


Massive Language Fashions (LLMs) have gained important consideration lately, however bettering their efficiency stays a difficult activity. Researchers are striving to boost already-trained fashions by creating extra, focused coaching information that addresses particular weaknesses. This course of, generally known as instruction tuning and alignment, has proven promise in enhancing mannequin capabilities throughout varied duties. Nevertheless, the present strategy to mannequin enchancment is closely reliant on human intervention. Specialists should manually establish mannequin weaknesses via evaluations, create information primarily based on instinct and heuristics, practice up to date fashions, and revise the info iteratively. This labour-intensive and repetitive course of highlights the pressing want for automated information technology brokers that may streamline the creation of educating information for scholar fashions, both partially or fully.
Current makes an attempt to beat the challenges in bettering language fashions have primarily centered on surroundings technology and studying from generated information. In coaching surroundings technology, researchers have explored unsupervised surroundings design (UED) to progressively improve problem primarily based on agent scores in easy video games. Meta-learning approaches have been launched to create studying environments for steady management. Imaginative and prescient-language navigation (VLN) has seen efforts to reinforce visible variety utilizing picture technology fashions. Recreation environments have additionally been generated to coach reinforcement studying brokers and measure their generalization.
Studying from generated information has centred round data distillation, the place outputs from bigger fashions are used to coach smaller ones. Symbolic distillation has change into more and more widespread within the context of LLMs, with textual content generated from giant fashions used to coach smaller ones in instruction tuning or distilling chain-of-thought reasoning. Nevertheless, these approaches sometimes depend on fastened datasets or generate information all of sudden, in contrast to the dynamic, feedback-based information technology in DATAENVGYM.
Researchers from UNC Chapel Hill current DATAENVGYM which emerges as a state-of-the-art testbed for growing and evaluating autonomous information technology brokers. This revolutionary platform frames the duty of bettering language fashions as an iterative interplay between a instructor agent and a scholar mannequin. The instructor agent generates focused coaching information primarily based on the coed’s weaknesses, aiming to boost the mannequin’s efficiency over a number of rounds. DATAENVGYM provides modular environments that allow thorough testing of knowledge technology brokers, mimicking the way in which sport environments assess game-playing brokers in reinforcement studying. The platform gives complete modules for information technology, coaching, and analysis, with the last word purpose of measuring enchancment within the scholar mannequin. DATAENVGYM’s versatility permits it to assist numerous brokers throughout varied duties, together with multimodal and text-only challenges, making it a robust device for advancing the sphere of language mannequin enchancment.
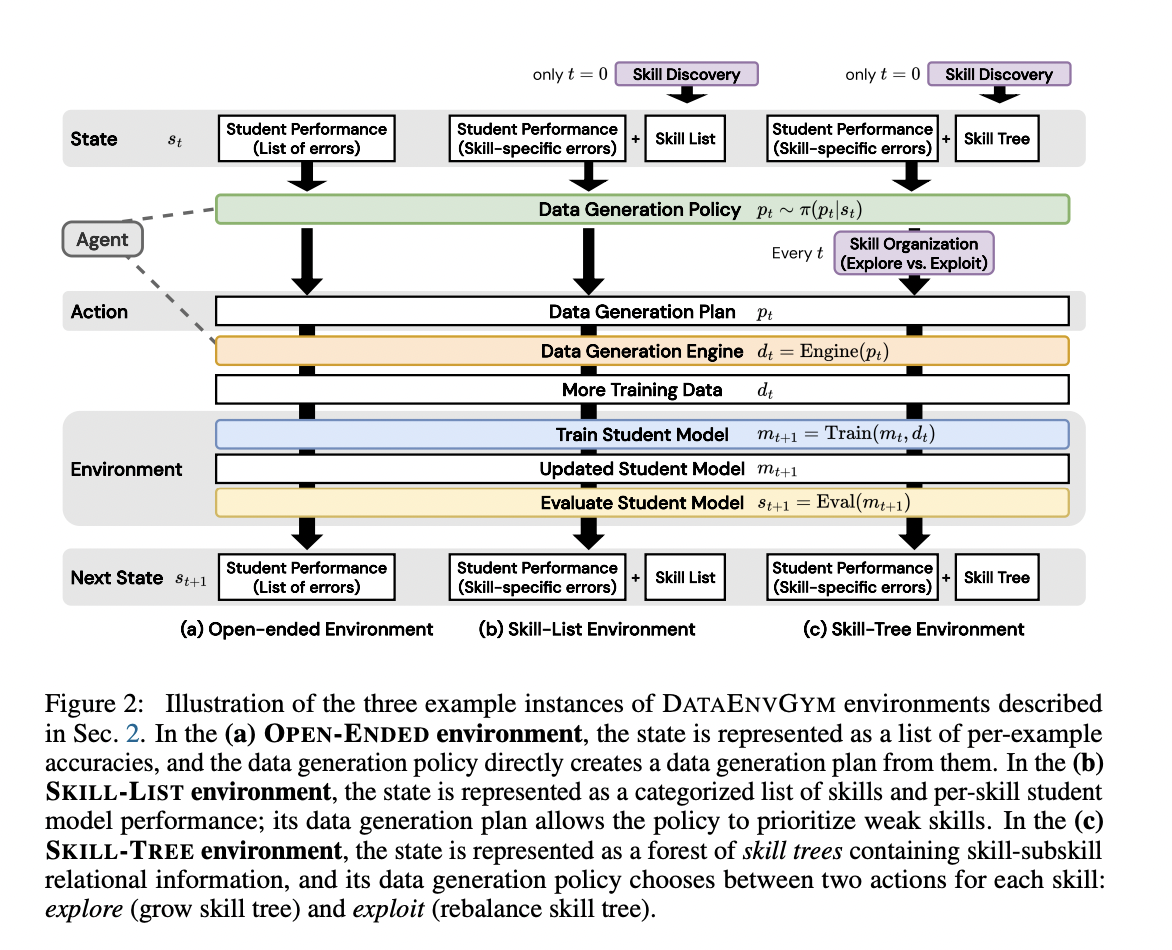
DATAENVGYM provides three distinct environment-agent pairs, every offering totally different ranges of construction and interpretability to the info technology course of. The OPEN-ENDED surroundings presents the best construction, with the state represented as a listing of evaluated predictions from the coed mannequin. The agent should instantly infer and generate information factors primarily based on these errors.
The SKILL-LIST surroundings introduces a skill-based strategy, the place the state illustration consists of scholar efficiency on mechanically induced expertise. This permits for extra focused information technology, addressing particular weaknesses within the mannequin’s skillset.
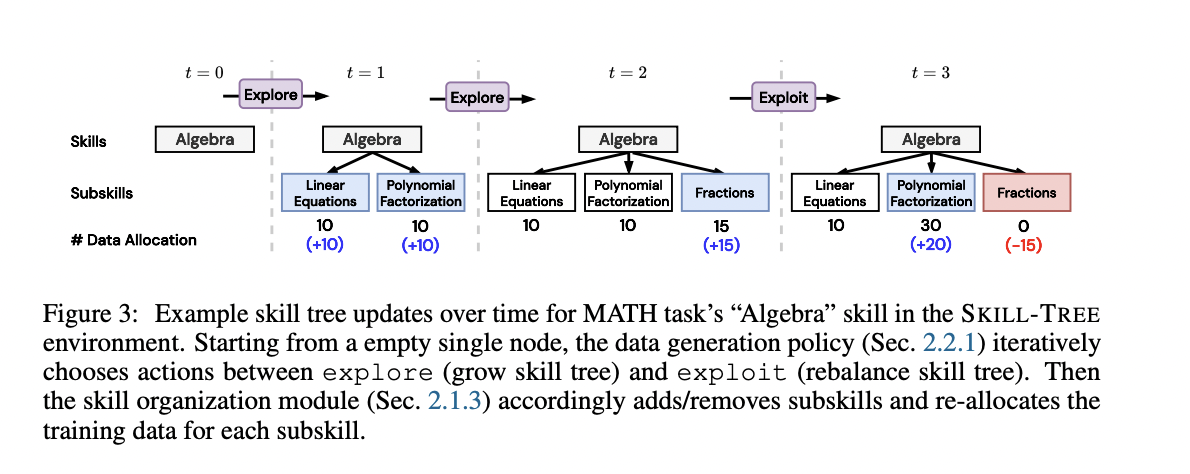
The SKILL-TREE surroundings additional refines the method by implementing a hierarchical ability forest. It separates information technology from information management, constraining the motion area to both exploiting present expertise by rebalancing the ability tree or exploring new subskills. This construction gives extra scaffolding for the agent and enhances interpretability.
Every surroundings incorporates modules for the coed mannequin, coach, and evaluator. The brokers include an information technology coverage and an information technology engine, which adapt to the particular surroundings’s affordances. This modular design permits for versatile testing and improvement of knowledge technology methods throughout varied duties, together with arithmetic, visible query answering, and programming.
DATAENVGYM’s effectiveness is demonstrated via complete evaluation throughout varied dimensions. The platform exhibits constant enchancment in scholar mannequin efficiency throughout totally different duties and environments. On common, college students improved by 4.43% on GQA, 4.82% on MATH, and 1.80% on LiveCodeBench after coaching in DATAENVGYM environments.
The research reveals that skill-based studying within the SKILL-TREE surroundings enhances general efficiency, with essentially the most important enhancements noticed in questions of medium problem and frequency. This implies a “candy spot” for efficient studying, aligning with theories of human studying resembling Vygotsky’s Zone of Proximal Improvement.
Iterative coaching dynamics present that college students typically enhance throughout iterations, indicating that the baseline brokers efficiently uncover new, helpful information factors at every step. The standard of the instructor mannequin considerably impacts the effectiveness of the generated information, with stronger fashions like GPT-4o outperforming weaker ones like GPT-4o-mini.
Importantly, the analysis demonstrates that insurance policies using state info (“With State”) constantly outperform these with out (“No State”) throughout all environments. The structured strategy of the SKILL-TREE surroundings proves significantly strong for sure duties like GQA. These findings underscore the significance of state info and surroundings construction within the educating course of, whereas additionally highlighting the platform’s flexibility in testing varied elements and methods for information technology and mannequin enchancment.



DATAENVGYM represents a big development within the discipline of language mannequin enchancment. By offering a structured testbed for growing and evaluating information technology brokers, it provides researchers a robust device to discover new methods for enhancing mannequin efficiency. The platform’s success throughout numerous domains demonstrates its versatility and potential affect. The modular design of DATAENVGYM permits for versatile testing of assorted elements and methods, paving the way in which for future improvements in information technology, ability discovery, and suggestions mechanisms. As the sphere continues to evolve, DATAENVGYM stands as a vital useful resource for researchers in search of to push the boundaries of language mannequin capabilities via automated, focused coaching information technology.
Take a look at the Paper, GitHub, and Undertaking. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Overlook to hitch our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Information Retrieval Convention (Promoted)
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.

