


AI security frameworks have emerged as essential danger administration insurance policies for AI corporations creating frontier AI methods. These frameworks goal to handle catastrophic dangers related to AI, together with potential threats from chemical or organic weapons, cyberattacks, and lack of management. The first problem lies in figuring out an “acceptable” stage of danger, as there’s at the moment no common customary. Every AI developer should set up their threshold, creating a various panorama of security approaches. This lack of standardization poses vital challenges in making certain constant and complete danger administration throughout the AI business.
Current analysis on AI security frameworks is proscribed, given their latest emergence. 4 major areas of scholarship have been developed: present security frameworks, suggestions for security frameworks, critiques of present frameworks, and analysis standards. A number of main AI corporations, together with Anthropic, OpenAI, Google DeepMind, and Magic, have revealed their security frameworks. These frameworks, reminiscent of Anthropic’s Accountable Scaling Coverage and OpenAI’s Preparedness Framework, signify the primary concrete makes an attempt to implement complete danger administration methods for frontier AI methods.
Suggestions for security frameworks have come from varied sources, together with organizations like METR and authorities our bodies such because the UK Division for Science, Innovation and Expertise. These suggestions define key parts and practices that must be integrated into efficient security frameworks. Students have performed critiques of present frameworks, evaluating and evaluating them towards proposed pointers and security practices. Nonetheless, analysis standards for these frameworks stay underdeveloped, with just one key supply proposing particular standards for assessing their robustness in addressing superior AI dangers.
Centre for the Governance of AI Researchers have tried to place weight on the event of efficient analysis standards for AI security frameworks, which is essential for a number of causes. Firstly, it helps determine shortcomings in present frameworks, permitting corporations to make obligatory enhancements as AI methods advance and pose larger dangers. This course of is analogous to see evaluate in scientific analysis, selling steady refinement and enhancement of security requirements. Secondly, a sturdy analysis system can incentivize a “race to the highest” amongst AI corporations as they try to realize increased grades and be perceived as accountable business leaders.
Along with that, these analysis abilities could grow to be important for future regulatory necessities, making ready each corporations and regulators for potential compliance assessments below varied regulatory approaches. Lastly, public judgments on AI security frameworks can inform and educate most people, offering a much-needed exterior validation of corporations’ security claims. This transparency is especially essential in combating potential “security washing” and serving to the general public perceive the advanced panorama of AI security measures.
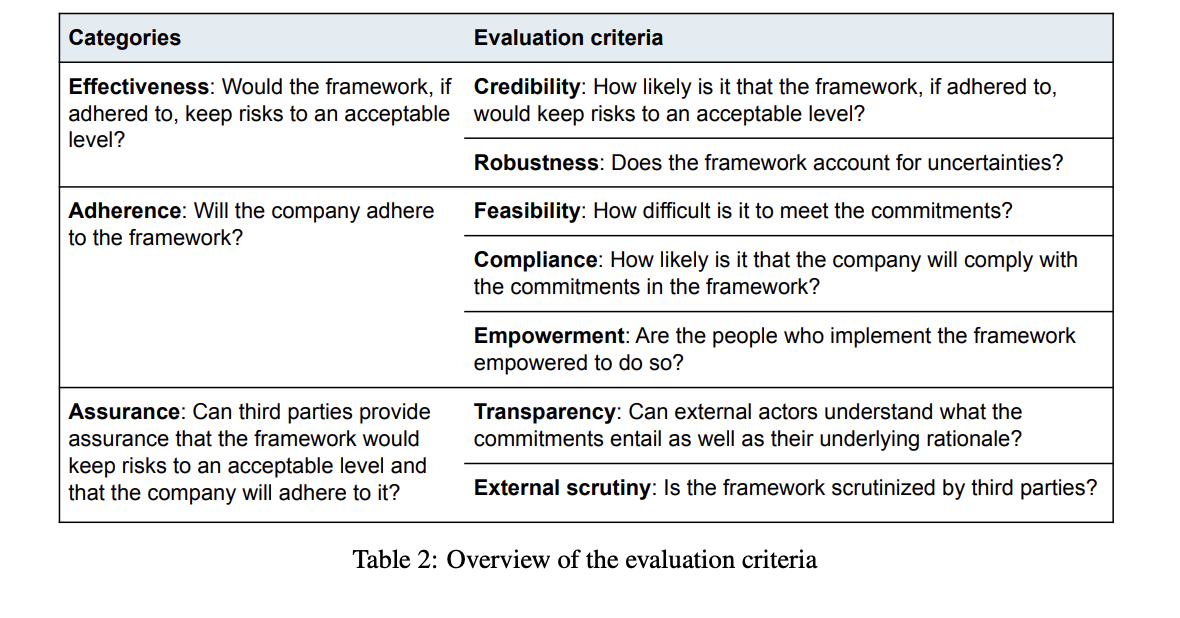
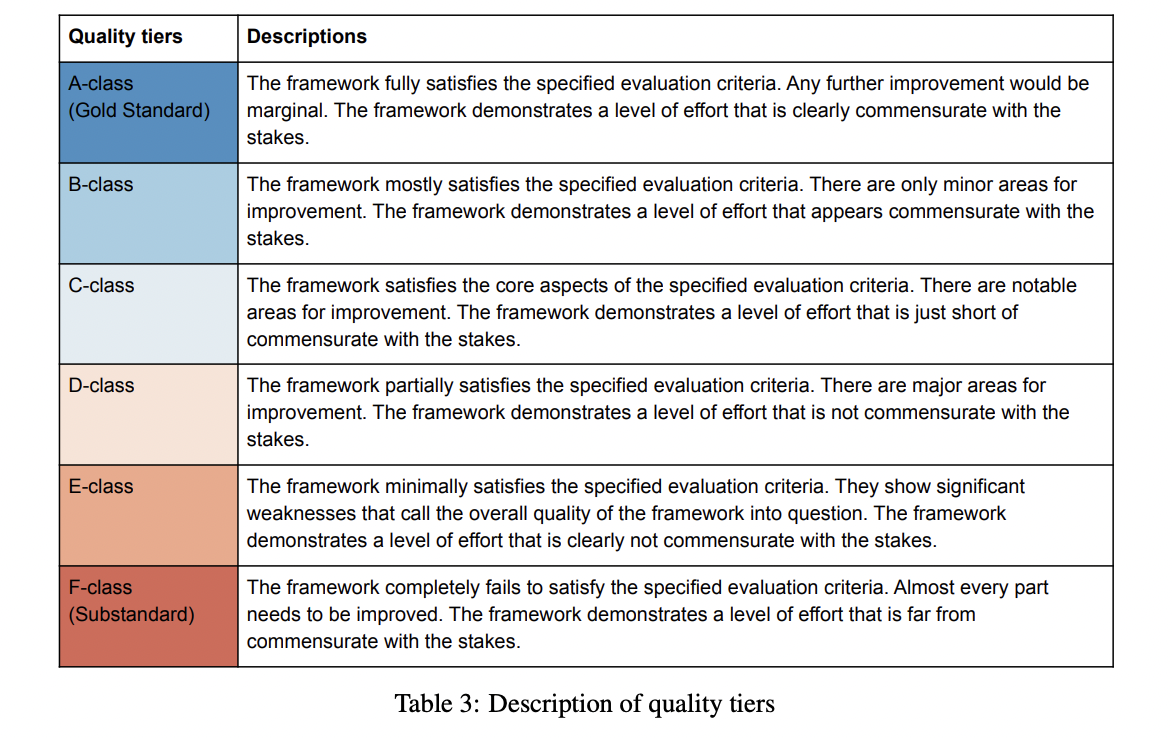
Researchers have proposed a sturdy methodology, introducing a complete grading rubric for evaluating AI security frameworks. This rubric is structured round three key classes: effectiveness, adherence, and assurance. These classes align with the outcomes outlined within the Frontier AI Security commitments. Inside every class, particular analysis standards and indicators are outlined to supply a concrete foundation for evaluation. The rubric employs a grading scale starting from A (gold customary) to F (substandard) for every criterion, permitting for a nuanced analysis of various features of AI security frameworks. This structured method permits a radical and systematic evaluation of the standard and robustness of security measures carried out by AI corporations.
The proposed methodology for making use of the grading rubric to AI security frameworks includes three main approaches: surveys, Delphi research, and audits. For surveys, the method consists of designing questions that consider every criterion on an A to F scale, distributing these to AI security and governance specialists, and analyzing the responses to find out common grades and key insights. This methodology gives a steadiness between useful resource effectivity and professional judgment.
Delphi research signify a extra complete method, involving a number of rounds of analysis and dialogue. Contributors initially grade the frameworks and supply rationales, then interact in workshops to debate aggregated responses. This iterative course of permits for consensus-building and in-depth exploration of advanced points. Whereas time-intensive, Delphi research make the most of collective experience to supply nuanced assessments of AI security frameworks.
Audits, although not detailed within the offered textual content, seemingly contain a extra formal, structured analysis course of. The strategy recommends grading every analysis criterion slightly than particular person indicators or general classes, hanging a steadiness between nuance and practicality in evaluation. This method permits a radical examination of AI security frameworks whereas sustaining a manageable analysis course of.
The proposed grading rubric for AI security frameworks is designed to supply a complete and nuanced analysis throughout three key classes: effectiveness, adherence, and assurance. The effectiveness standards, specializing in credibility and robustness, assess the framework’s potential to mitigate dangers if correctly carried out. Credibility is evaluated primarily based on causal pathways, empirical proof, and professional opinion, whereas robustness considers security margins, redundancies, stress testing, and revision processes.
The adherence standards study feasibility, compliance, and empowerment, making certain that the framework is life like and more likely to be adopted. This consists of assessing dedication problem, developer competence, useful resource allocation, possession, incentives, monitoring, and oversight. The reassurance standards, masking transparency and exterior scrutiny, consider how nicely third events can confirm the framework’s effectiveness and adherence.
Key advantages of this analysis methodology embody:
1. Complete evaluation: The rubric covers a number of features of security frameworks, offering a holistic analysis.
2. Flexibility: The A to F grading scale permits for nuanced assessments of every criterion.
3. Transparency: Clear indicators for every criterion make the analysis course of extra clear and replicable.
4. Enchancment steering: The detailed standards and indicators present particular areas for framework enchancment.
5. Stakeholder confidence: Rigorous analysis enhances belief in AI corporations’ security measures.
This methodology permits a radical, systematic evaluation of AI security frameworks, probably driving enhancements in security requirements throughout the business.

The proposed grading rubric for AI security frameworks, whereas complete, has six main limitations:
1. Lack of actionable suggestions: The rubric successfully identifies areas for enchancment however doesn’t present particular steering on learn how to improve security frameworks.
2. Subjectivity in measurement: Many standards, reminiscent of robustness and feasibility, are summary ideas which might be troublesome to measure objectively, resulting in potential inconsistencies in grading.
3. Experience requirement: Evaluators want specialised AI security data to evaluate sure standards precisely, limiting the pool of certified graders.
4. Potential incompleteness: The analysis standards will not be exhaustive, presumably overlooking important components in assessing security frameworks as a result of novelty of the sector.
5. Problem in tier differentiation: The six-tier grading system could result in challenges in distinguishing between high quality ranges, significantly within the center tiers, probably decreasing the precision of assessments.
6. Equal weighting of standards: The rubric doesn’t assign totally different weights to standards primarily based on their significance, which might result in deceptive general assessments if readers intuitively combination scores.
These limitations spotlight the challenges in making a standardized analysis methodology for the advanced and evolving area of AI security frameworks. They underscore the necessity for ongoing refinement of evaluation instruments and cautious interpretation of grading outcomes.
This paper introduces a sturdy grading rubric for evaluating AI security frameworks, representing a big contribution to the sector of AI governance and security. The proposed rubric includes seven complete grading standards, every supported by 21 particular indicators to supply concrete evaluation pointers. This construction permits for a nuanced analysis of AI security frameworks on a scale from A (gold customary) to F (substandard).
The researchers emphasize the sensible applicability of their work, encouraging its adoption by a variety of stakeholders together with governments, researchers, and civil society organizations. By offering this standardized analysis instrument, the authors goal to facilitate extra constant and thorough assessments of present AI security frameworks. This method can probably drive enhancements in security requirements throughout the AI business and foster larger accountability amongst AI corporations.
The rubric’s design, balancing detailed standards with flexibility in scoring, positions it as a invaluable useful resource for ongoing efforts to reinforce AI security measures. By selling the widespread use of this analysis methodology, the researchers goal to contribute to the event of extra sturdy, efficient, and clear AI security practices within the quickly evolving area of synthetic intelligence.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


