


Data distillation (KD) is a machine studying approach centered on transferring data from a big, complicated mannequin (instructor) to a smaller, extra environment friendly one (pupil). This method is used extensively to cut back massive language fashions’ computational load and useful resource necessities whereas retaining as a lot of their efficiency as doable. Utilizing this technique, researchers can develop smaller sensible fashions for real-time purposes whereas preserving important efficiency attributes.
In KD, a central problem is bridging the hole between the information distributions used for coaching and people encountered throughout inference. Standard approaches like supervised KD depend on a static set of information, which might result in a distribution mismatch, inflicting the mannequin to underperform when confronted with real-world inputs. On-policy KD, one other approach, trains the coed on generated outputs. Nonetheless, this could introduce low-quality samples that won’t align with the instructor mannequin’s excessive requirements, in the end leading to flawed suggestions. This limitation hampers the effectiveness of KD because it fails to supply constant steering to the coed mannequin throughout totally different studying phases.
To sort out these challenges, researchers have developed a number of KD strategies. Supervised KD, for instance, makes use of a predetermined dataset to coach the coed, however this fastened method doesn’t accommodate modifications within the pupil’s output distribution at inference time. On-policy KD makes an attempt to adapt to the coed’s evolving outputs by incorporating its self-generated samples throughout coaching, aligning the coaching distribution extra carefully with inference. Nonetheless, on-policy KD wants assist with low-quality information, because the early coaching phases usually contain out-of-distribution samples that fail to characterize the instructor’s very best predictions. Because of this, each strategies need assistance persistently enhancing the coed mannequin’s efficiency throughout varied duties and situations.
Researchers from UC Santa Barbara, Google Cloud AI Analysis, Google DeepMind, and CMU have launched Speculative Data Distillation (SKD), an revolutionary method that employs a dynamic, interleaved sampling approach. SKD blends components of each supervised and on-policy KD. The coed mannequin proposes tokens, whereas the instructor mannequin selectively replaces poorly ranked tokens primarily based on their distribution. This cooperative course of ensures the coaching information stays high-quality and related to the coed’s inference-time distribution. Utilizing SKD, the researchers facilitate adaptive data switch that helps the coed mannequin constantly align with the instructor’s requirements whereas permitting flexibility within the pupil’s outputs.
In larger element, SKD’s method incorporates a token interleaving mechanism the place the coed and instructor fashions interactively suggest and refine tokens throughout coaching. At the start of coaching, the instructor mannequin considerably replaces lots of the pupil’s preliminary low-quality proposals, resembling supervised KD. Nonetheless, as the coed mannequin improves, the coaching steadily shifts in the direction of on-policy KD, the place extra pupil tokens are accepted with out modification. SKD’s design additionally features a filtering criterion primarily based on top-Okay sampling, the place solely pupil tokens throughout the instructor’s highest likelihood predictions are accepted. This steadiness permits SKD to keep away from the pitfalls of conventional supervised and on-policy KD, leading to a extra adaptive and environment friendly data switch that doesn’t rely closely on any fastened distribution.

The researchers validated SKD’s effectiveness by testing it throughout varied pure language processing (NLP) duties, demonstrating substantial enhancements in accuracy and adaptableness over earlier strategies. As an example, in a low-resource translation job, SKD achieved a 41.8% enchancment over conventional KD approaches, considerably enhancing the standard of Assamese-to-English translations. In summarization duties, SKD outperformed different strategies with a 230% enhance, and in arithmetic reasoning, SKD demonstrated a 160% enchancment. These outcomes underscore SKD’s robustness throughout duties with totally different information necessities, mannequin varieties, and initializations, reinforcing its viability as a flexible resolution for real-time, resource-constrained AI purposes. Moreover, testing with an instruction-following dataset yielded positive factors of 198% and 360% in specialised math duties, highlighting SKD’s distinctive adaptability throughout task-specific and task-agnostic situations.
Along with superior efficiency metrics, SKD displays resilience throughout totally different mannequin initializations and information sizes, proving efficient even in low-data environments the place solely 100 samples can be found. Conventional KD approaches usually fail in such settings because of overfitting, however SKD’s end-to-end method successfully bypasses this subject by dynamically adjusting the steering supplied by the instructor. Additional, by producing high-quality coaching information that aligns carefully with the coed’s inference-time wants, SKD achieves a seamless steadiness between supervised and on-policy KD, instilling confidence in its adaptability.
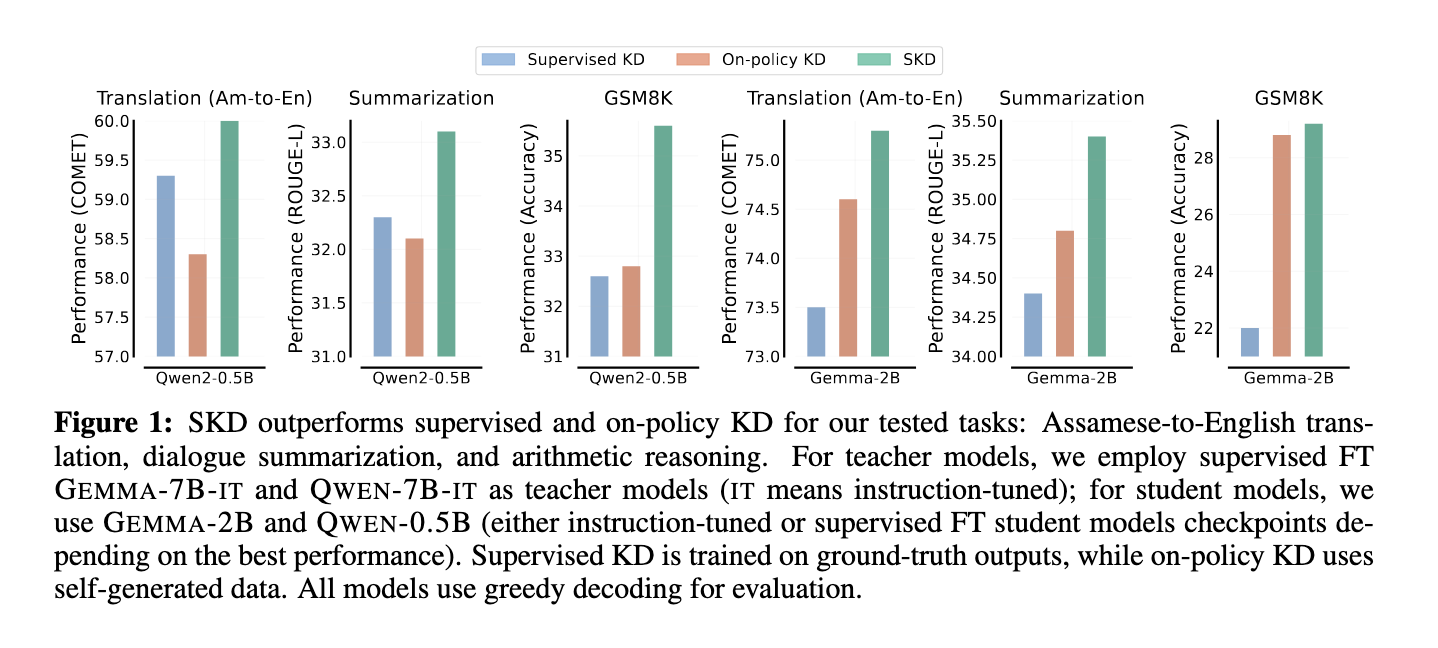
In abstract, Speculative Data Distillation presents a considerable advance in KD by addressing distribution mismatches and poor-quality pupil information that beforehand restricted KD effectiveness. By permitting a extra dynamic teacher-student interplay and adapting to the evolving high quality of pupil proposals, SKD gives a extra dependable and environment friendly technique of distilling data. Its potential to outperform conventional strategies persistently throughout varied domains highlights its potential to drive vital enhancements within the effectivity and scalability of AI purposes, notably in resource-constrained settings.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Neighborhood Members
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


