


Reinforcement Studying from Human Suggestions (RLHF) has emerged as an important approach in aligning giant language fashions (LLMs) with human values and expectations. It performs a crucial function in guaranteeing that AI programs behave in comprehensible and reliable methods. RLHF enhances the capabilities of LLMs by coaching them based mostly on suggestions that permits fashions to supply extra useful, innocent, and trustworthy outputs. This strategy is extensively utilized in creating AI instruments starting from conversational brokers to superior decision-support programs, aiming to combine human preferences instantly into mannequin conduct.
Regardless of its significance, RLHF faces a number of elementary challenges. One of many major points is the instability and inherent imperfections within the reward fashions that information the educational course of. These reward fashions usually misrepresent human preferences as a consequence of biases current within the coaching knowledge. Such biases can result in problematic points like reward hacking, the place fashions exploit loopholes within the reward operate to realize greater rewards with out truly bettering process efficiency. Moreover, reward fashions usually endure from overfitting and underfitting, which suggests they fail to generalize nicely to unseen knowledge or seize important patterns. Consequently, this misalignment between the mannequin’s conduct and true human intent hinders the efficiency and stability of RLHF.
Regardless of quite a few makes an attempt to handle these points, the urgency for a strong RLHF framework stays. Standard strategies, together with Proximal Coverage Optimization (PPO) and Most Chance Estimation (MLE) for coaching reward fashions, have proven promise however haven’t absolutely resolved the inherent uncertainties and biases in reward fashions. Latest approaches, similar to contrastive rewards or ensembles of reward fashions, have tried to mitigate these points. Nonetheless, they nonetheless wrestle to keep up stability and alignment in advanced real-world situations. The necessity for a framework that may robustly handle these challenges and guarantee dependable studying outcomes is extra urgent than ever.
Researchers from the Tsinghua College and Baichuan AI have a brand new reward-robust RLHF framework. This modern framework makes use of Bayesian Reward Mannequin Ensembles (BRME) to seize and handle the uncertainty in reward indicators successfully. Utilizing BRME permits the framework to include a number of views into the reward operate, thus lowering the chance of misalignment and instability. The proposed framework is designed to steadiness efficiency and robustness, making it extra immune to errors and biases. By integrating BRME, the system can choose essentially the most dependable reward indicators, guaranteeing extra steady studying regardless of imperfect or biased knowledge.
The methodology of this proposed framework is centered on a multi-head reward mannequin. Every head within the mannequin outputs the imply and normal deviation of a Gaussian distribution, which represents the reward. This multi-head strategy captures the imply reward values and quantifies the boldness in every reward sign. Throughout coaching, the top with the bottom normal deviation is chosen because the nominal reward operate, successfully filtering out unreliable reward indicators. The framework leverages Imply Sq. Error (MSE) loss for coaching, guaranteeing that the output’s normal deviation precisely displays the mannequin’s confidence. In contrast to conventional RLHF strategies, this strategy prevents the mannequin from relying too closely on any single reward sign, thus mitigating the chance of reward hacking or misalignment.
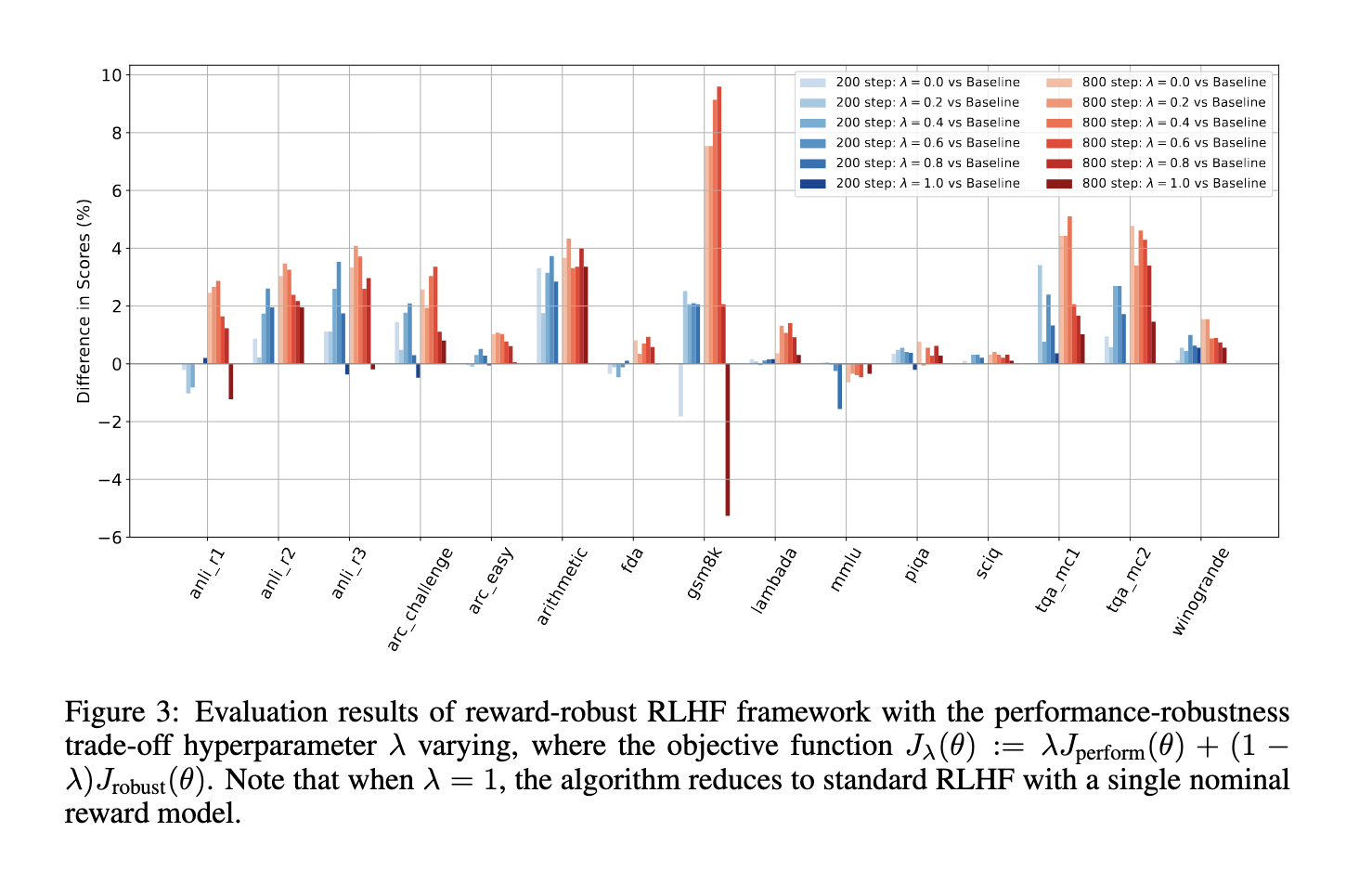
The proposed reward-robust RLHF framework has demonstrated spectacular efficiency, constantly outperforming conventional RLHF strategies throughout varied benchmarks. The analysis staff comprehensively evaluated their framework on 16 extensively used datasets, together with ARC, LAMBADA, and MMLU, masking areas like common data, reasoning, and numerical computation. The outcomes had been compelling, displaying that the proposed technique achieved a median accuracy enhance of about 4% in comparison with typical RLHF. Furthermore, when the reward uncertainty was built-in into the coaching course of, the brand new technique confirmed a efficiency acquire of two.42% and a couple of.03% for particular duties, underscoring its potential to deal with biased and unsure reward indicators successfully. As an example, within the LAMBADA dataset, the proposed technique considerably improved efficiency stability, lowering the fluctuation seen in conventional strategies by 3%. This not solely enhances efficiency but additionally ensures long-term stability throughout prolonged coaching durations, a key benefit of the framework.
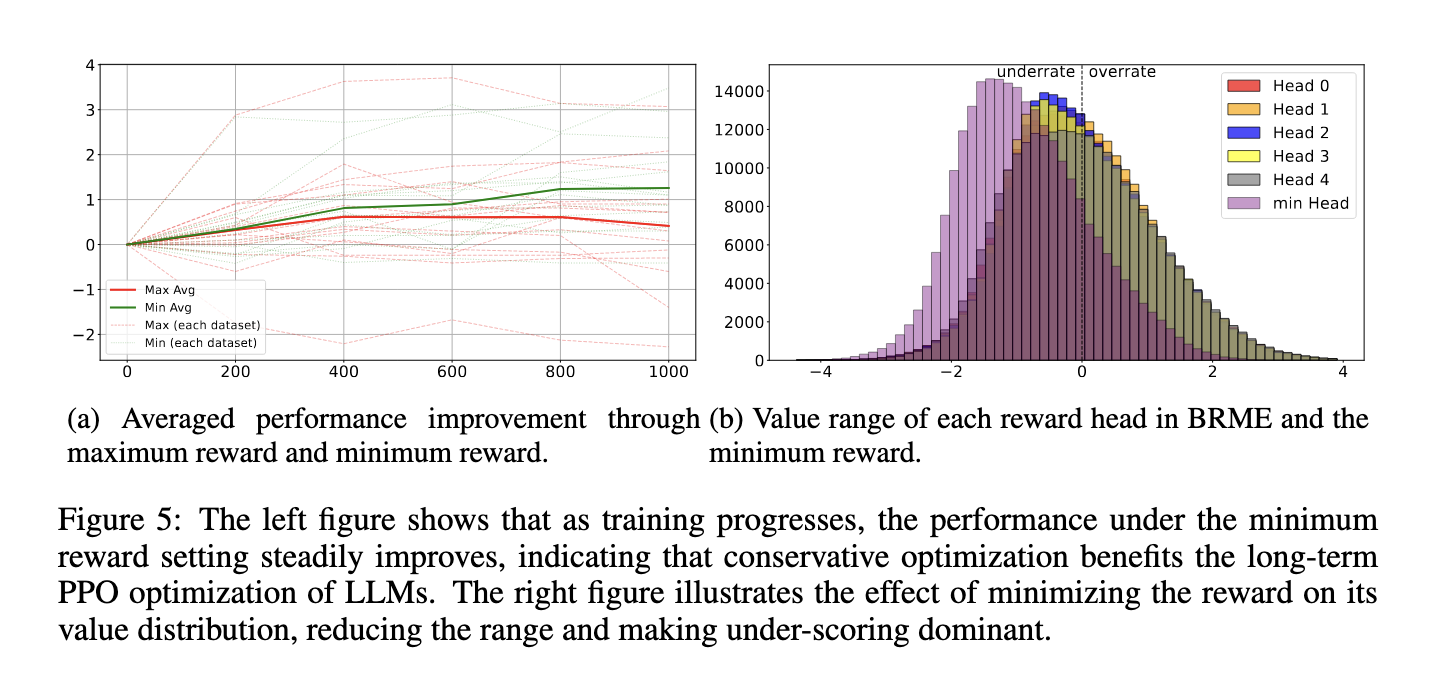
The reward-robust RLHF framework’s potential to withstand efficiency degradation, usually brought on by unreliable reward indicators, is a big achievement. In situations the place conventional RLHF strategies wrestle, the proposed technique maintains and even improves mannequin efficiency, demonstrating its potential for real-world functions the place reward indicators are not often excellent. This stability is essential for deploying AI programs that may adapt to altering environments and preserve excessive efficiency underneath varied circumstances, underscoring the sensible worth of the framework.
Total, the analysis addresses elementary challenges within the RLHF course of by introducing a strong framework stabilizing the educational course of in giant language fashions. By balancing nominal efficiency with robustness, this novel technique provides a dependable answer to persistent points like reward hacking and misalignment. The proposed framework, developed by Tsinghua College and Baichuan AI, holds promise for advancing the sphere of AI alignment and paving the way in which for safer and simpler AI programs.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit.
We invite startups, corporations, and analysis establishments engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report will likely be launched in late October/early November 2024. Click on right here to arrange a name!
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


