


Matching sufferers to acceptable scientific trials is a pivotal however extremely difficult course of in fashionable medical analysis. It includes analyzing complicated affected person medical histories and mapping them in opposition to appreciable ranges of element present in trial eligibility standards. These standards are complicated, ambiguous, and heterogeneous, making the enterprise labor-intensive and vulnerable to error, inefficient, and delaying the belief of crucial analysis progress whereas many sufferers are stored ready for experimental therapies. That is exacerbated by the requirement to scale throughout giant collections of trials, particularly in areas like oncology and uncommon ailments, the place precision and effectivity are extremely valued.
Conventional strategies of affected person trial matching are twofold: one for cohort-level recruitment is the trial-to-patient match, and the second is the patient-to-trial match with its give attention to particular person referrals and patient-centric care. Regardless of this, a number of limitations plague state-of-the-art neural embedding-based strategies. Such shortcomings contain reliance on large-scale annotated datasets which might be troublesome to acquire, with low computational effectivity and poor capabilities when it comes to real-time functions. An absence of transparency relating to the predictions additionally undermines clinician confidence. One can conclude that such imperfections name for revolutionary and explainable data-efficient methods to enhance matching efficiency in scientific environments.
To deal with these challenges, the researchers developed TrialGPT, a groundbreaking framework that leverages giant language fashions (LLMs) to streamline patient-to-trial matching. These three main components represent the composition of TrialGPT: TrialGPT-Retrieval, which filters out most irrelevant trials with the assistance of hybrid fusion retrieval and key phrases generated from affected person summaries; TrialGPT-Matching, which performs detailed analysis of the eligibility of sufferers at criterion degree, therefore offering pure language explanations and proof localization; and TrialGPT-Rating, which aggregates criterion-level outcomes into trial-level scores to prioritize and rule out. This framework integrates deep pure language understanding and technology capabilities, guaranteeing accuracy, explainability, and adaptability for analyzing unstructured medical knowledge.
The researchers assessed TrialGPT on three public datasets: SIGIR, TREC 2021, and TREC 2022, overlaying 183 artificial sufferers and over 75,000 trial annotations. The datasets comprise a variety of eligibility standards categorized into inclusion and exclusion labels. The retrieval part makes use of GPT-4 to generate context-aware key phrases from affected person notes with greater than 90% recall and lowering the search area by 94%. The matching part conducts a criterion-level evaluation which offers excessive accuracy and is supported by explainable eligibility predictions in addition to proof localization. The rating strategy combines linear and LLM-based aggregation strategies effectively to rank acceptable trials whereas discarding inappropriate ones, and therefore it’s properly able to getting used at scale in real-world functions.
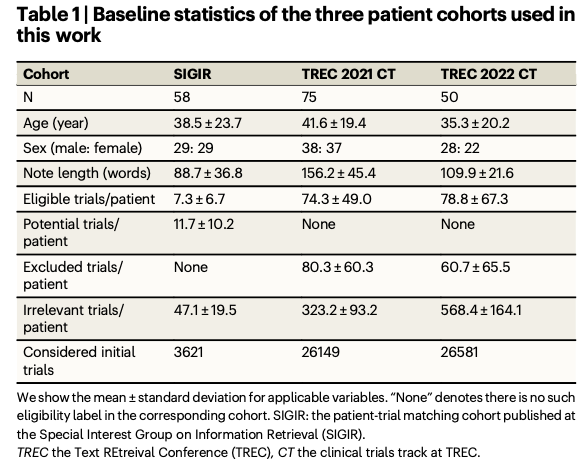
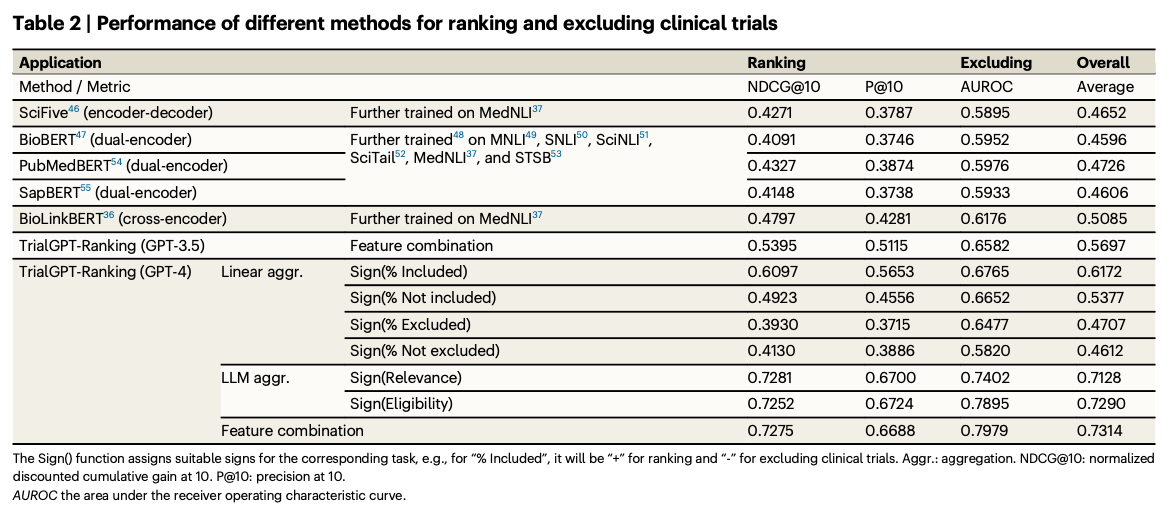
The trialGPT mannequin carried out robustly on all related benchmarks, fixing each retrieval and matching issues. The retrieval module narrowed down giant collections of trials whereas nonetheless sustaining good recall for related choices. The matching module supplied criterion-level predictions with accuracy equal to human specialists along with pure language explanations and the proof on the precise sentence degree. Its rating characteristic outperformed all different strategies when it comes to rating precision and exclusion effectiveness in figuring out and rating eligible trials. Affected person-trial matching workflow effectivity was additional improved by TrialGPT, resulting in a lower in screening time by over 42%, demonstrating its sensible worth for scientific trial recruitment.
TrialGPT illustrates a radical resolution to the issues of patient-trial matching: scalability, accuracy, and transparency in a novel utilization software of LLMs. Its modularity overcomes key limitations in standard approaches, accelerating affected person recruitment processes and streamlining scientific analysis whereas producing higher affected person outcomes. With superior language understanding built-in with explainable outputs, TrialGPT illustrates a brand new scale for personalised and environment friendly trials. Future work might contain the mixing of multi-modal knowledge sources and the variation of open-source LLMs to varied functions for real-world validation.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Digital GenAI Convention ft. Meta, Mistral, Salesforce, Harvey AI & extra. Be part of us on Dec eleventh for this free digital occasion to study what it takes to construct massive with small fashions from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and extra.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


