


Giant language fashions (LLMs) are getting higher at scaling and dealing with lengthy contexts. As they’re getting used on a big scale, there was a rising demand for environment friendly help of high-throughput inference. Nonetheless, effectively serving these long-context LLMs presents challenges associated to the key-value (KV) cache, which shops earlier key-value activations to keep away from re-computation. However because the textual content they deal with will get longer, the growing reminiscence footprint and the necessity to entry it for every token technology each end in low throughput when serving long-context LLMs.
The present strategies face three main points: accuracy degradation, insufficient reminiscence discount, and vital decoding latency overhead. Methods to delete older cache knowledge assist save reminiscence however can result in accuracy loss, particularly in duties like conversations. Strategies like Dynamic sparse consideration, maintain all cached knowledge on the GPU, rushing up calculations however not decreasing reminiscence wants sufficient for dealing with very lengthy texts. A primary resolution for that is to maneuver some knowledge from the GPU to the CPU to save lots of reminiscence, however this methodology reduces pace as a result of retrieving knowledge from the CPU takes time.
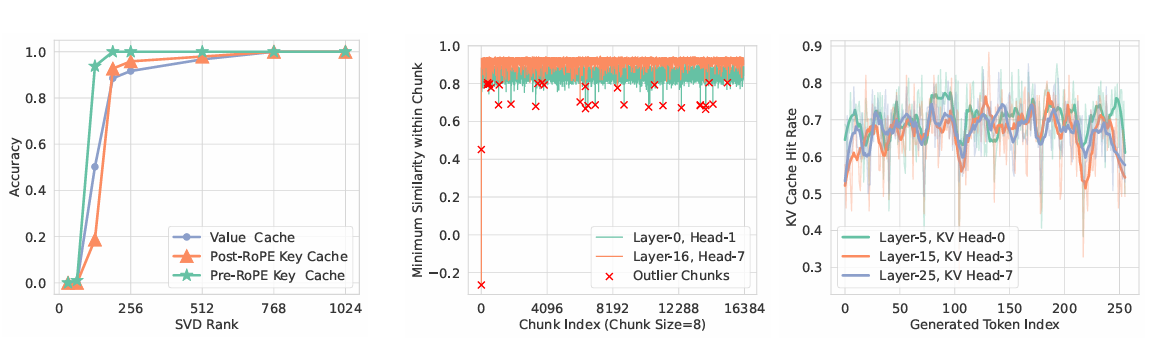
Pre-RoPE keys are a sure sort of information that have a less complicated construction, making them simple to compress and retailer effectively. They’re distinctive inside a sequence however constant throughout components of that sequence, permitting them to compress extremely inside every sequence. This helps to maintain solely the vital knowledge on the GPU, whereas different knowledge will be saved on the CPU with out majorly affecting the pace and accuracy of the system. This strategy achieves sooner and extra environment friendly dealing with of lengthy texts with LLMs by enhancing reminiscence use and punctiliously storing vital knowledge.
A bunch of researchers from Carnegie Mellon College and ByteDance proposed a way known as ShadowKV, a high-throughput long-context LLM inference system that shops the low-rank key cache and offloads the worth cache to scale back the reminiscence footprint for bigger batch sizes and longer sequences. To scale back decoding delays, ShadowKV makes use of a exact methodology for choosing key-value (KV) pairs, creating solely the mandatory sparse KV pairs as wanted.
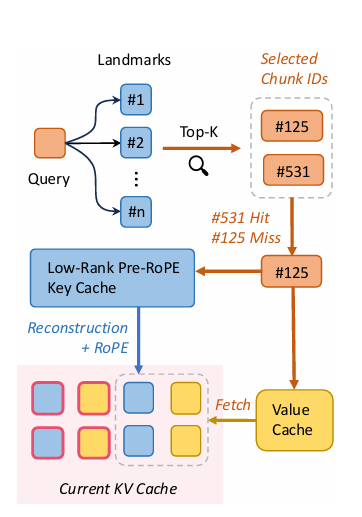
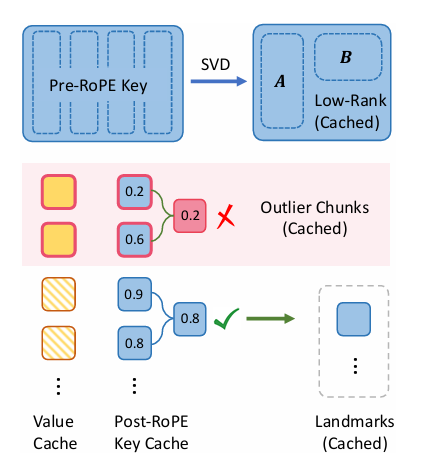
The algorithm of ShadowKV is split into two primary phases: pre-filling and decoding. Within the pre-filing section, it compresses key caches with low-rank representations and offloads worth caches to CPU reminiscence, performing SVD on the pre-RoPE key cache and segmenting post-RoPE key caches into chunks with calculated landmarks. Outliers, recognized by cosine similarity inside these chunks, are saved in a static cache on the GPU, whereas compact landmarks are saved in CPU reminiscence. Throughout decoding, ShadowKV computes an approximate consideration rating based mostly on the top-k scoring chunks, reconstructs key caches from low-rank projections, and makes use of cache-aware CUDA kernels to scale back computation by 60%, creating solely important KV pairs. The “equal bandwidth” idea is utilized by ShadowKV, loading knowledge effectively to succeed in a bandwidth of 7.2 TB/s on an A100 GPU, which is 3.6 instances its reminiscence bandwidth. By evaluating ShadowKV on a broad vary of benchmarks, together with RULER, LongBench, and Needle In A Haystack, together with fashions like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, it’s demonstrated that ShadowKV can help as much as 6 instances bigger batch sizes, even surpassing the efficiency achievable with infinite batch measurement underneath the idea of infinite GPU reminiscence.
In conclusion, the proposed methodology by researchers named ShadowKV is a high-throughput inference system for long-context LLM inference. ShadowKV optimizes GPU reminiscence utilization by way of the low-rank key cache and offloaded worth cache, permitting bigger batch sizes. It lowers decoding delays with exact sparse consideration, growing processing pace whereas protecting accuracy intact. This methodology could also be a base for future analysis within the rising subject of Giant Language fashions!
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Group Members
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and remedy challenges.

