


Massive language fashions (LLMs) have garnered vital consideration for his or her capacity to know and generate human-like textual content. These fashions possess the distinctive functionality to encode factual data successfully, because of the huge quantity of knowledge they’re skilled on. This capacity is essential in varied functions, starting from pure language processing (NLP) duties to extra superior types of synthetic intelligence. Nevertheless, understanding how these fashions purchase and retain factual data throughout pretraining is a posh problem. This analysis investigates the intricate course of via which LLMs internalize data and explores how these fashions will be optimized to keep up and generalize the data they purchase.
One of many main points researchers face in coaching LLMs is the lack of factual data over time. When massive datasets are utilized in pretraining, LLMs battle to retain the main points of particular information, particularly when new data is launched in subsequent phases of coaching. Moreover, LLMs typically battle to recollect uncommon or long-tail data, considerably affecting their capacity to generalize throughout numerous matters. This lack of retention impairs the accuracy of fashions when utilized to advanced or occasionally encountered eventualities, presenting a substantial barrier to enhancing the efficiency of LLMs.
A number of strategies have been launched to deal with these challenges, specializing in enhancing the acquisition and retention of factual data in LLMs. These strategies embrace scaling up mannequin sizes and pretraining datasets, utilizing superior optimization strategies, and modifying batch sizes to raised deal with information throughout coaching. Deduplication of datasets has additionally been proposed to scale back redundancy within the coaching information, resulting in extra environment friendly studying. Regardless of these efforts, the basic issues of speedy forgetting and the mannequin’s problem in generalizing much less frequent information persist, and present options have solely made incremental enhancements.
Researchers from KAIST, UCL, and KT have launched a novel strategy to learning the acquisition and retention of factual data in LLMs. They designed an experiment that systematically injected new factual data into the mannequin throughout pretraining. By analyzing the mannequin’s capacity to memorize and generalize this information underneath varied circumstances, the researchers aimed to uncover the dynamics that govern how LLMs study and overlook. Their strategy concerned monitoring the mannequin’s efficiency throughout completely different checkpoints and observing the impact of things reminiscent of batch dimension, information duplication, and paraphrasing on data retention. This experiment supplied precious insights into optimizing coaching methods to enhance long-term reminiscence in LLMs.
The researchers’ methodology was thorough, involving detailed analysis at a number of phases of pretraining. They performed the experiments utilizing fictional data that the mannequin had not encountered earlier than to make sure the accuracy of the evaluation. Numerous circumstances have been examined, together with injecting the identical factual data repeatedly, paraphrasing it, or presenting it solely as soon as. To measure the effectiveness of information retention, the group evaluated the mannequin’s efficiency by inspecting modifications within the likelihood of recalling particular information over time. They found that bigger batch sizes helped the mannequin preserve factual data extra successfully, whereas duplicated information led to sooner forgetting. By utilizing quite a lot of take a look at circumstances, the analysis group might decide the best methods for coaching LLMs to retain and generalize data.
The efficiency of the proposed methodology revealed a number of key findings. First, the analysis confirmed that bigger fashions, reminiscent of these with 7 billion parameters, exhibited higher factual data retention than smaller fashions with just one billion parameters. Apparently, the quantity of coaching information used didn’t considerably influence retention, contradicting the assumption that extra information results in higher mannequin efficiency. As an alternative, the researchers discovered that fashions skilled with a deduplicated dataset have been extra sturdy, with slower charges of forgetting. For example, fashions uncovered to paraphrased data confirmed the next diploma of generalization, which means they might apply the data extra flexibly in numerous contexts.
One other key discovering was the connection between batch dimension and data retention. Fashions skilled with bigger batch sizes, reminiscent of 2048, demonstrated better resistance to forgetting than these skilled with smaller batch sizes of 128. The research additionally uncovered a power-law relationship between coaching steps and forgetting, displaying that factual data degrades extra shortly in fashions skilled with duplicated information. Then again, fashions uncovered to a bigger quantity of distinctive information retained this information longer, underscoring the significance of dataset high quality over sheer amount. For example, the decay fixed for duplicated information within the late pretraining stage was 0.21, in comparison with 0.16 for paraphrased information, indicating slower forgetting when the dataset was deduplicated.
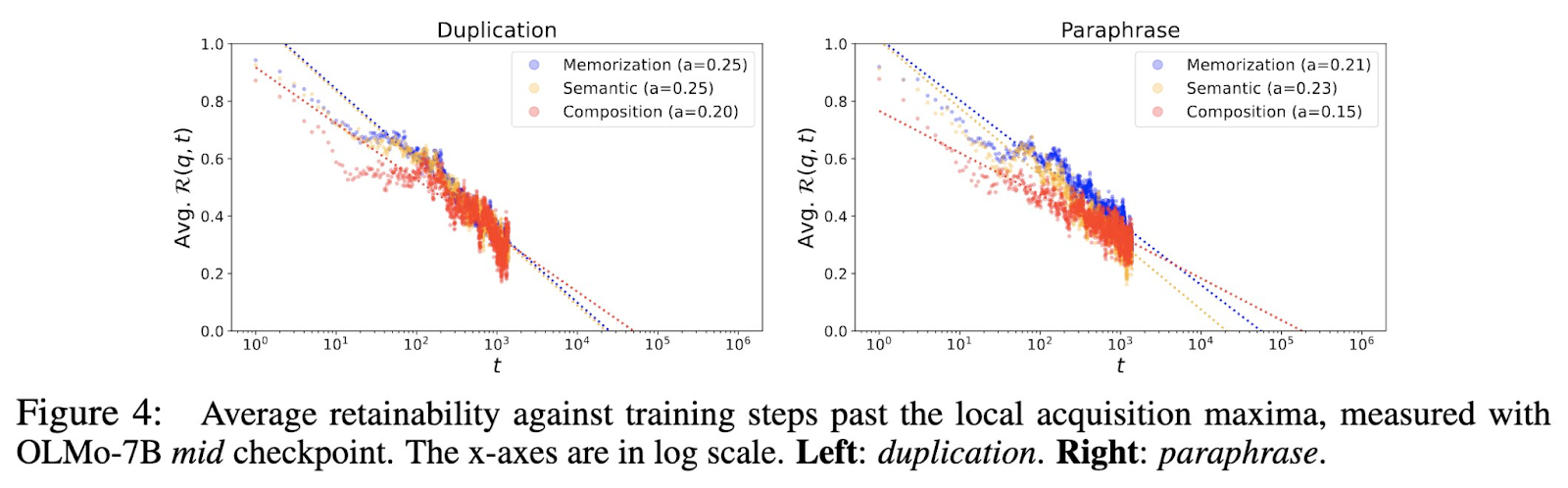
The analysis provides a promising strategy to addressing the problems of forgetting and poor generalization in LLMs. The findings recommend that optimizing batch dimension and deduplication in the course of the pretraining part can considerably enhance the retention of factual data in LLMs. These enhancements could make fashions extra dependable throughout a broader vary of duties, particularly when coping with much less frequent or long-tail data. In the end, this research gives a clearer understanding of the mechanisms behind data acquisition in LLMs, opening new avenues for future analysis to refine coaching strategies and additional improve the capabilities of those highly effective fashions.
This analysis has supplied precious insights into how massive language fashions purchase and retain data. By figuring out elements reminiscent of mannequin dimension, batch dimension, and dataset high quality, the research provides sensible options for enhancing LLM efficiency. These findings spotlight the significance of environment friendly coaching strategies and underscore the potential for optimizing LLMs to turn into much more efficient in dealing with advanced and numerous language duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 50k+ ML SubReddit
Subscribe to the fastest-growing ML Publication with over 26k+ subscribers.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


