


Giant language fashions (LLMs) have grow to be foundational in pure language processing, particularly in functions the place understanding complicated textual content knowledge is essential. These fashions require huge quantities of computational sources as a consequence of their dimension, posing latency, reminiscence utilization, and energy consumption challenges. To make LLMs extra accessible for scalable functions, researchers have been creating strategies to scale back the computational value related to these fashions with out sacrificing accuracy and utility. This effort entails refining mannequin architectures to make use of fewer bits for knowledge illustration, aiming to make high-performance language fashions possible for large-scale deployment in numerous environments.
A persistent challenge for LLMs lies of their resource-intensive nature, which calls for important processing energy and reminiscence, notably throughout inference. Regardless of developments in mannequin optimization, the computational value related to these fashions stays a barrier for a lot of functions. This computational overhead stems primarily from the numerous parameters and operations required to course of inputs and generate outputs. Moreover, as fashions grow to be extra complicated, the chance of quantization errors will increase, resulting in potential drops in accuracy and reliability. The analysis neighborhood continues to hunt options to those effectivity challenges, specializing in decreasing the bit-width of weights and activations to mitigate useful resource calls for.
A number of strategies have been proposed to handle these effectivity points, with activation sparsity and quantization as distinguished approaches. Activation sparsity reduces the computational load by selectively deactivating low-magnitude activation entries, minimizing pointless processing. This method is especially efficient for activations with long-tailed distributions, which comprise many insignificant values that may be ignored with no substantial impression on efficiency. In the meantime, activation quantization reduces the bit-width of activations, thereby reducing the info switch and processing necessities for every computational step. Nevertheless, each strategies face limitations as a consequence of outliers inside the knowledge, which frequently have bigger magnitudes and are troublesome to deal with precisely with low-bit representations. Outlier dimensions can introduce quantization errors, decreasing mannequin accuracy and complicating the deployment of LLMs in low-resource environments.
Researchers from Microsoft Analysis and the College of Chinese language Academy of Sciences have proposed a brand new answer known as BitNet a4.8. This mannequin applies a hybrid quantization and sparsification method to attain 4-bit activations whereas retaining 1-bit weights. BitNet a4.8 addresses the effectivity problem by combining low-bit activation with strategic sparsification in intermediate states, enabling the mannequin to carry out successfully below lowered computational calls for. The mannequin retains excessive accuracy in its predictions via selective quantization, thus providing an environment friendly different for deploying LLMs at scale. The analysis crew’s method represents a big step towards making LLMs extra adaptable to environments with restricted sources.
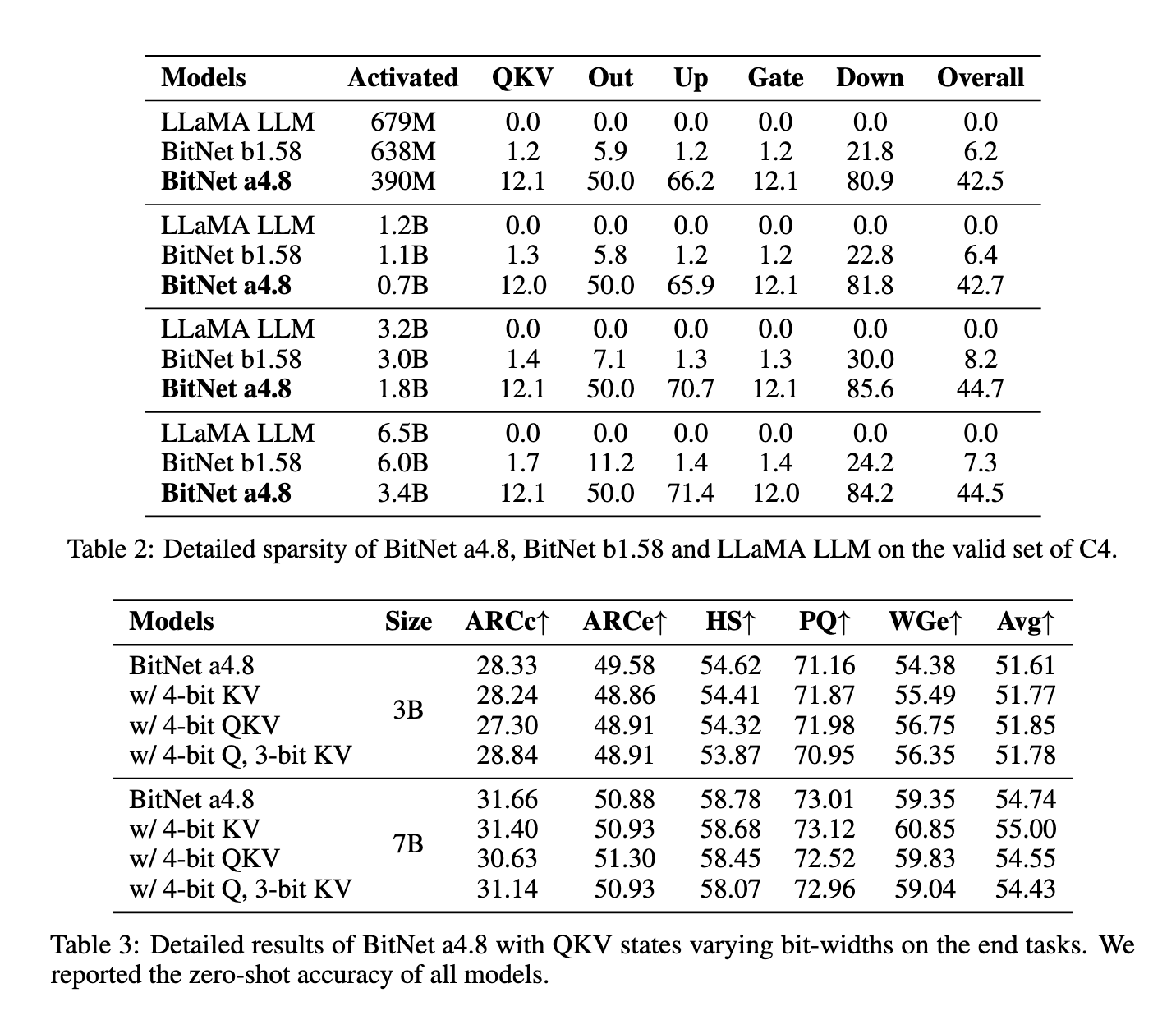
The methodology behind BitNet a4.8 entails a two-stage quantization and sparsification course of particularly designed to scale back quantization errors in outlier dimensions. First, the mannequin is skilled utilizing 8-bit activations and progressively shifted to 4-bit activations, permitting it to adapt to decrease precision with out important loss in accuracy. This two-stage coaching method allows BitNet a4.8 to make use of 4-bit activations selectively in layers much less affected by quantization errors whereas sustaining an 8-bit sparsification for intermediate states the place larger precision is critical. By tailoring the bit-width to particular layers based mostly on their sensitivity to quantization, BitNet a4.8 achieves an optimum steadiness between computational effectivity and mannequin efficiency. Moreover, the mannequin prompts solely 55% of its parameters and employs a 3-bit key-value (KV) cache, additional enhancing reminiscence effectivity and inference velocity.
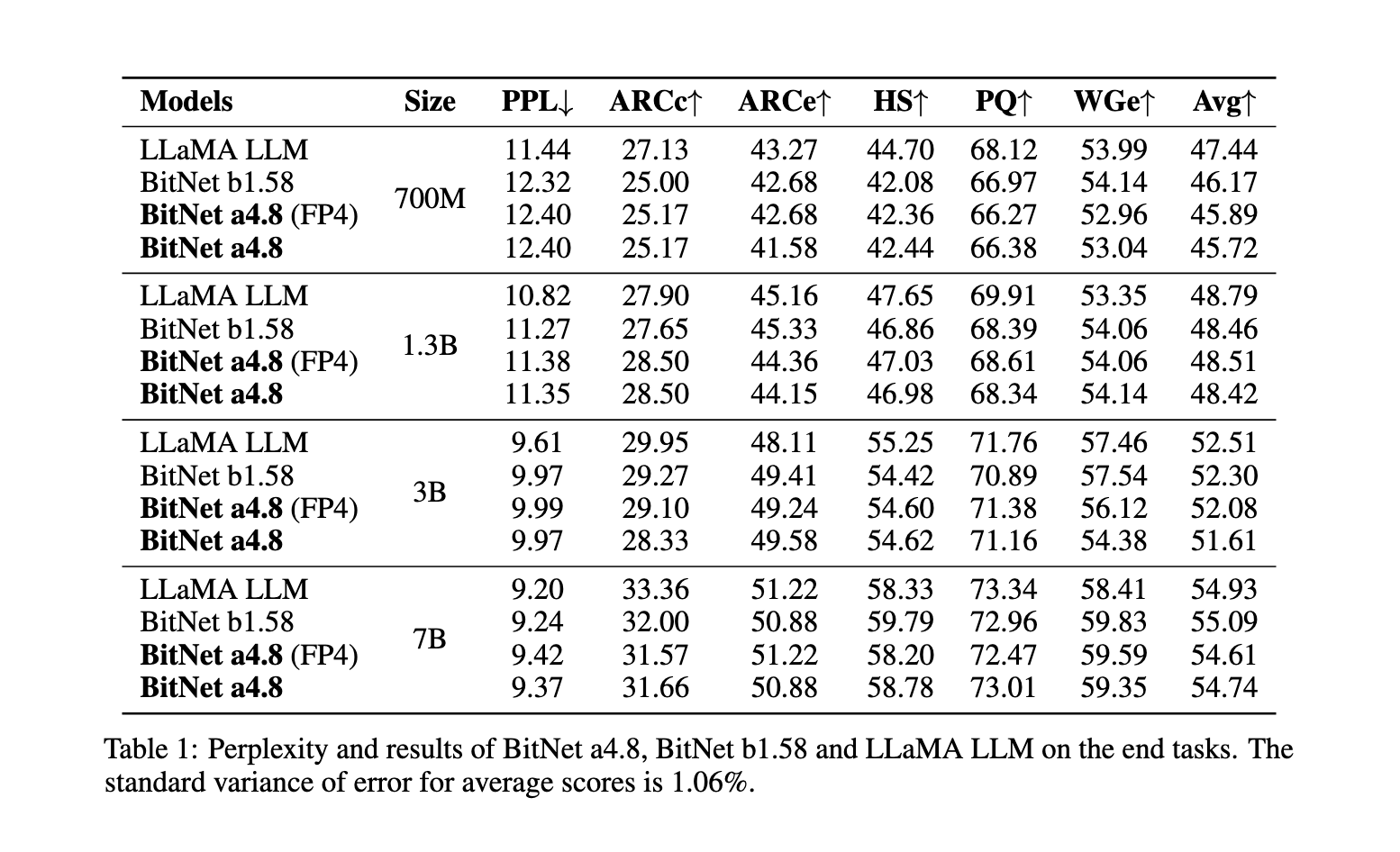
BitNet a4.8 demonstrates noteworthy efficiency enhancements throughout a number of benchmarks over its predecessor, BitNet b1.58, and different fashions, like FP16 LLaMA LLM. In a head-to-head comparability with BitNet b1.58, BitNet a4.8 maintained comparable accuracy ranges whereas providing enhanced computational effectivity. For instance, with a 7-billion parameter configuration, BitNet a4.8 achieved a perplexity rating of 9.37, carefully matching that of LLaMA LLM, and reported common accuracy charges on downstream language duties that confirmed negligible variations from the full-precision fashions. The mannequin’s structure yielded as much as 44.5% sparsity within the largest configuration examined, with 3.4 billion lively parameters in its 7-billion parameter model, considerably decreasing the computational load. Furthermore, the 3-bit KV cache enabled quicker processing speeds, additional solidifying BitNet a4.8’s functionality for environment friendly deployment with out sacrificing efficiency.
In conclusion, BitNet a4.8 offers a promising answer to the computational challenges confronted by LLMs, successfully balancing effectivity and accuracy via its hybrid quantization and sparsification methodology. This method enhances mannequin scalability and opens new avenues for deploying LLMs in resource-constrained environments. BitNet a4.8 stands out as a viable choice for large-scale language mannequin deployment by optimizing bit widths and minimizing lively parameters.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[AI Magazine/Report] Learn Our Newest Report on ‘SMALL LANGUAGE MODELS‘
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


