


Synthetic intelligence has remodeled code era, with massive language fashions (LLMs) for code now integral to software program engineering. These fashions assist code synthesis, debugging, and optimization duties by analyzing huge codebases. Nonetheless, the event of those code-focused LLMs faces vital challenges. Coaching requires high-quality instruction-following information, sometimes gathered by labor-intensive human annotation or leveraging data from bigger proprietary fashions. Whereas these approaches enhance mannequin efficiency, they introduce points round information accessibility, licensing, and price. Because the demand for clear, environment friendly, and scalable strategies for coaching these fashions grows, revolutionary options that bypass these challenges with out sacrificing efficiency develop into essential.
Data distillation from proprietary fashions can violate licensing restrictions, limiting its use in open-source tasks. One main limitation is that human-curated information, although invaluable, is expensive and difficult to scale. Some open-source strategies, like OctoCoder and OSS-Instruct, have tried to beat these limitations. Nonetheless, they usually want extra efficiency benchmarks and transparency necessities. These limitations underscore the necessity for an answer that maintains excessive efficiency and aligns with open-source values and transparency.
Researchers from the College of Illinois Urbana-Champaign, Northeastern College, College of California Berkeley, ServiceNow Analysis, Hugging Face, Roblox, and Cursor AI launched a novel strategy referred to as SelfCodeAlign. This strategy allows LLMs to coach independently, producing high-quality instruction-response pairs with out human intervention or proprietary mannequin information. In contrast to different fashions that depend on human annotations or data switch from massive fashions, SelfCodeAlign generates directions autonomously by extracting various coding ideas from seed information. The mannequin then makes use of these ideas to create distinctive duties and produces a number of responses. These responses are paired with automated take a look at instances and are validated in a managed sandbox atmosphere. Solely these responses that move are used for remaining instruction tuning, making certain the info is correct and various.
SelfCodeAlign’s methodology begins by extracting seed code snippets from a big corpus, specializing in range and high quality. The preliminary dataset, “The Stack V1,” is filtered to pick 250,000 high-quality Python capabilities from a pool of 5 million, utilizing stringent high quality checks. After selecting these snippets, the mannequin breaks down every into elementary coding ideas, reminiscent of information kind conversion or sample matching. It then generates duties and responses primarily based on these ideas, assigning problem ranges and classes to make sure selection. This multi-step strategy ensures high-quality information and minimizes biases, making the mannequin adaptable to varied coding challenges.
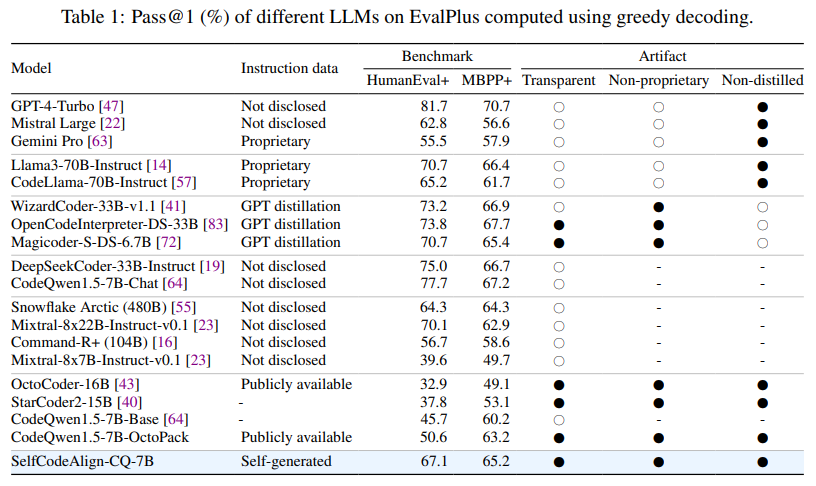
The effectiveness of SelfCodeAlign was rigorously examined with the CodeQwen1.5-7B mannequin. Benchmarked in opposition to fashions like CodeLlama-70B, SelfCodeAlign surpassed many state-of-the-art options, reaching a HumanEval+ move@1 rating of 67.1%, which is 16.5 factors greater than its baseline mannequin, CodeQwen1.5-7B-OctoPack. The mannequin carried out persistently nicely throughout varied duties, together with operate and sophistication era, information science programming, and code modifying, demonstrating that SelfCodeAlign enhances efficiency throughout totally different mannequin sizes, from 3B to 33B parameters. At school-level era duties, SelfCodeAlign achieved a move@1 fee of 27% on the class stage and 52.6% on the methodology stage, outperforming many proprietary instruction-tuned fashions. These outcomes spotlight SelfCodeAlign’s potential to supply fashions that aren’t solely efficient but additionally smaller in dimension, additional growing accessibility.
Concerning effectivity, on the EvalPerf benchmark, which assesses code effectivity, the mannequin achieved a Differential Efficiency Rating (DPS) of 79.9%. This means that SelfCodeAlign-generated options matched or exceeded the effectivity of 79.9% of comparable options in varied efficiency-level checks. Additionally, SelfCodeAlign achieved a move@1 fee of 39% in code modifying duties, excelling in corrective, adaptive, and perfective coding modifications. This constant efficiency throughout various benchmarks emphasizes the effectiveness of SelfCodeAlign’s self-generated information strategy.
The primary takeaways from SelfCodeAlign’s success are transformative for the sector of code LLMs:
- Transparency and Accessibility: SelfCodeAlign is a completely open-source and clear strategy that requires no proprietary mannequin information, making it perfect for researchers centered on moral AI and reproducibility.
- Effectivity Features: With a DPS of 79.9% on effectivity benchmarks, SelfCodeAlign demonstrates that smaller, independently skilled fashions can obtain spectacular outcomes on par with a lot bigger proprietary fashions.
- Versatility Throughout Duties: The mannequin excels throughout varied coding duties, together with code synthesis, debugging, and information science functions, underscoring its utility for a number of domains in software program engineering.
- Price and Licensing Advantages: SelfCodeAlign’s capacity to function with out pricey human-annotated information or proprietary LLM distillation makes it extremely scalable and economically viable, addressing frequent limitations in conventional instruction-tuning strategies.
- Adaptability for Future Analysis: The mannequin’s pipeline can accommodate fields past coding, displaying promise for adaptation in several technical domains.

In conclusion, SelfCodeAlign supplies an revolutionary resolution to the challenges of coaching instruction-following fashions in code era. By eliminating the necessity for human annotations and reliance on proprietary fashions, SelfCodeAlign gives a scalable, clear, and high-performance various that might redefine how code LLMs are developed. The analysis demonstrates that autonomous self-alignment, with out distillation, can yield outcomes corresponding to massive, pricey fashions, marking a big development in open-source LLMs for code era.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.


