine fashions when coaching is possible solely as soon as at scale.
In distinction, the generalization-centric paradigm depends closely on regularization as a tenet. This method has led to insights into hyperparameter selections, weight decay results, and the advantages of over-parameterization. It additionally explains the effectiveness of strategies like weight sharing in CNNs, locality, and hierarchy in neural community architectures.
Nevertheless, the scaling-centric paradigm might require new guiding rules. Whereas regularization has been essential for understanding and enhancing generalization in smaller fashions, its function and effectiveness in large-scale language fashions are being reevaluated. Researchers at the moment are challenged to develop strong methodologies and rules that may information the event and comparability of fashions on this new paradigm, the place conventional approaches might now not apply.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 52k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report can be launched in late October/early November 2024. Click on right here to arrange a name!
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.


