


Language fashions (LMs) are advancing as instruments for fixing issues and as creators of artificial information, enjoying a vital function in enhancing AI capabilities. Artificial information enhances or replaces conventional guide annotation, providing scalable options for coaching fashions in domains corresponding to arithmetic, coding, and instruction-following. The power of LMs to generate high-quality datasets ensures higher activity generalization, positioning them as versatile belongings in fashionable AI analysis and purposes.
A major problem is assessing which LMs carry out higher as artificial information turbines. With various capabilities throughout proprietary and open-source fashions, researchers face issue deciding on applicable LMs for particular duties. This complexity stems from the necessity for a unified benchmark to guage these fashions systematically. Moreover, whereas some fashions excel in problem-solving, this potential solely generally correlates with their information era efficiency, making direct comparisons much more tough.
A number of approaches to artificial information era have been explored, utilizing LMs like GPT-3, Claude-3.5, and Llama-based architectures. Strategies corresponding to instruction-following, response era, and high quality enhancement have been examined, with various success throughout duties. Nonetheless, the absence of managed experimental setups has led to inconsistent findings, stopping researchers from deriving significant conclusions concerning the comparative strengths of those fashions.
Researchers from establishments like Carnegie Mellon College, KAIST AI, the College of Washington, NEC Laboratories Europe, and Ss. Cyril and Methodius College of Skopje developed the AGORABENCH. This benchmark permits systematic analysis of LMs as information turbines underneath managed circumstances. AGORABENCH facilitates direct comparisons throughout duties, together with occasion era, response era, and high quality enhancement by standardizing variables like seed datasets, meta-prompts, and analysis metrics. The mission additionally collaborates with firms corresponding to NEC Laboratories Europe, leveraging numerous experience to make sure robustness.
AGORABENCH makes use of a set methodology to guage information era capabilities. It employs particular seed datasets for every area, corresponding to GSM8K for arithmetic and MBPP for coding, making certain consistency throughout experiments. Meta-prompts are designed to information fashions in producing artificial information, whereas variables like instruction issue and response high quality are assessed utilizing intrinsic metrics. A key metric, Efficiency Hole Recovered (PGR), quantifies the advance of pupil fashions skilled on artificial information in comparison with their baseline efficiency. Principal part evaluation (PCA) additional identifies elements influencing information era success, corresponding to instruction variety and response perplexity.
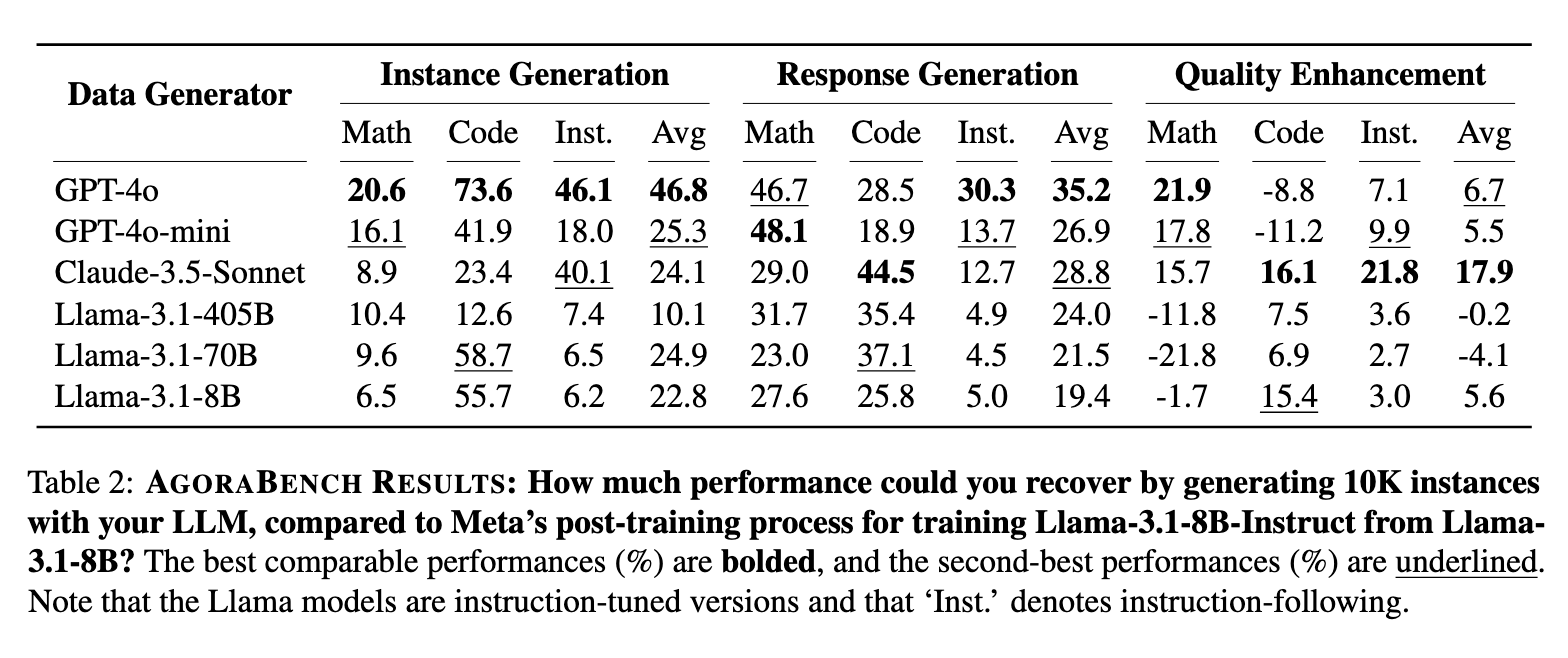
The outcomes from AGORABENCH revealed noteworthy traits. GPT-4o emerged because the top-performing mannequin in occasion era, attaining a median PGR of 46.8% throughout duties and excelling in arithmetic with a PGR of 20.6%. In distinction, Claude-3.5-Sonnet demonstrated superior efficiency in high quality enhancement, with a PGR of 17.9% total and 21.8% in coding duties. Curiously, weaker fashions often outperformed stronger ones in particular situations. As an illustration, Llama-3.1-8B achieved a PGR of 55.7% in coding occasion era, surpassing extra superior fashions like GPT-4o. Value evaluation revealed that producing 50,000 situations with a inexpensive mannequin like GPT-4o-mini yielded comparable or higher outcomes than 10,000 situations generated by GPT-4o, highlighting the significance of budget-conscious methods.
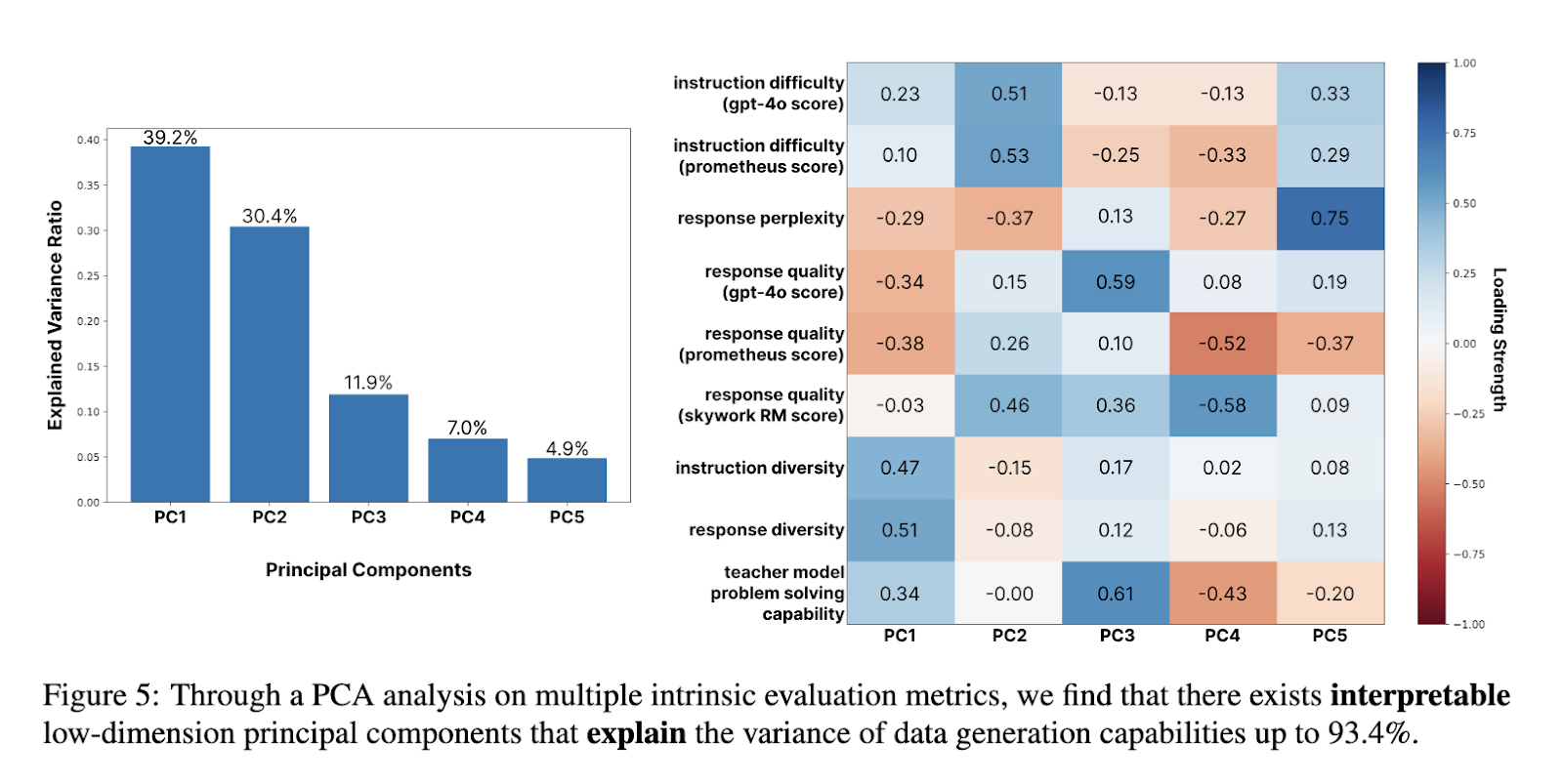
The examine underscores the advanced relationship between problem-solving and information era skills. Whereas stronger problem-solving fashions don’t at all times produce higher artificial information, intrinsic properties like response high quality and instruction issue considerably affect outcomes. For instance, fashions with excessive response high quality scores aligned higher with activity necessities, bettering pupil mannequin efficiency. The PCA evaluation of AGORABENCH information defined 93.4% of the PGR outcomes variance, emphasizing intrinsic metrics’ function in predicting information era success.
By introducing AGORABENCH, the researchers present a strong framework for evaluating LMs’ information era capabilities. The findings information researchers and practitioners in deciding on appropriate fashions for artificial information era whereas optimizing prices and efficiency. This benchmark additionally lays the inspiration for growing specialised LMs tailor-made for information era duties, increasing the scope of their purposes in AI analysis and business.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
🚨 Trending: LG AI Analysis Releases EXAONE 3.5: Three Open-Supply Bilingual Frontier AI-level Fashions Delivering Unmatched Instruction Following and Lengthy Context Understanding for World Management in Generative AI Excellence….
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


