


Giant Language Fashions (LLMs) have revolutionized pure language processing however face important challenges in dealing with very lengthy sequences. The first subject stems from the Transformer structure’s quadratic complexity relative to sequence size and its substantial key-value (KV) cache necessities. These limitations severely influence the fashions’ effectivity, notably throughout inference, making them prohibitively gradual for producing prolonged sequences. This bottleneck hinders the event of functions that require reasoning over a number of lengthy paperwork, processing massive codebases, or modeling advanced environments in agent-based techniques. Researchers are due to this fact in search of extra environment friendly architectures that may preserve or surpass the efficiency of Transformers whereas considerably decreasing computational calls for.
Researchers have explored numerous approaches to qualify the effectivity challenges in LLMs. Consideration-free fashions, comparable to S4, GSS, and BiGS, have demonstrated improved computational and reminiscence effectivity. The Mamba mannequin, incorporating input-specific context choice, has proven superior efficiency in comparison with Transformers throughout totally different scales. Different sub-quadratic and hybrid architectures have additionally been proposed. Distillation strategies have been employed to switch information from Transformers to linear RNN-style fashions, as seen in Laughing Hyena and progressive information approaches. Speculative decoding has emerged as a promising technique to speed up inference, using smaller draft fashions to generate candidate tokens for verification by bigger goal fashions. These approaches embody rejection sampling schemes, tree-structured candidate group, and each skilled and training-free draft fashions.
Researchers from Cornell College, the College of Geneva, Collectively AI, and Princeton College suggest a novel strategy to mitigate the effectivity challenges of LLM fashions by distilling a pre-trained Transformer right into a linear RNN. This technique goals to protect era high quality whereas considerably bettering inference pace. The proposed approach entails mapping Transformer weights to a modified Mamba structure, which could be straight initialized from the eye block of a pre-trained mannequin. A multistage distillation pipeline, combining progressive distillation, supervised fine-tuning, and directed choice optimization, is launched to reinforce perplexity and downstream efficiency. The researchers additionally develop a hardware-aware speculative sampling algorithm and a quick kernel for speculative decoding on Mamba and hybrid architectures, reaching a throughput of over 300 tokens/second for a 7B-parameter mannequin. This strategy successfully applies speculative decoding to the hybrid structure, addressing the necessity for environment friendly inference in advanced LLM functions.
The proposed technique transforms Transformer fashions into Mamba fashions utilizing linear RNNs, addressing the constraints of consideration mechanisms. By increasing the linear hidden state capability via Mamba’s continuous-time state-space mannequin, the strategy dynamically constructs a discrete-time linear RNN. This revolutionary structure initializes from consideration parameters and employs hardware-aware factorization for environment friendly implementation. The strategy then applies information distillation to compress the big Transformer mannequin right into a smaller Mamba-based community, specializing in fine-tuning and alignment steps. This course of combines sequence-level information distillation and word-level KL-Divergence for supervised fine-tuning whereas adapting Direct Choice Optimization for choice alignment.
The distillation course of allows the coed mannequin to be taught from the instructor’s output distribution and era, optimizing for each efficiency and alignment with desired preferences. All through this course of, MLP layers from the unique mannequin stay frozen, whereas Mamba layers are skilled to seize the distilled information. This strategy permits for the alternative of consideration blocks with linear RNN blocks whereas sustaining mannequin efficiency. By increasing the hidden state dimension and utilizing hardware-aware factorization, the tactic achieves environment friendly implementation, enabling bigger hidden sizes with out important computational prices. The ensuing Mamba-based mannequin combines the advantages of Transformer architectures with the effectivity of linear RNNs, probably advancing the sphere of LLMs.
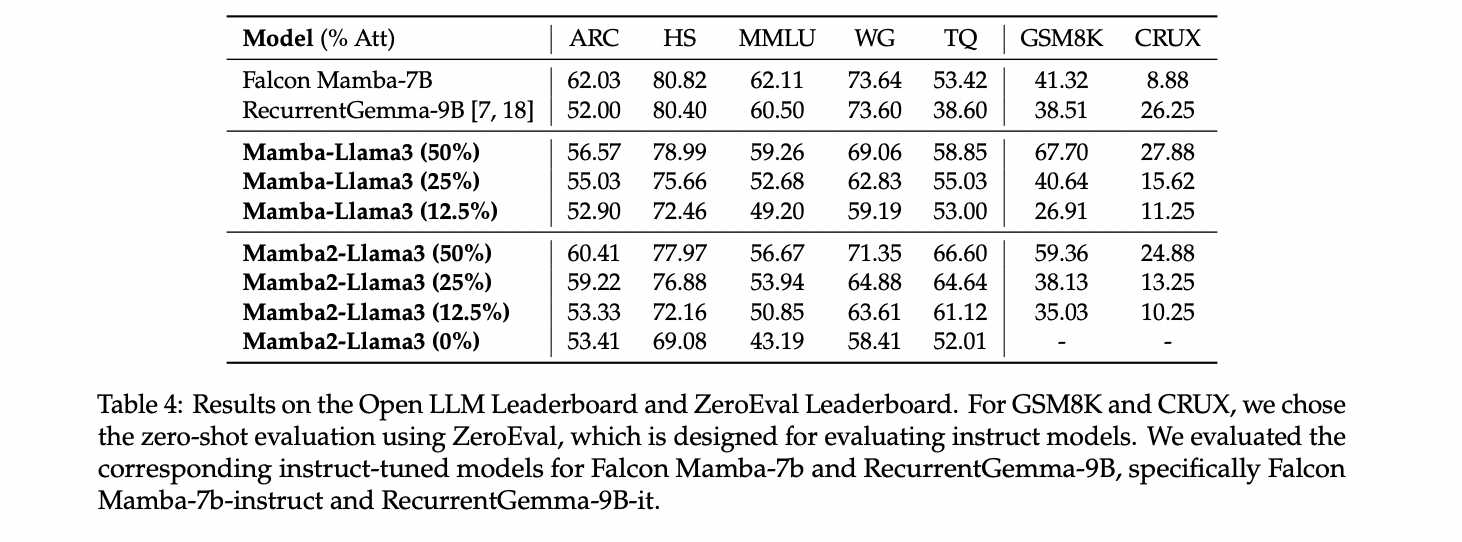
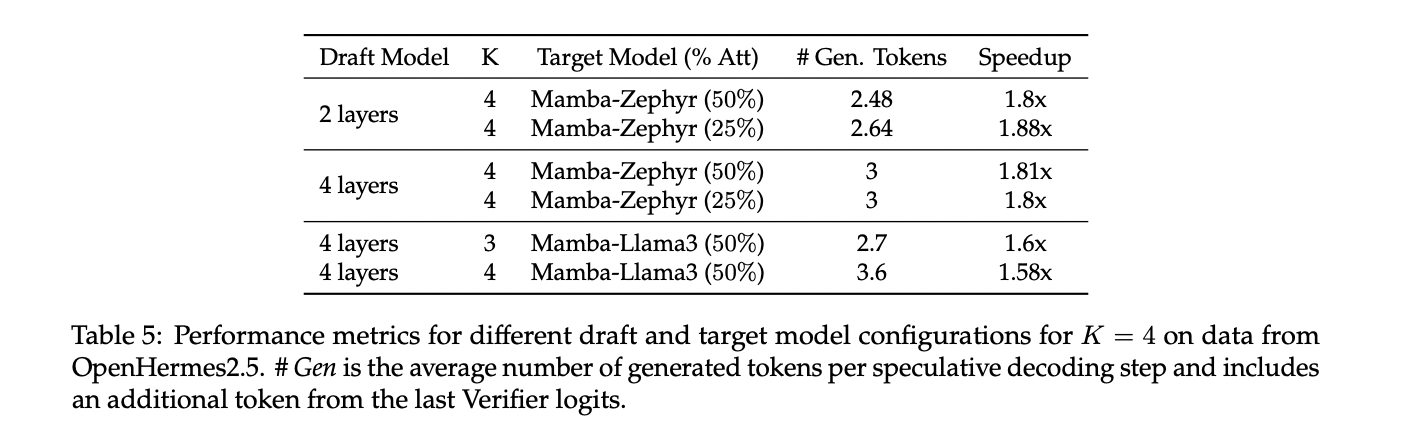
The distilled hybrid Mamba fashions show aggressive efficiency on numerous benchmarks. On chat benchmarks like AlpacaEval and MT-Bench, the 50% hybrid mannequin achieves comparable or barely higher scores than its instructor mannequin, outperforming some bigger transformers. In zero-shot and few-shot evaluations, the hybrid fashions surpass open-source linear RNN fashions skilled from scratch, with efficiency degrading as extra consideration layers are changed. The hybrid fashions additionally present promising outcomes on the OpenLLM Leaderboard and ZeroEval benchmark. Speculative decoding experiments with these hybrid fashions obtain speedups of as much as 1.88x on a single GPU. Total, the outcomes point out that the distilled hybrid Mamba fashions supply a great steadiness between effectivity and efficiency.

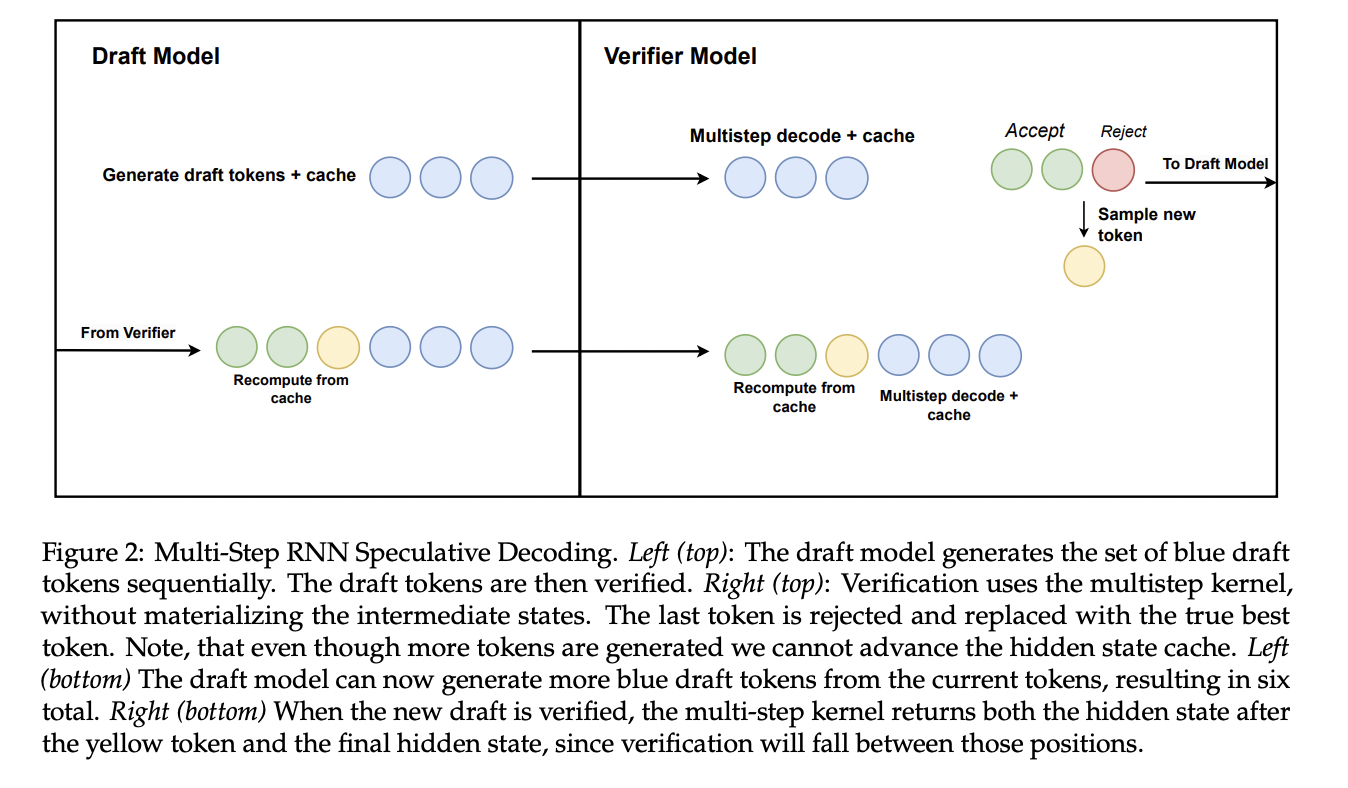
This research presents a novel technique for remodeling Transformer fashions into extra environment friendly Mamba-based fashions utilizing linear RNNs. Outcomes present that the distilled hybrid Mamba fashions obtain comparable or higher efficiency than their instructor fashions on numerous benchmarks, together with chat duties and basic language understanding. The strategy demonstrates explicit success in sustaining efficiency whereas decreasing computational prices, particularly when retaining 25-50% of consideration layers. Additionally, the researchers introduce an revolutionary speculative decoding algorithm for linear RNNs, additional enhancing inference pace. These findings counsel important potential for bettering the effectivity of LLMs whereas preserving their capabilities.
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


