


Net-crawled image-text datasets are important for coaching vision-language fashions, enabling developments in duties equivalent to picture captioning and visible query answering. Nevertheless, these datasets typically undergo from noise and low high quality, with inconsistent associations between pictures and textual content that restrict the capabilities of the fashions. This limitation prevents reaching sturdy and correct outcomes, significantly in cross-modal retrieval duties. Furthermore, the computational prices of dealing with such giant datasets are very prohibitive, making it crucial to have a greater methodology for coaching.
To deal with these limitations, researchers have explored artificial captions generated by multimodal giant language fashions (MLLMs) as replacements for uncooked web-crawled captions. Artificial captions enhance fashions’ efficiency, equivalent to that demonstrated by VeCLIP and Recap-DataComp-1B. Nonetheless, present approaches face vital issues: the computational prices for processing entire captions, the problem of scalability particularly with complicated architectures, and inefficiency in making use of the complete info in artificial captions.
Researchers from UC Santa Cruz and the College of Edinburgh introduce CLIPS, an enhanced vision-language coaching framework that maximizes the utility of artificial captions by two modern designs. It makes use of a method that focuses on partial artificial captions for contrastive studying. By way of the sampling of part of artificial captions, CLIPS shortens the enter token size whereas both bettering or retaining efficiency, according to ideas derived from the inverse scaling legislation noticed throughout CLIP coaching. This technique not solely improves retrieval accuracy but additionally considerably reduces computational prices. As well as, CLIPS incorporates an autoregressive caption generator that generates entire artificial captions based mostly on web-crawled captions and their corresponding pictures. This methodology follows the recaptioning mechanism present in MLLMs and ensures that synthetically captioned content material is effectively utilized, enriching the semantic alignment between picture and textual content.
The technical implementation entails preprocessing artificial captions utilizing a sub-caption masking technique, retaining roughly 32 tokens—about one or two sentences—for the textual content encoder. This strategy is coupled with a multi-positive contrastive loss, aligning each unique and shortened captions for improved effectivity and effectiveness. In parallel, the generative framework makes use of an autoregressive decoder that takes web-crawled picture attributes and captions as enter, guided by a specifically designed mixture masks to permit for optimum token interplay. The decoder produces outputs that align with full artificial captions, and this coaching is according to utilizing a generative loss perform. This coaching is carried out on in depth datasets like DataComp-1B, and evaluations are made towards benchmarks like MSCOCO and Flickr30K. Efficiency metrics embrace recall at 1 (R@1) for retrieval duties and zero-shot classification accuracy.

Evaluations present that CLIPS achieves state-of-the-art efficiency on a variety of duties. For MSCOCO, it achieves an enchancment of greater than 5% in text-to-image retrieval accuracy and greater than 3% in image-to-text retrieval in comparison with earlier approaches. Equally, on Flickr30K, the mannequin exhibits higher retrieval accuracy in each instructions in comparison with competing frameworks. The effectiveness of this framework is additional emphasised by its scalability, the place smaller fashions educated utilizing CLIPS outperform bigger fashions obtained from competing approaches. Along with retrieval duties, the incorporation of the CLIPS visible encoder inside multimodal giant language fashions markedly improves their efficacy throughout numerous benchmarks, highlighting the flexibleness and adaptableness of this coaching framework. Furthermore, ablation research present additional corroboration of the generative modeling methodology’s effectiveness, demonstrating vital enhancements in each alignment and retrieval metrics whereas preserving computational effectivity.
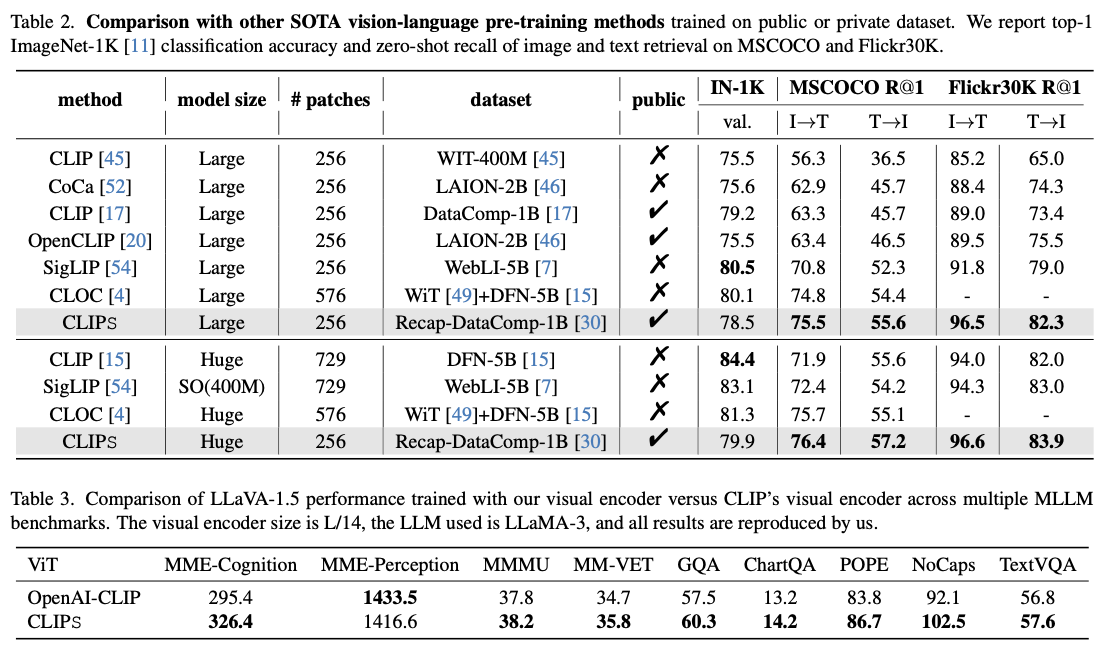
In conclusion, CLIPS transforms vision-language coaching over the challenges of earlier makes an attempt. It establishes new excessive benchmarks in cross-modal retrieval duties through the use of artificial captions and novel studying methodologies, offering scalability, computational efficacy, and improved multimodal understanding. This framework works as a serious step that has been taken in making an attempt to pursue synthetic intelligence by multimodal functions.
Try the Paper, Code, and Mannequin on Hugging Face. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Remodel proofs-of-concept into production-ready AI functions and brokers’ (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


